 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning over Wireless Networks with Homomorphic State Representations
Aug 11, 2025In this work, we address the problem of training Reinforcement Learning (RL) agents over communication networks. The RL paradigm requires the agent to instantaneously perceive the state evolution to infer the effects of its actions on the environment. This is impossible if the agent receives state updates over lossy or delayed wireless systems and thus operates with partial and intermittent information. In recent years, numerous frameworks have been proposed to manage RL with imperfect feedback; however, they often offer specific solutions with a substantial computational burden. To address these limits, we propose a novel architecture, named Homomorphic Robust Remote Reinforcement Learning (HR3L), that enables the training of remote RL agents exchanging observations across a non-ideal wireless channel. HR3L considers two units: the transmitter, which encodes meaningful representations of the environment, and the receiver, which decodes these messages and performs actions to maximize a reward signal. Importantly, HR3L does not require the exchange of gradient information across the wireless channel, allowing for quicker training and a lower communication overhead than state-of-the-art solutions. Experimental results demonstrate that HR3L significantly outperforms baseline methods in terms of sample efficiency and adapts to different communication scenarios, including packet losses, delayed transmissions, and capacity limitations.
Effective Communication with Dynamic Feature Compression
Jan 29, 2024The remote wireless control of industrial systems is one of the major use cases for 5G and beyond systems: in these cases, the massive amounts of sensory information that need to be shared over the wireless medium may overload even high-capacity connections. Consequently, solving the effective communication problem by optimizing the transmission strategy to discard irrelevant information can provide a significant advantage, but is often a very complex task. In this work, we consider a prototypal system in which an observer must communicate its sensory data to a robot controlling a task (e.g., a mobile robot in a factory). We then model it as a remote Partially Observable Markov Decision Process (POMDP), considering the effect of adopting semantic and effective communication-oriented solutions on the overall system performance. We split the communication problem by considering an ensemble Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and train a Deep Reinforcement Learning (DRL) agent to dynamically adapt the quantization level, considering both the current state of the environment and the memory of past messages. We tested the proposed approach on the well-known CartPole reference control problem, obtaining a significant performance increase over traditional approaches.
Push- and Pull-based Effective Communication in Cyber-Physical Systems
Jan 15, 2024In Cyber Physical Systems (CPSs), two groups of actors interact toward the maximization of system performance: the sensors, observing and disseminating the system state, and the actuators, performing physical decisions based on the received information. While it is generally assumed that sensors periodically transmit updates, returning the feedback signal only when necessary, and consequently adapting the physical decisions to the communication policy, can significantly improve the efficiency of the system. In particular, the choice between push-based communication, in which updates are initiated autonomously by the sensors, and pull-based communication, in which they are requested by the actuators, is a key design step. In this work, we propose an analytical model for optimizing push- and pull-based communication in CPSs, observing that the policy optimality coincides with Value of Information (VoI) maximization. Our results also highlight that, despite providing a better optimal solution, implementable push-based communication strategies may underperform even in relatively simple scenarios.
Semantic and Effective Communication for Remote Control Tasks with Dynamic Feature Compression
Jan 14, 2023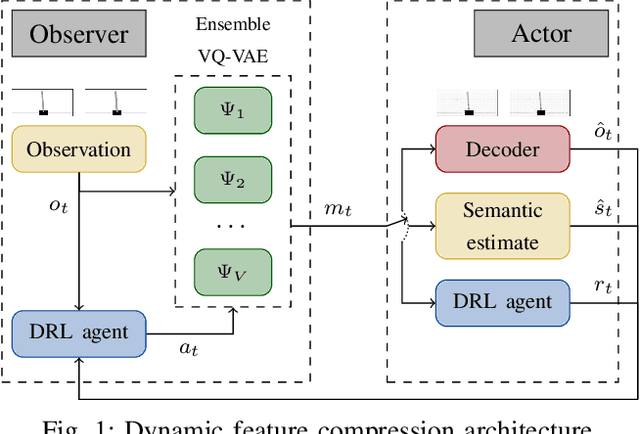
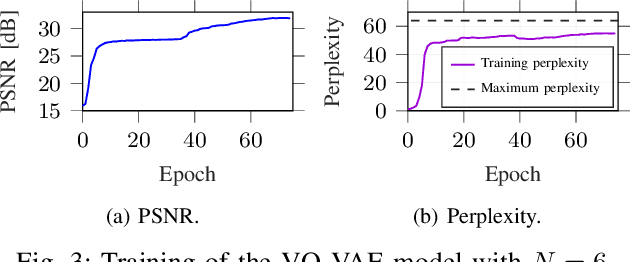
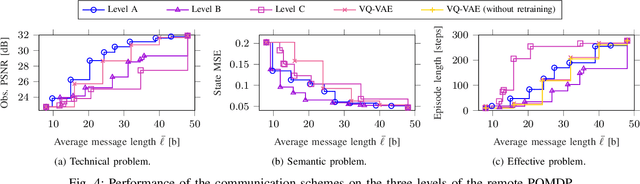
The coordination of robotic swarms and the remote wireless control of industrial systems are among the major use cases for 5G and beyond systems: in these cases, the massive amounts of sensory information that needs to be shared over the wireless medium can overload even high-capacity connections. Consequently, solving the effective communication problem by optimizing the transmission strategy to discard irrelevant information can provide a significant advantage, but is often a very complex task. In this work, we consider a prototypal system in which an observer must communicate its sensory data to an actor controlling a task (e.g., a mobile robot in a factory). We then model it as a remote Partially Observable Markov Decision Process (POMDP), considering the effect of adopting semantic and effective communication-oriented solutions on the overall system performance. We split the communication problem by considering an ensemble Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and train a Deep Reinforcement Learning (DRL) agent to dynamically adapt the quantization level, considering both the current state of the environment and the memory of past messages. We tested the proposed approach on the well-known CartPole reference control problem, obtaining a significant performance increase over traditional approaches