 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive AI-based Decentralized Resource Management in the Cloud-Edge Continuum
Jan 27, 2025The increasing complexity of application requirements and the dynamic nature of the Cloud-Edge Continuum present significant challenges for efficient resource management. These challenges stem from the ever-changing infrastructure, which is characterized by additions, removals, and reconfigurations of nodes and links, as well as the variability of application workloads. Traditional centralized approaches struggle to adapt to these changes due to their static nature, while decentralized solutions face challenges such as limited global visibility and coordination overhead. This paper proposes a hybrid decentralized framework for dynamic application placement and resource management. The framework utilizes Graph Neural Networks (GNNs) to embed resource and application states, enabling comprehensive representation and efficient decision-making. It employs a collaborative multi-agent reinforcement learning (MARL) approach, where local agents optimize resource management in their neighborhoods and a global orchestrator ensures system-wide coordination. By combining decentralized application placement with centralized oversight, our framework addresses the scalability, adaptability, and accuracy challenges inherent in the Cloud-Edge Continuum. This work contributes to the development of decentralized application placement strategies, the integration of GNN embeddings, and collaborative MARL systems, providing a foundation for efficient, adaptive and scalable resource management.
Calibration of Continual Learning Models
Apr 12, 2024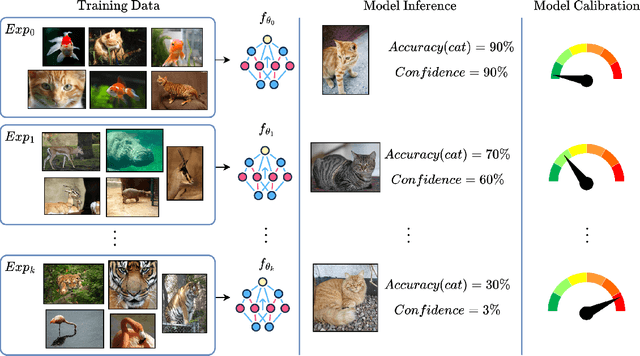
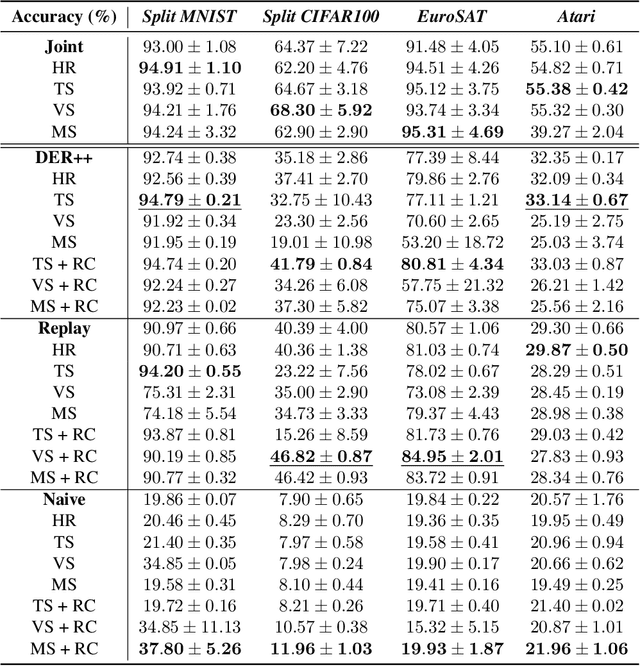
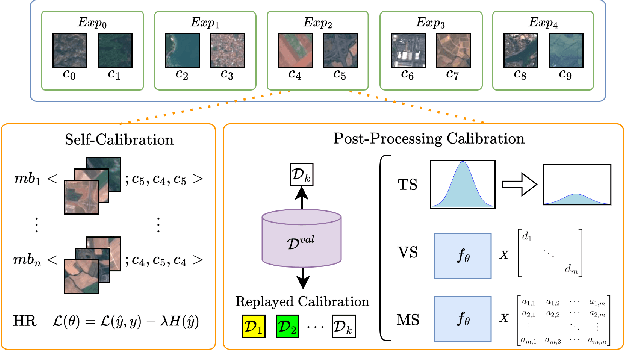
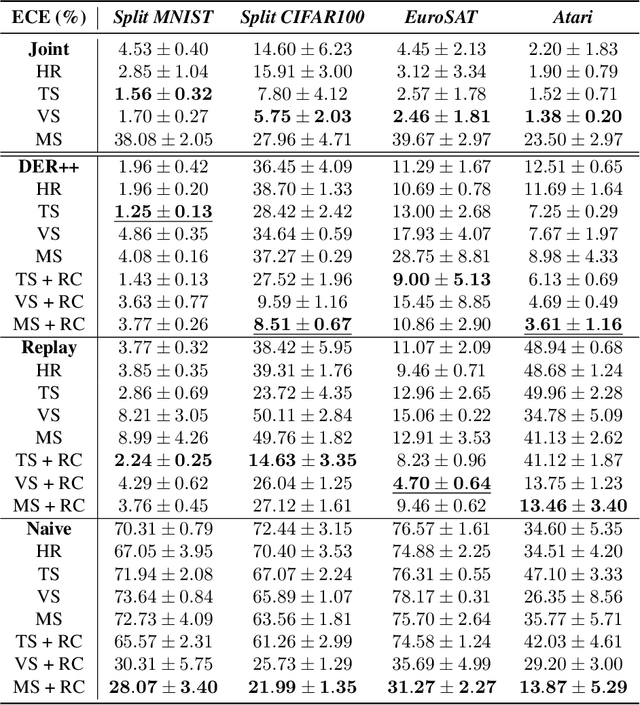
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
Continual Policy Distillation of Reinforcement Learning-based Controllers for Soft Robotic In-Hand Manipulation
Apr 05, 2024Dexterous manipulation, often facilitated by multi-fingered robotic hands, holds solid impact for real-world applications. Soft robotic hands, due to their compliant nature, offer flexibility and adaptability during object grasping and manipulation. Yet, benefits come with challenges, particularly in the control development for finger coordination. Reinforcement Learning (RL) can be employed to train object-specific in-hand manipulation policies, but limiting adaptability and generalizability. We introduce a Continual Policy Distillation (CPD) framework to acquire a versatile controller for in-hand manipulation, to rotate different objects in shape and size within a four-fingered soft gripper. The framework leverages Policy Distillation (PD) to transfer knowledge from expert policies to a continually evolving student policy network. Exemplar-based rehearsal methods are then integrated to mitigate catastrophic forgetting and enhance generalization. The performance of the CPD framework over various replay strategies demonstrates its effectiveness in consolidating knowledge from multiple experts and achieving versatile and adaptive behaviours for in-hand manipulation tasks.