 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Time Machine: A Real-Time Rendering Methodology for Time-Variant Appearances
May 22, 2024



Recent advancements in neural rendering techniques have significantly enhanced the fidelity of 3D reconstruction. Notably, the emergence of 3D Gaussian Splatting (3DGS) has marked a significant milestone by adopting a discrete scene representation, facilitating efficient training and real-time rendering. Several studies have successfully extended the real-time rendering capability of 3DGS to dynamic scenes. However, a challenge arises when training images are captured under vastly differing weather and lighting conditions. This scenario poses a challenge for 3DGS and its variants in achieving accurate reconstructions. Although NeRF-based methods (NeRF-W, CLNeRF) have shown promise in handling such challenging conditions, their computational demands hinder real-time rendering capabilities. In this paper, we present Gaussian Time Machine (GTM) which models the time-dependent attributes of Gaussian primitives with discrete time embedding vectors decoded by a lightweight Multi-Layer-Perceptron(MLP). By adjusting the opacity of Gaussian primitives, we can reconstruct visibility changes of objects. We further propose a decomposed color model for improved geometric consistency. GTM achieved state-of-the-art rendering fidelity on 3 datasets and is 100 times faster than NeRF-based counterparts in rendering. Moreover, GTM successfully disentangles the appearance changes and renders smooth appearance interpolation.
Cross-lingual Pseudo-Projected Expectation Regularization for Weakly Supervised Learning
Oct 06, 2013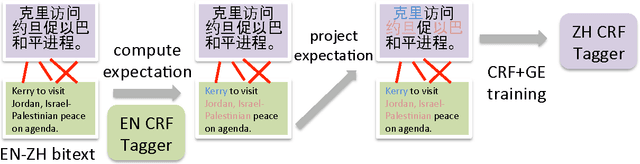
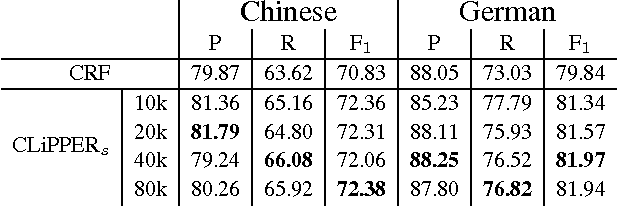
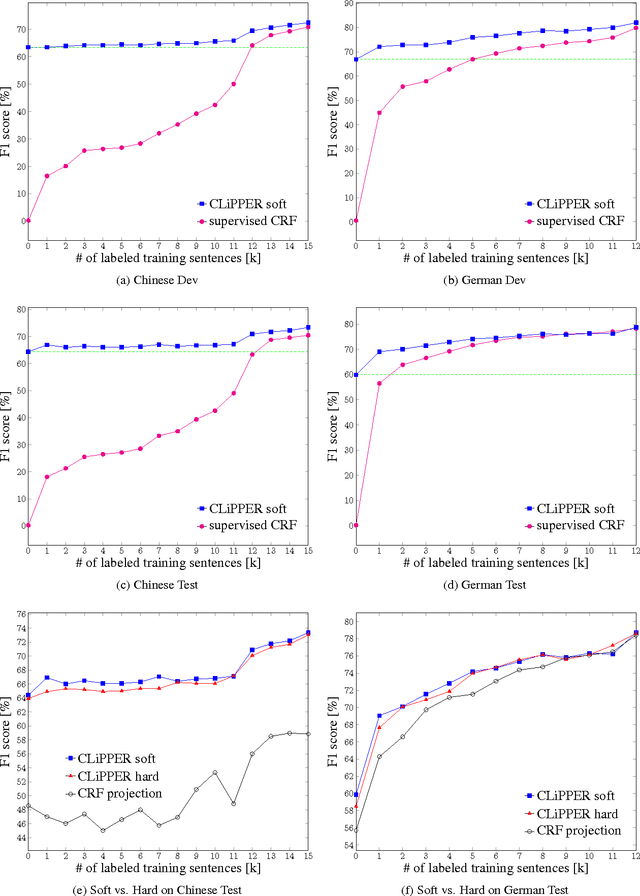
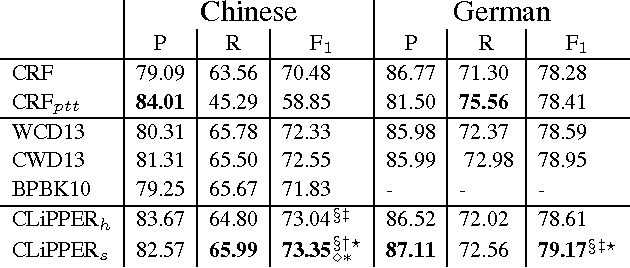
We consider a multilingual weakly supervised learning scenario where knowledge from annotated corpora in a resource-rich language is transferred via bitext to guide the learning in other languages. Past approaches project labels across bitext and use them as features or gold labels for training. We propose a new method that projects model expectations rather than labels, which facilities transfer of model uncertainty across language boundaries. We encode expectations as constraints and train a discriminative CRF model using Generalized Expectation Criteria (Mann and McCallum, 2010). Evaluated on standard Chinese-English and German-English NER datasets, our method demonstrates F1 scores of 64% and 60% when no labeled data is used. Attaining the same accuracy with supervised CRFs requires 12k and 1.5k labeled sentences. Furthermore, when combined with labeled examples, our method yields significant improvements over state-of-the-art supervised methods, achieving best reported numbers to date on Chinese OntoNotes and German CoNLL-03 datasets.