 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Be Tricked by Language Illusions? Easier with Syntax, Harder with Semantics
Paper and Code

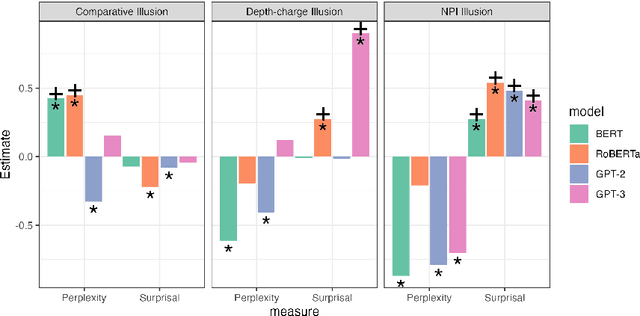
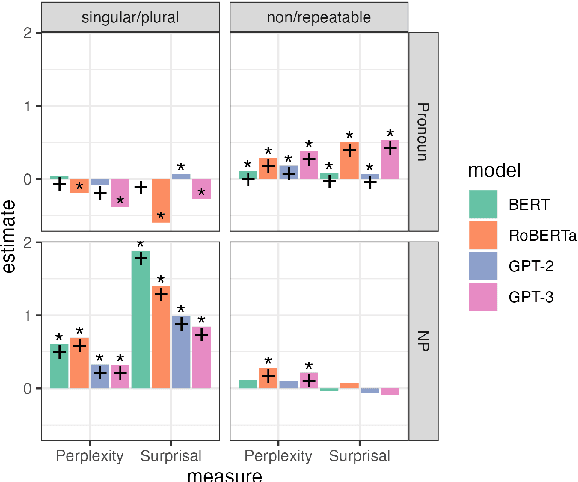
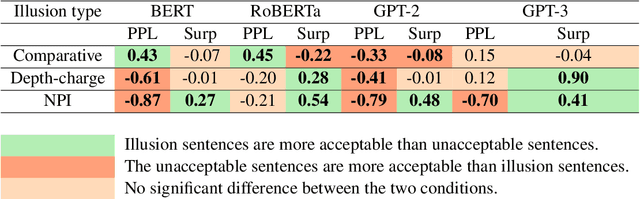
Language models (LMs) have been argued to overlap substantially with human beings in grammaticality judgment tasks. But when humans systematically make errors in language processing, should we expect LMs to behave like cognitive models of language and mimic human behavior? We answer this question by investigating LMs' more subtle judgments associated with "language illusions" -- sentences that are vague in meaning, implausible, or ungrammatical but receive unexpectedly high acceptability judgments by humans. We looked at three illusions: the comparative illusion (e.g. "More people have been to Russia than I have"), the depth-charge illusion (e.g. "No head injury is too trivial to be ignored"), and the negative polarity item (NPI) illusion (e.g. "The hunter who no villager believed to be trustworthy will ever shoot a bear"). We found that probabilities represented by LMs were more likely to align with human judgments of being "tricked" by the NPI illusion which examines a structural dependency, compared to the comparative and the depth-charge illusions which require sophisticated semantic understanding. No single LM or metric yielded results that are entirely consistent with human behavior. Ultimately, we show that LMs are limited both in their construal as cognitive models of human language processing and in their capacity to recognize nuanced but critical information in complicated language materials.