 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning using Guided Observability
Apr 22, 2021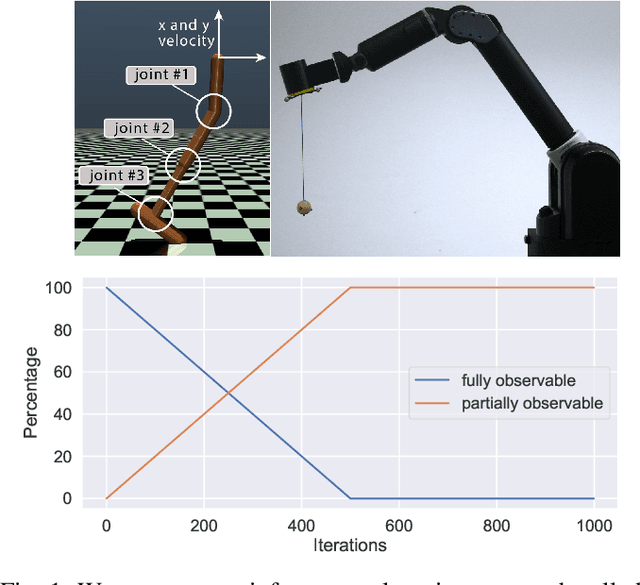

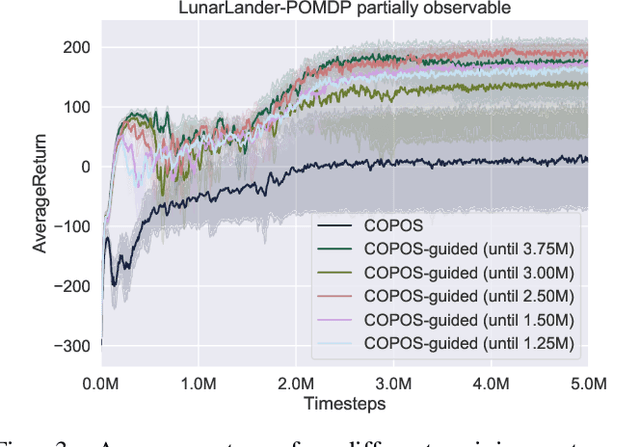
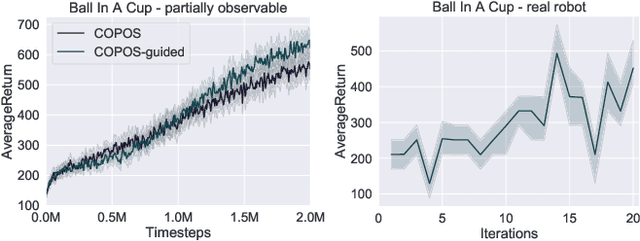
Due to recent breakthroughs, reinforcement learning (RL) has demonstrated impressive performance in challenging sequential decision-making problems. However, an open question is how to make RL cope with partial observability which is prevalent in many real-world problems. Contrary to contemporary RL approaches, which focus mostly on improved memory representations or strong assumptions about the type of partial observability, we propose a simple but efficient approach that can be applied together with a wide variety of RL methods. Our main insight is that smoothly transitioning from full observability to partial observability during the training process yields a high performance policy. The approach, called partially observable guided reinforcement learning (PO-GRL), allows to utilize full state information during policy optimization without compromising the optimality of the final policy. A comprehensive evaluation in discrete partially observableMarkov decision process (POMDP) benchmark problems and continuous partially observable MuJoCo and OpenAI gym tasks shows that PO-GRL improves performance. Finally, we demonstrate PO-GRL in the ball-in-the-cup task on a real Barrett WAM robot under partial observability.