 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy memory encoding explains negative polarity illusions
Jun 03, 2026A sentence like "The authors that no critics recommended have ever received acknowledgment for a best-selling novel" is sometimes rated as acceptable even though, strictly speaking, it is ungrammatical because the negative polarity word "ever" is not licensed where it is. This behavioral effect is sometimes called a "negative polarity illusion". Here we propose that the lossy context surprisal theory of Hahn et al. (2022) -- whereby people have an imperfect encoding of complex sentences -- might explain this effect. We hypothesize that people have poor memory representation of the determiners in the main-clause and embedded-clause subjects and could entertain a determiner exchange that licenses ever. We propose that more similar determiners in those positions would trigger stronger illusion effects. Acceptability judgment tasks with six novel determiner pairs (e.g., "few" and "many", "few" and "most") support our proposal, showing, specifically, that a novel sentence, "Many authors that few critics recommended have ever received acknowledgment for a best-selling novel", triggered a much stronger illusion than the canonical one even without time pressure. These results offer further support for the suggestion that human language processing is imperfect and resource-rational: in face of working memory limitations, humans rationally reconstruct what is most likely from noisy linguistic input to facilitate downstream processing.
Readers make targeted regressions to plausible errors in reanalysis of "noisy-channel garden-path" sentences
May 18, 2026A key question in psycholinguistics is how inferences about the meaning of linguistic input unfold incrementally a comprehender's mind. In this work, we study reading dynamics for ``noisy-channel garden-path'' sentences, which temporarily appear well-formed but feature late-appearing violations of expectation that can be resolved not by inferring an alternative syntactic structure, but by inferring the presence of an error. We find evidence for targeted regressions -- eye movements towards regions that are promising loci of possible errors in light of later-arriving information, showing patterns consistent with the posterior inferences of a model of noisy-channel processing with reanalysis. We discuss the implications of these findings for theories of noisy-channel language comprehension and information-theoretic explanations of reading dynamics.
Can Language Models Be Tricked by Language Illusions? Easier with Syntax, Harder with Semantics
Nov 02, 2023
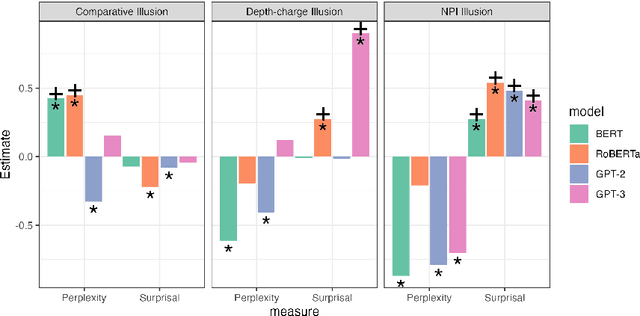
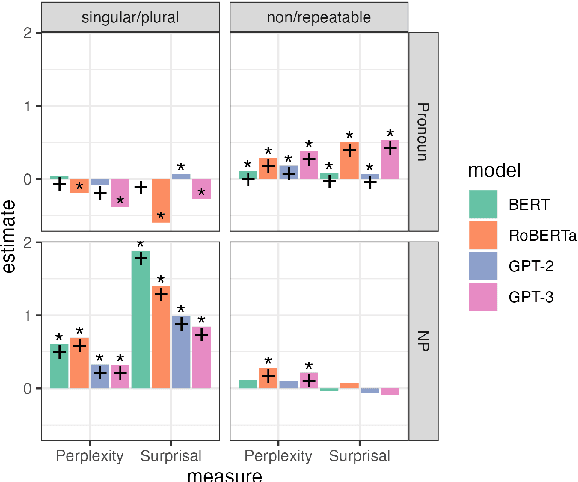
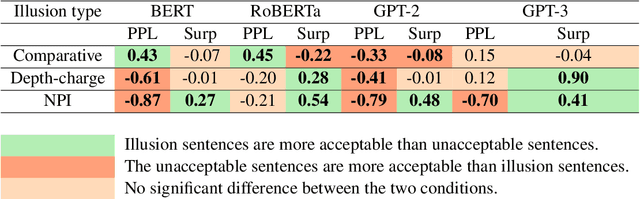
Language models (LMs) have been argued to overlap substantially with human beings in grammaticality judgment tasks. But when humans systematically make errors in language processing, should we expect LMs to behave like cognitive models of language and mimic human behavior? We answer this question by investigating LMs' more subtle judgments associated with "language illusions" -- sentences that are vague in meaning, implausible, or ungrammatical but receive unexpectedly high acceptability judgments by humans. We looked at three illusions: the comparative illusion (e.g. "More people have been to Russia than I have"), the depth-charge illusion (e.g. "No head injury is too trivial to be ignored"), and the negative polarity item (NPI) illusion (e.g. "The hunter who no villager believed to be trustworthy will ever shoot a bear"). We found that probabilities represented by LMs were more likely to align with human judgments of being "tricked" by the NPI illusion which examines a structural dependency, compared to the comparative and the depth-charge illusions which require sophisticated semantic understanding. No single LM or metric yielded results that are entirely consistent with human behavior. Ultimately, we show that LMs are limited both in their construal as cognitive models of human language processing and in their capacity to recognize nuanced but critical information in complicated language materials.
A fine-grained comparison of pragmatic language understanding in humans and language models
Dec 13, 2022Pragmatics is an essential part of communication, but it remains unclear what mechanisms underlie human pragmatic communication and whether NLP systems capture pragmatic language understanding. To investigate both these questions, we perform a fine-grained comparison of language models and humans on seven pragmatic phenomena, using zero-shot prompting on an expert-curated set of English materials. We ask whether models (1) select pragmatic interpretations of speaker utterances, (2) make similar error patterns as humans, and (3) use similar linguistic cues as humans to solve the tasks. We find that the largest models achieve high accuracy and match human error patterns: within incorrect responses, models favor the literal interpretation of an utterance over heuristic-based distractors. We also find evidence that models and humans are sensitive to similar linguistic cues. Our results suggest that even paradigmatic pragmatic phenomena may be solved without explicit representations of other agents' mental states, and that artificial models can be used to gain mechanistic insights into human pragmatic processing.
Grammatical cues are largely, but not completely, redundant with word meanings in natural language
Jan 30, 2022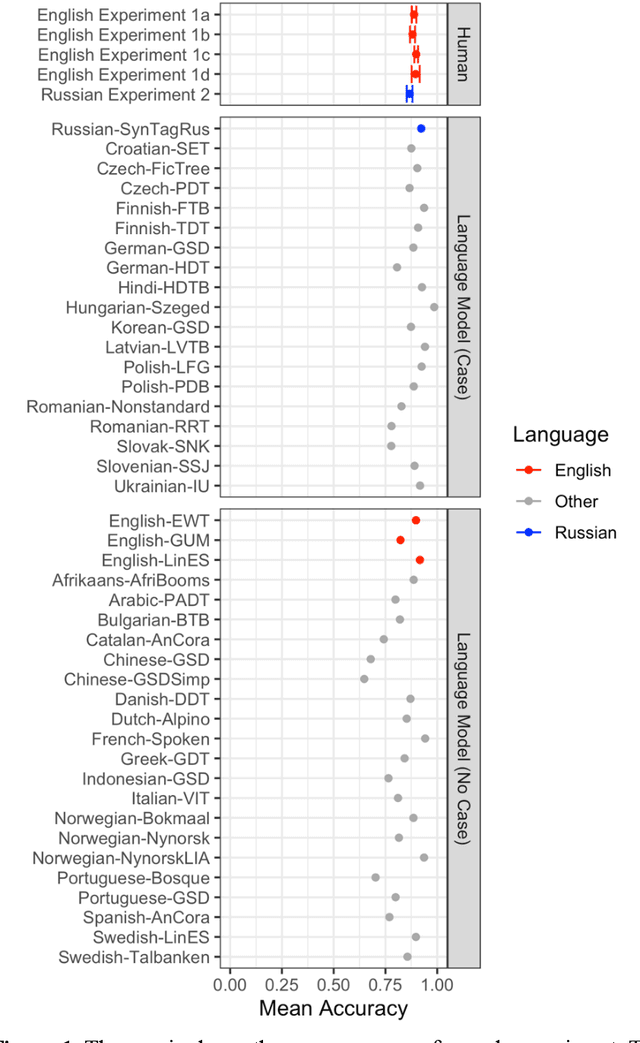
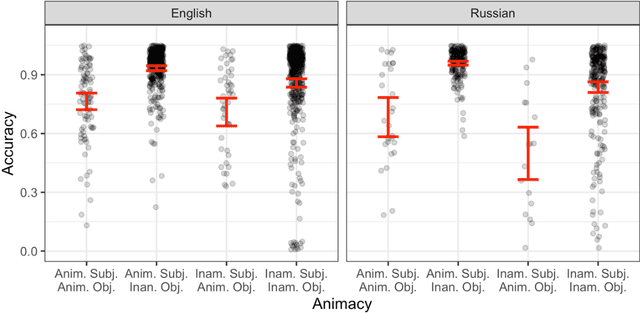
The combinatorial power of language has historically been argued to be enabled by syntax: rules that allow words to combine hierarchically to convey complex meanings. But how important are these rules in practice? We performed a broad-coverage cross-linguistic investigation of the importance of grammatical cues for interpretation. First, English and Russian speakers (n=484) were presented with subjects, verbs, and objects (in random order and with morphological markings removed) extracted from naturally occurring sentences, and were asked to identify which noun is the agent of the action. Accuracy was high in both languages (~89% in English, ~87% in Russian), suggesting that word meanings strongly constrain who is doing what to whom. Next, we trained a neural network machine classifier on a similar task: predicting which nominal in a subject-verb-object triad is the subject. Across 30 languages from eight language families, performance was consistently high: a median accuracy of 87%, comparable to the accuracy observed in the human experiments. These results have ramifications for any theory of why languages look the way that they do, and seemingly pose a challenge for efficiency-based theories: why have grammatical cues for argument role if they only have utility in 10-15% of sentences? We suggest that although grammatical cues are not usually necessary, they are useful in the rare cases when the intended meaning cannot be inferred from the words alone, including descriptions of human interactions, where roles are often reversible (e.g., Ray helped Lu/Lu helped Ray), and expressing non-canonical meanings (e.g., the man bit the dog). Importantly, for such cues to be useful, they have to be reliable, which means being ubiquitously used, including when they are not needed.
The Natural Stories Corpus
Aug 18, 2017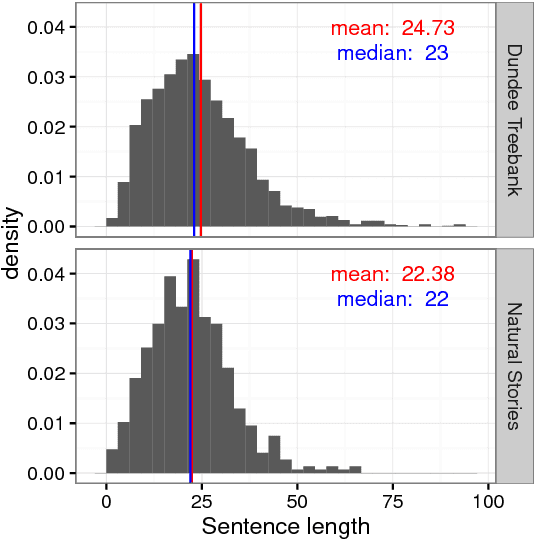

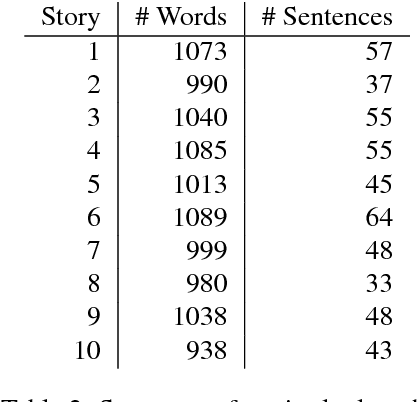
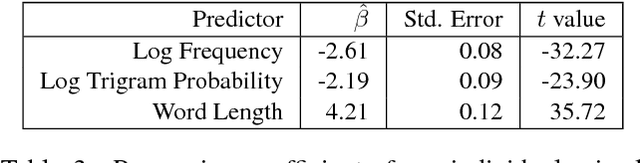
It is now a common practice to compare models of human language processing by predicting participant reactions (such as reading times) to corpora consisting of rich naturalistic linguistic materials. However, many of the corpora used in these studies are based on naturalistic text and thus do not contain many of the low-frequency syntactic constructions that are often required to distinguish processing theories. Here we describe a new corpus consisting of English texts edited to contain many low-frequency syntactic constructions while still sounding fluent to native speakers. The corpus is annotated with hand-corrected parse trees and includes self-paced reading time data. Here we give an overview of the content of the corpus and release the data.
Response to Liu, Xu, and Liang and Ferrer-i-Cancho and Gómez-Rodríguez on Dependency Length Minimization
Oct 01, 2015
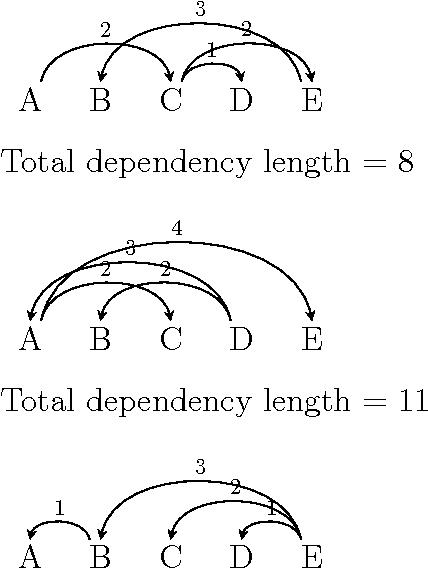
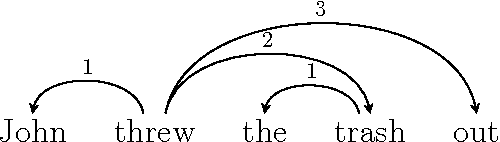

We address recent criticisms (Liu et al., 2015; Ferrer-i-Cancho and G\'omez-Rodr\'iguez, 2015) of our work on empirical evidence of dependency length minimization across languages (Futrell et al., 2015). First, we acknowledge error in failing to acknowledge Liu (2008)'s previous work on corpora of 20 languages with similar aims. A correction will appear in PNAS. Nevertheless, we argue that our work provides novel, strong evidence for dependency length minimization as a universal quantitative property of languages, beyond this previous work, because it provides baselines which focus on word order preferences. Second, we argue that our choices of baselines were appropriate because they control for alternative theories.
Information content versus word length in natural language: A reply to Ferrer-i-Cancho and Moscoso del Prado Martin [arXiv:1209.1751]
Jul 25, 2013Recently, Ferrer i Cancho and Moscoso del Prado Martin [arXiv:1209.1751] argued that an observed linear relationship between word length and average surprisal (Piantadosi, Tily, & Gibson, 2011) is not evidence for communicative efficiency in human language. We discuss several shortcomings of their approach and critique: their model critically rests on inaccurate assumptions, is incapable of explaining key surprisal patterns in language, and is incompatible with recent behavioral results. More generally, we argue that statistical models must not critically rely on assumptions that are incompatible with the real system under study.