 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqformer: Frequency-Domain Transformer for 3-D Visualization and Quantification of Human Retinal Circulation
Nov 17, 2024



We introduce Freqformer, a novel Transformer-based architecture designed for 3-D, high-definition visualization of human retinal circulation from a single scan in commercial optical coherence tomography angiography (OCTA). Freqformer addresses the challenge of limited signal-to-noise ratio in OCTA volume by utilizing a complex-valued frequency-domain module (CFDM) and a simplified multi-head attention (Sim-MHA) mechanism. Using merged volumes as ground truth, Freqformer enables accurate reconstruction of retinal vasculature across the depth planes, allowing for 3-D quantification of capillary segments (count, density, and length). Our method outperforms state-of-the-art convolutional neural networks (CNNs) and several Transformer-based models, with superior performance in peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS). Furthermore, Freqformer demonstrates excellent generalizability across lower scanning density, effectively enhancing OCTA scans with larger fields of view (from 3$\times$3 $mm^{2}$ to 6$\times$6 $mm^{2}$ and 12$\times$12 $mm^{2}$). These results suggest that Freqformer can significantly improve the understanding and characterization of retinal circulation, offering potential clinical applications in diagnosing and managing retinal vascular diseases.
Diagnostic Quality Assessment of Fundus Photographs: Hierarchical Deep Learning with Clinically Significant Explanations
Feb 18, 2023



Fundus photography (FP) remains the primary imaging modality in screening various retinal diseases including age-related macular degeneration, diabetic retinopathy and glaucoma. FP allows the clinician to examine the ocular fundus structures such as the macula, the optic disc (OD) and retinal vessels, whose visibility and clarity in an FP image remain central to ensuring diagnostic accuracy, and hence determine the diagnostic quality (DQ). Images with low DQ, resulting from eye movement, improper illumination and other possible causes, should obviously be recaptured. However, the technician, often unfamiliar with DQ criteria, initiates recapture only based on expert feedback. The process potentially engages the imaging device multiple times for single subject, and wastes the time and effort of the ophthalmologist, the technician and the subject. The burden could be prohibitive in case of teleophthalmology, where obtaining feedback from the remote expert entails additional communication cost and delay. Accordingly, a strong need for automated diagnostic quality assessment (DQA) has been felt, where an image is immediately assigned a DQ category. In response, motivated by the notional continuum of DQ, we propose a hierarchical deep learning (DL) architecture to distinguish between good, usable and unusable categories. On the public EyeQ dataset, we achieve an accuracy of 89.44%, improving upon existing methods. In addition, using gradient based class activation map (Grad-CAM), we generate a visual explanation which agrees with the expert intuition. Future FP cameras equipped with the proposed DQA algorithm will potentially improve the efficacy of the teleophthalmology as well as the traditional system.
Efficient Screening of Diseased Eyes based on Fundus Autofluorescence Images using Support Vector Machine
Apr 17, 2021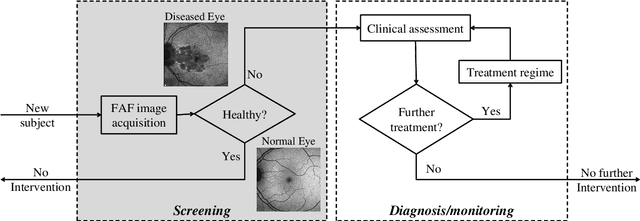
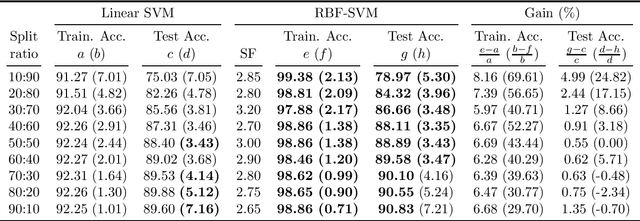
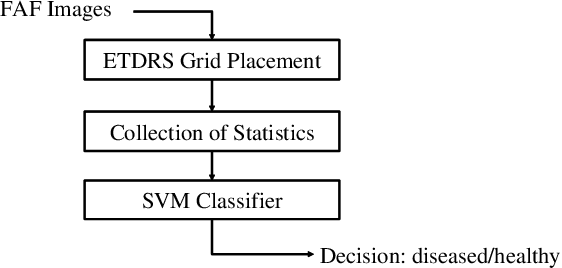
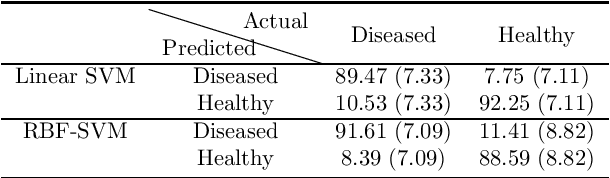
A variety of vision ailments are associated with geographic atrophy (GA) in the foveal region of the eye. In current clinical practice, the ophthalmologist manually detects potential presence of such GA based on fundus autofluorescence (FAF) images, and hence diagnoses the disease, when relevant. However, in view of the general scarcity of ophthalmologists relative to the large number of subjects seeking eyecare, especially in remote regions, it becomes imperative to develop methods to direct expert time and effort to medically significant cases. Further, subjects from either disadvantaged background or remote localities, who face considerable economic/physical barrier in consulting trained ophthalmologists, tend to seek medical attention only after being reasonably certain that an adverse condition exists. To serve the interest of both the ophthalmologist and the potential patient, we plan a screening step, where healthy and diseased eyes are algorithmically differentiated with limited input from only optometrists who are relatively more abundant in number. Specifically, an early treatment diabetic retinopathy study (ETDRS) grid is placed by an optometrist on each FAF image, based on which sectoral statistics are automatically collected. Using such statistics as features, healthy and diseased eyes are proposed to be classified by training an algorithm using available medical records. In this connection, we demonstrate the efficacy of support vector machines (SVM). Specifically, we consider SVM with linear as well as radial basis function (RBF) kernel, and observe satisfactory performance of both variants. Among those, we recommend the latter in view of its slight superiority in terms of classification accuracy (90.55% at a standard training-to-test ratio of 80:20), and practical class-conditional costs.