 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Acceleration Reinforcement Learning for Real-World Juggling with Binary Rewards
Paper and Code
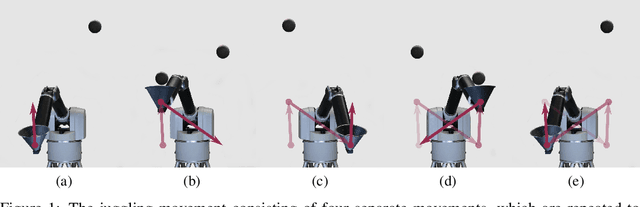

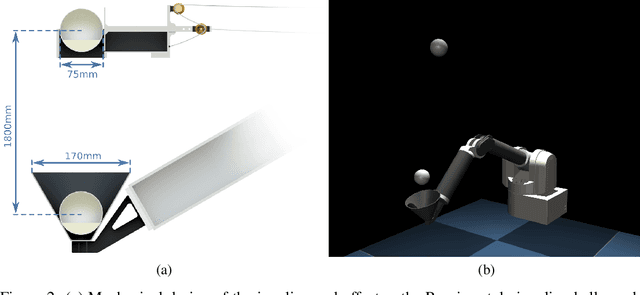
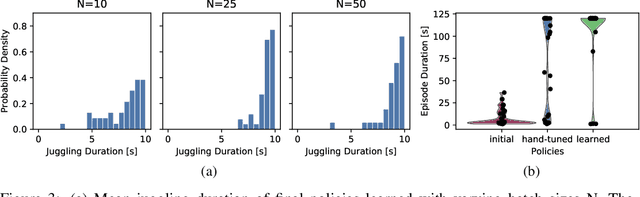
Robots that can learn in the physical world will be important to en-able robots to escape their stiff and pre-programmed movements. For dynamic high-acceleration tasks, such as juggling, learning in the real-world is particularly challenging as one must push the limits of the robot and its actuation without harming the system, amplifying the necessity of sample efficiency and safety for robot learning algorithms. In contrast to prior work which mainly focuses on the learning algorithm, we propose a learning system, that directly incorporates these requirements in the design of the policy representation, initialization, and optimization. We demonstrate that this system enables the high-speed Barrett WAM manipulator to learn juggling two balls from 56 minutes of experience with a binary reward signal. The final policy juggles continuously for up to 33 minutes or about 4500 repeated catches. The videos documenting the learning process and the evaluation can be found at https://sites.google.com/view/jugglingbot