 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Channel Sounding and Communication: Requirements, Architecture, Challenges, and Key Technologies
Mar 16, 2026Channel models are essential for the design, evaluation, and optimization of wireless communication systems. The emerging space-air-ground-sea integrated network (SAGSIN), characterized by diverse service applications and extended-spectrum operations, places even greater demands on highly accurate channel models. However, conventional channel sounding is limited by generalized measurement campaigns, inadequate cross-band consistency, and insufficient real-time adaptability, making it unable to meet the needs of SAGSIN for scenario-specific and high-precision channel modeling. To address this challenge, we propose a novel technological framework, termed integrated channel sounding and communication (ICSC). By deeply integrating sounding and communication, the ICSC enables efficient and real-time acquisition of dynamic channel characteristics during communication processes, supporting fine-grained site- and scenario-specific measurements. Furthermore, leveraging artificial intelligence techniques, ICSC can identify channel conditions and adapt waveform parameters in real-time according to scenario variations, which in turn enhances communication performance. This article first introduces the fundamental principles of the ICSC framework, elaborates on its core concepts and key advantages, and demonstrates its feasibility through the development of an integrated verification system (IVS). Subsequently, the potential applications and opportunities of the ICSC are analyzed in depth, followed by a discussion of its future development directions and remaining challenges.
SynthRM: A Synthetic Data Platform for Vision-Aided Mobile System Simulation
Jan 27, 2026Vision-aided wireless sensing is emerging as a cornerstone of 6G mobile computing. While data-driven approaches have advanced rapidly, establishing a precise geometric correspondence between ego-centric visual data and radio propagation remains a challenge. Existing paradigms typically either associate 2D topology maps and auxiliary information with radio maps, or provide 3D perspective views limited by sparse radio data. This spatial representation flattens the complex vertical interactions such as occlusion and diffraction that govern signal behavior in urban environments, rendering the task of cross-view signal inference mathematically ill-posed. To resolve this geometric ambiguity, we introduce SynthRM, a scalable synthetic data platform. SynthRM implements a Visible-Aligned-Surface simulation strategy: rather than probing a global volumetric grid, it performs ray-tracing directly onto the geometry exposed to the sensor. This approach ensures pixel-level consistency between visual semantics and electromagnetic response, transforming the learning objective into a physically well-posed problem. We demonstrate the platform's capabilities by presenting a diverse, city-scale dataset derived from procedurally generated environments. By combining efficient procedural synthesis with high-fidelity electromagnetic modeling, SynthRM provides a transparent, accessible foundation for developing next-generation mobile systems for environment-aware sensing and communication.
DARCS: Memory-Efficient Deep Compressed Sensing Reconstruction for Acceleration of 3D Whole-Heart Coronary MR Angiography
Feb 02, 2024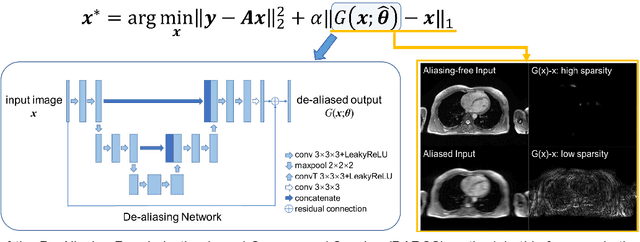
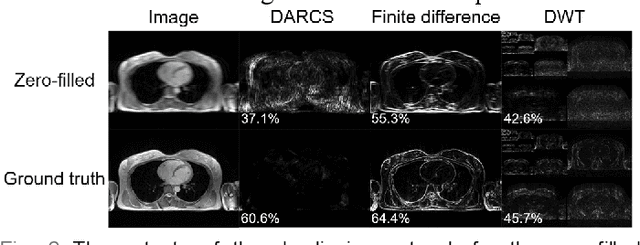
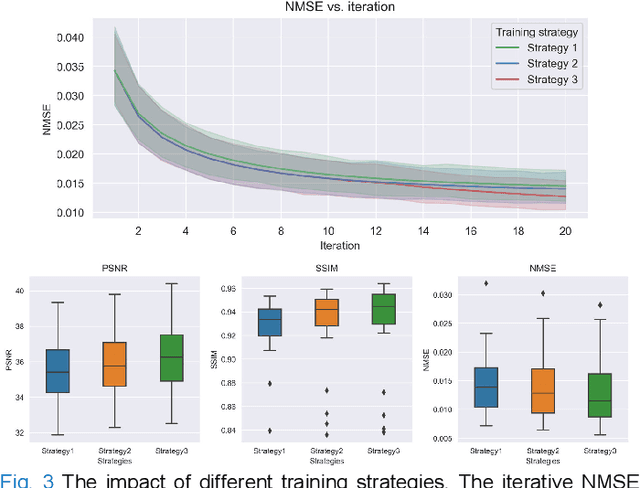
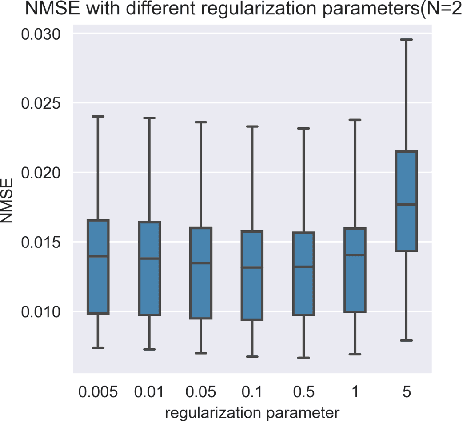
Three-dimensional coronary magnetic resonance angiography (CMRA) demands reconstruction algorithms that can significantly suppress the artifacts from a heavily undersampled acquisition. While unrolling-based deep reconstruction methods have achieved state-of-the-art performance on 2D image reconstruction, their application to 3D reconstruction is hindered by the large amount of memory needed to train an unrolled network. In this study, we propose a memory-efficient deep compressed sensing method by employing a sparsifying transform based on a pre-trained artifact estimation network. The motivation is that the artifact image estimated by a well-trained network is sparse when the input image is artifact-free, and less sparse when the input image is artifact-affected. Thus, the artifact-estimation network can be used as an inherent sparsifying transform. The proposed method, named De-Aliasing Regularization based Compressed Sensing (DARCS), was compared with a traditional compressed sensing method, de-aliasing generative adversarial network (DAGAN), model-based deep learning (MoDL), and plug-and-play for accelerations of 3D CMRA. The results demonstrate that the proposed method improved the reconstruction quality relative to the compared methods by a large margin. Furthermore, the proposed method well generalized for different undersampling rates and noise levels. The memory usage of the proposed method was only 63% of that needed by MoDL. In conclusion, the proposed method achieves improved reconstruction quality for 3D CMRA with reduced memory burden.
From Text to Sound: A Preliminary Study on Retrieving Sound Effects to Radio Stories
Aug 20, 2019
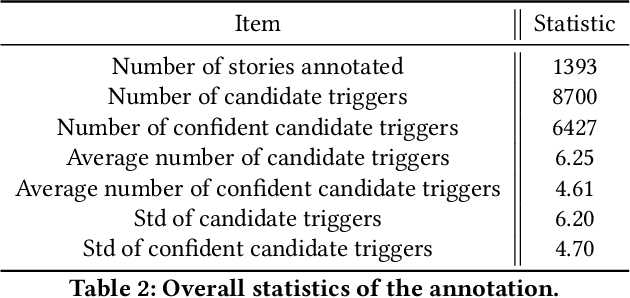

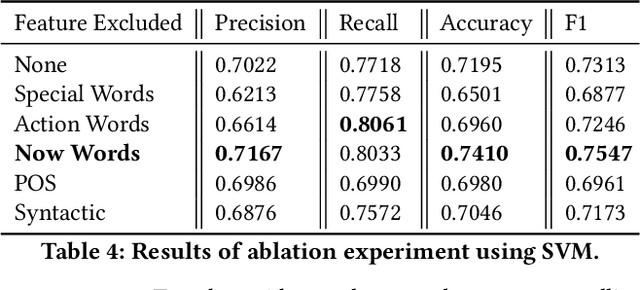
Sound effects play an essential role in producing high-quality radio stories but require enormous labor cost to add. In this paper, we address the problem of automatically adding sound effects to radio stories with a retrieval-based model. However, directly implementing a tag-based retrieval model leads to high false positives due to the ambiguity of story contents. To solve this problem, we introduce a retrieval-based framework hybridized with a semantic inference model which helps to achieve robust retrieval results. Our model relies on fine-designed features extracted from the context of candidate triggers. We collect two story dubbing datasets through crowdsourcing to analyze the setting of adding sound effects and to train and test our proposed methods. We further discuss the importance of each feature and introduce several heuristic rules for the trade-off between precision and recall. Together with the text-to-speech technology, our results reveal a promising automatic pipeline on producing high-quality radio stories.