 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqformer: Frequency-Domain Transformer for 3-D Visualization and Quantification of Human Retinal Circulation
Nov 17, 2024



We introduce Freqformer, a novel Transformer-based architecture designed for 3-D, high-definition visualization of human retinal circulation from a single scan in commercial optical coherence tomography angiography (OCTA). Freqformer addresses the challenge of limited signal-to-noise ratio in OCTA volume by utilizing a complex-valued frequency-domain module (CFDM) and a simplified multi-head attention (Sim-MHA) mechanism. Using merged volumes as ground truth, Freqformer enables accurate reconstruction of retinal vasculature across the depth planes, allowing for 3-D quantification of capillary segments (count, density, and length). Our method outperforms state-of-the-art convolutional neural networks (CNNs) and several Transformer-based models, with superior performance in peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS). Furthermore, Freqformer demonstrates excellent generalizability across lower scanning density, effectively enhancing OCTA scans with larger fields of view (from 3$\times$3 $mm^{2}$ to 6$\times$6 $mm^{2}$ and 12$\times$12 $mm^{2}$). These results suggest that Freqformer can significantly improve the understanding and characterization of retinal circulation, offering potential clinical applications in diagnosing and managing retinal vascular diseases.
BreakNet: Discontinuity-Resilient Multi-Scale Transformer Segmentation of Retinal Layers
Aug 26, 2024Visible light optical coherence tomography (vis-OCT) is gaining traction for retinal imaging due to its high resolution and functional capabilities. However, the significant absorption of hemoglobin in the visible light range leads to pronounced shadow artifacts from retinal blood vessels, posing challenges for accurate layer segmentation. In this study, we present BreakNet, a multi-scale Transformer-based segmentation model designed to address boundary discontinuities caused by these shadow artifacts. BreakNet utilizes hierarchical Transformer and convolutional blocks to extract multi-scale global and local feature maps, capturing essential contextual, textural, and edge characteristics. The model incorporates decoder blocks that expand pathwaproys to enhance the extraction of fine details and semantic information, ensuring precise segmentation. Evaluated on rodent retinal images acquired with prototype vis-OCT, BreakNet demonstrated superior performance over state-of-the-art segmentation models, such as TCCT-BP and U-Net, even when faced with limited-quality ground truth data. Our findings indicate that BreakNet has the potential to significantly improve retinal quantification and analysis.
Fully Automated OCT-based Tissue Screening System
May 15, 2024This study introduces a groundbreaking optical coherence tomography (OCT) imaging system dedicated for high-throughput screening applications using ex vivo tissue culture. Leveraging OCT's non-invasive, high-resolution capabilities, the system is equipped with a custom-designed motorized platform and tissue detection ability for automated, successive imaging across samples. Transformer-based deep learning segmentation algorithms further ensure robust, consistent, and efficient readouts meeting the standards for screening assays. Validated using retinal explant cultures from a mouse model of retinal degeneration, the system provides robust, rapid, reliable, unbiased, and comprehensive readouts of tissue response to treatments. This fully automated OCT-based system marks a significant advancement in tissue screening, promising to transform drug discovery, as well as other relevant research fields.
Sub2Full: split spectrum to boost OCT despeckling without clean data
Jan 18, 2024
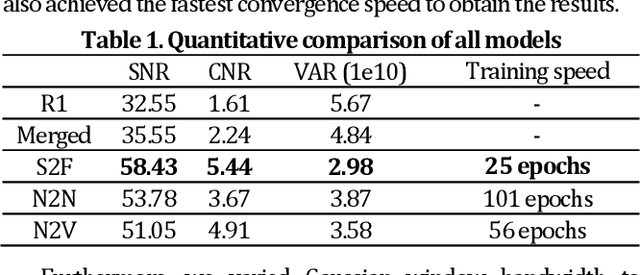

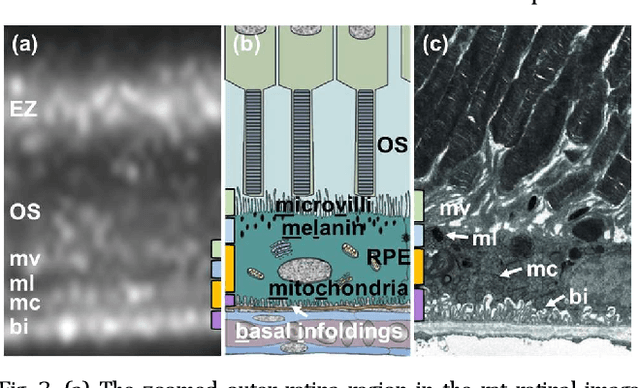
Optical coherence tomography (OCT) suffers from speckle noise, causing the deterioration of image quality, especially in high-resolution modalities like visible light OCT (vis-OCT). The potential of conventional supervised deep learning denoising methods is limited by the difficulty of obtaining clean data. Here, we proposed an innovative self-supervised strategy called Sub2Full (S2F) for OCT despeckling without clean data. This approach works by acquiring two repeated B-scans, splitting the spectrum of the first repeat as a low-resolution input, and utilizing the full spectrum of the second repeat as the high-resolution target. The proposed method was validated on vis-OCT retinal images visualizing sublaminar structures in outer retina and demonstrated superior performance over conventional Noise2Noise and Noise2Void schemes. The code is available at https://github.com/PittOCT/Sub2Full-OCT-Denoising.