 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning
Mar 27, 2025Imitation learning is a popular method for teaching robots new behaviors. However, most existing methods focus on teaching short, isolated skills rather than long, multi-step tasks. To bridge this gap, imitation learning algorithms must not only learn individual skills but also an abstract understanding of how to sequence these skills to perform extended tasks effectively. This paper addresses this challenge by proposing a neuro-symbolic imitation learning framework. Using task demonstrations, the system first learns a symbolic representation that abstracts the low-level state-action space. The learned representation decomposes a task into easier subtasks and allows the system to leverage symbolic planning to generate abstract plans. Subsequently, the system utilizes this task decomposition to learn a set of neural skills capable of refining abstract plans into actionable robot commands. Experimental results in three simulated robotic environments demonstrate that, compared to baselines, our neuro-symbolic approach increases data efficiency, improves generalization capabilities, and facilitates interpretability.
Model-Based Quality-Diversity Search for Efficient Robot Learning
Aug 11, 2020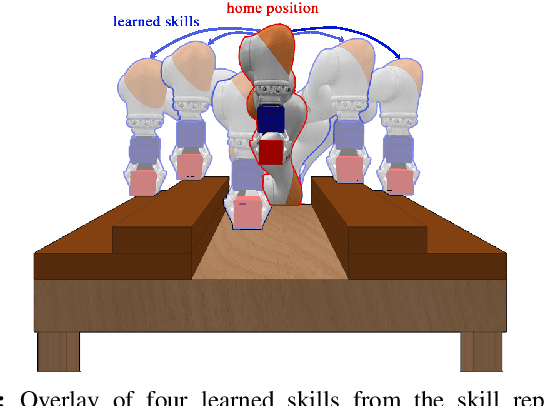
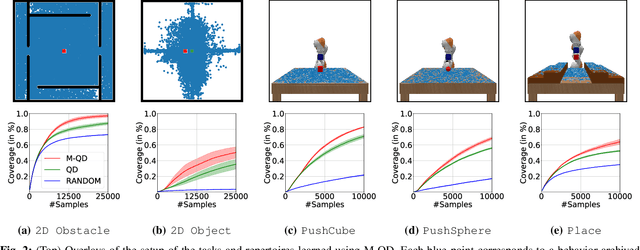
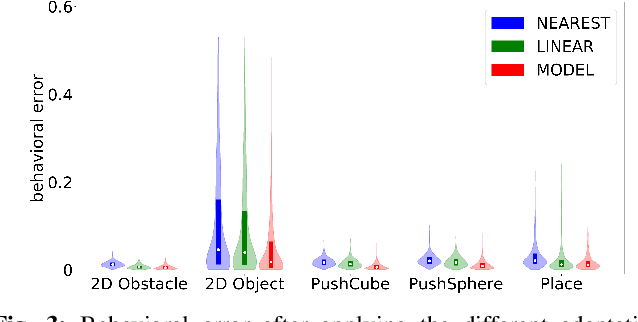
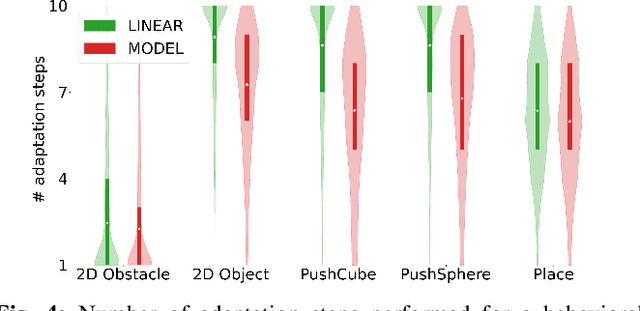
Despite recent progress in robot learning, it still remains a challenge to program a robot to deal with open-ended object manipulation tasks. One approach that was recently used to autonomously generate a repertoire of diverse skills is a novelty based Quality-Diversity~(QD) algorithm. However, as most evolutionary algorithms, QD suffers from sample-inefficiency and, thus, it is challenging to apply it in real-world scenarios. This paper tackles this problem by integrating a neural network that predicts the behavior of the perturbed parameters into a novelty based QD algorithm. In the proposed Model-based Quality-Diversity search (M-QD), the network is trained concurrently to the repertoire and is used to avoid executing unpromising actions in the novelty search process. Furthermore, it is used to adapt the skills of the final repertoire in order to generalize the skills to different scenarios. Our experiments show that enhancing a QD algorithm with such a forward model improves the sample-efficiency and performance of the evolutionary process and the skill adaptation.