 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatsformer: Validated Ensemble Learning with LLM-Derived Semantic Priors
Jan 29, 2026We introduce Statsformer, a principled framework for integrating large language model (LLM)-derived knowledge into supervised statistical learning. Existing approaches are limited in adaptability and scope: they either inject LLM guidance as an unvalidated heuristic, which is sensitive to LLM hallucination, or embed semantic information within a single fixed learner. Statsformer overcomes both limitations through a guardrailed ensemble architecture. We embed LLM-derived feature priors within an ensemble of linear and nonlinear learners, adaptively calibrating their influence via cross-validation. This design yields a flexible system with an oracle-style guarantee that it performs no worse than any convex combination of its in-library base learners, up to statistical error. Empirically, informative priors yield consistent performance improvements, while uninformative or misspecified LLM guidance is automatically downweighted, mitigating the impact of hallucinations across a diverse range of prediction tasks.
Universal Discrete Filtering with Lookahead or Delay
Jan 17, 2025



We consider the universal discrete filtering problem, where an input sequence generated by an unknown source passes through a discrete memoryless channel, and the goal is to estimate its components based on the output sequence with limited lookahead or delay. We propose and establish the universality of a family of schemes for this setting. These schemes are induced by universal Sequential Probability Assignments (SPAs), and inherit their computational properties. We show that the schemes induced by LZ78 are practically implementable and well-suited for scenarios with limited computational resources and latency constraints. In passing, we use some of the intermediate results to obtain upper and lower bounds that appear to be new, in the purely Bayesian setting, on the optimal filtering performance in terms, respectively, of the mutual information between the noise-free and noisy sequence, and the entropy of the noise-free sequence causally conditioned on the noisy one.
Compressing Large Language Models using Low Rank and Low Precision Decomposition
May 29, 2024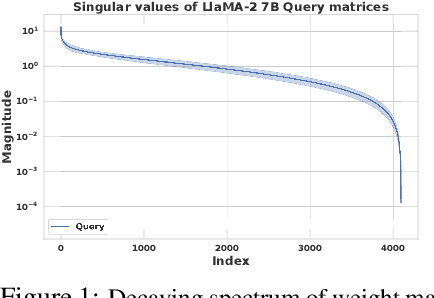
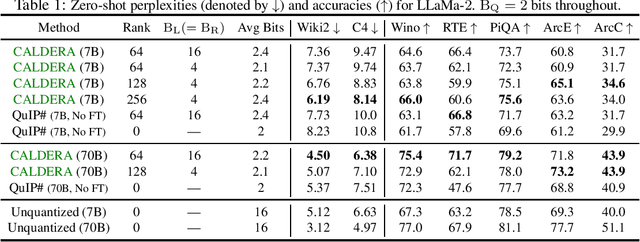
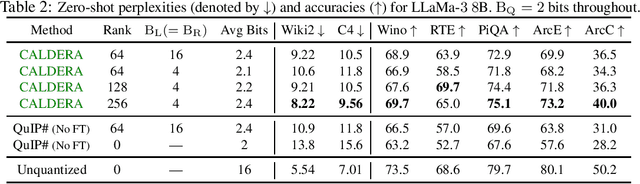
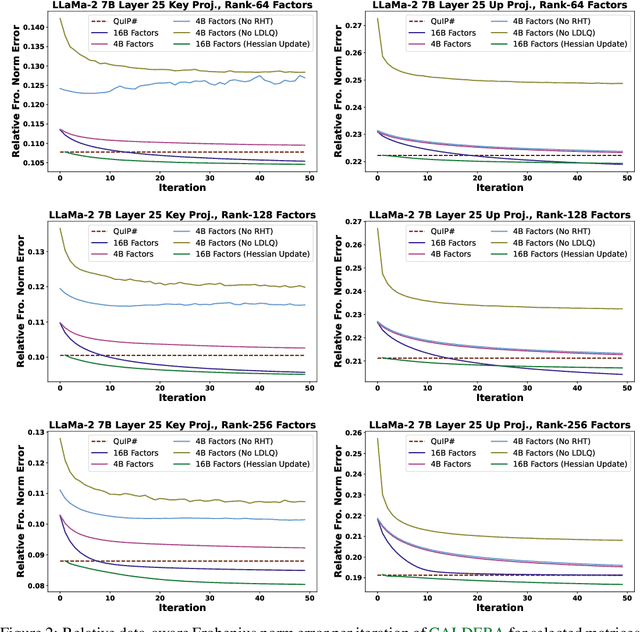
The prohibitive sizes of Large Language Models (LLMs) today make it difficult to deploy them on memory-constrained edge devices. This work introduces $\rm CALDERA$ -- a new post-training LLM compression algorithm that harnesses the inherent low-rank structure of a weight matrix $\mathbf{W}$ by approximating it via a low-rank, low-precision decomposition as $\mathbf{W} \approx \mathbf{Q} + \mathbf{L}\mathbf{R}$. Here, $\mathbf{L}$ and $\mathbf{R}$ are low rank factors, and the entries of $\mathbf{Q}$, $\mathbf{L}$ and $\mathbf{R}$ are quantized. The model is compressed by substituting each layer with its $\mathbf{Q} + \mathbf{L}\mathbf{R}$ decomposition, and the zero-shot performance of the compressed model is evaluated. Additionally, $\mathbf{L}$ and $\mathbf{R}$ are readily amenable to low-rank adaptation, consequently enhancing the zero-shot performance. $\rm CALDERA$ obtains this decomposition by formulating it as an optimization problem $\min_{\mathbf{Q},\mathbf{L},\mathbf{R}}\lVert(\mathbf{Q} + \mathbf{L}\mathbf{R} - \mathbf{W})\mathbf{X}^\top\rVert_{\rm F}^2$, where $\mathbf{X}$ is the calibration data, and $\mathbf{Q}, \mathbf{L}, \mathbf{R}$ are constrained to be representable using low-precision formats. Theoretical upper bounds on the approximation error of $\rm CALDERA$ are established using a rank-constrained regression framework, and the tradeoff between compression ratio and model performance is studied by analyzing the impact of target rank and quantization bit budget. Results illustrate that compressing LlaMa-$2$ $7$B/$70$B and LlaMa-$3$ $8$B models obtained using $\rm CALDERA$ outperforms existing post-training LLM compression techniques in the regime of less than $2.5$ bits per parameter. The implementation is available at: \href{https://github.com/pilancilab/caldera}{https://github.com/pilancilab/caldera}.