 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Context Adaptation in Cost-Aware Continual Learning
Jun 06, 2023In the past few years, DRL has become a valuable solution to automatically learn efficient resource management strategies in complex networks with time-varying statistics. However, the increased complexity of 5G and Beyond networks requires correspondingly more complex learning agents and the learning process itself might end up competing with users for communication and computational resources. This creates friction: on the one hand, the learning process needs resources to quickly convergence to an effective strategy; on the other hand, the learning process needs to be efficient, i.e., take as few resources as possible from the user's data plane, so as not to throttle users' QoS. In this paper, we investigate this trade-off and propose a dynamic strategy to balance the resources assigned to the data plane and those reserved for learning. With the proposed approach, a learning agent can quickly converge to an efficient resource allocation strategy and adapt to changes in the environment as for the CL paradigm, while minimizing the impact on the users' QoS. Simulation results show that the proposed method outperforms static allocation methods with minimal learning overhead, almost reaching the performance of an ideal out-of-band CL solution.
The Cost of Learning: Efficiency vs. Efficacy of Learning-Based RRM for 6G
Nov 30, 2022



In the past few years, Deep Reinforcement Learning (DRL) has become a valuable solution to automatically learn efficient resource management strategies in complex networks. In many scenarios, the learning task is performed in the Cloud, while experience samples are generated directly by edge nodes or users. Therefore, the learning task involves some data exchange which, in turn, subtracts a certain amount of transmission resources from the system. This creates a friction between the need to speed up convergence towards an effective strategy, which requires the allocation of resources to transmit learning samples, and the need to maximize the amount of resources used for data plane communication, maximizing users' Quality of Service (QoS), which requires the learning process to be efficient, i.e., minimize its overhead. In this paper, we investigate this trade-off and propose a dynamic balancing strategy between the learning and data planes, which allows the centralized learning agent to quickly converge to an efficient resource allocation strategy while minimizing the impact on QoS. Simulation results show that the proposed method outperforms static allocation methods, converging to the optimal policy (i.e., maximum efficacy and minimum overhead of the learning plane) in the long run.
Energy Consumption of Neural Networks on NVIDIA Edge Boards: an Empirical Model
Oct 04, 2022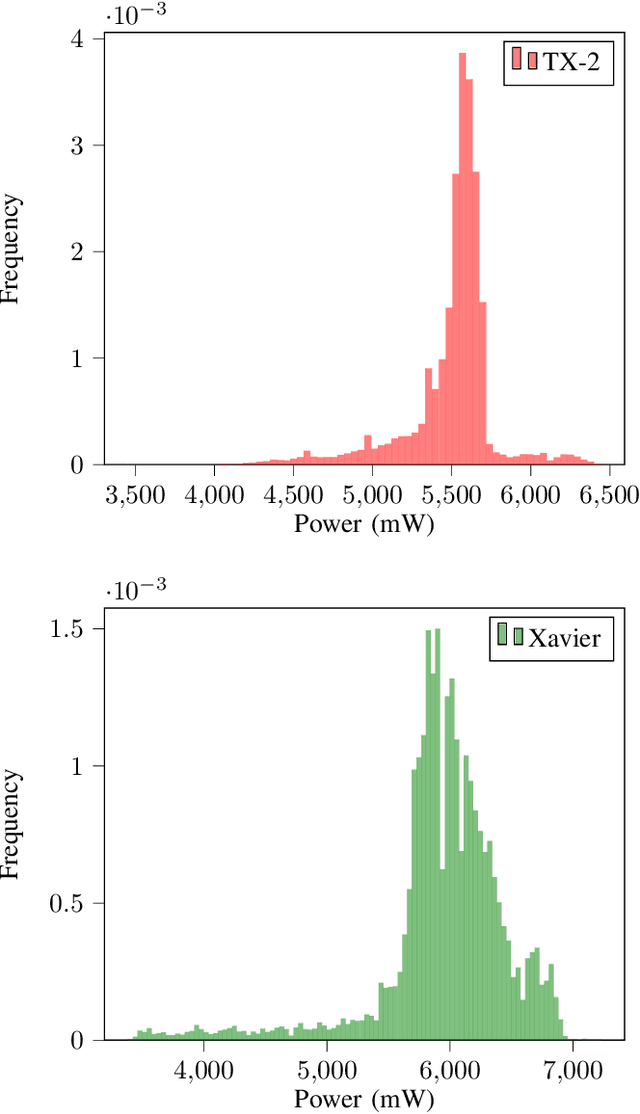
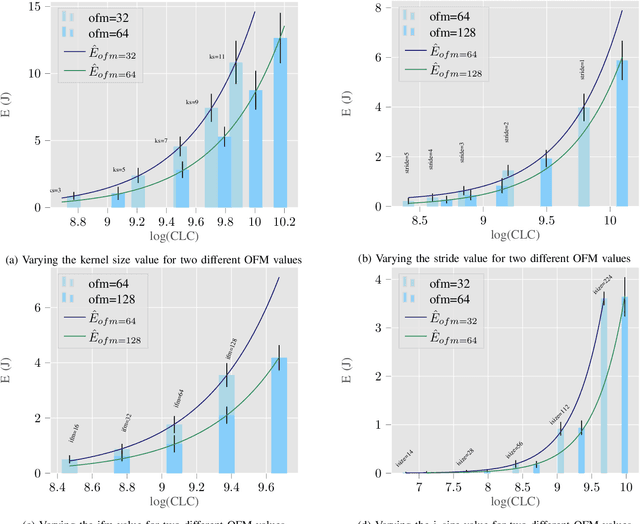
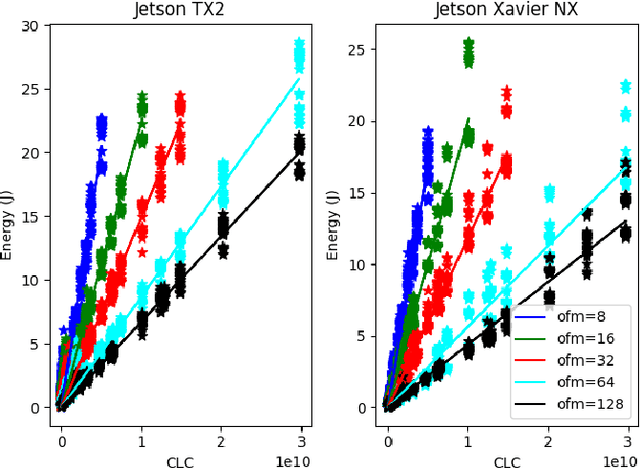
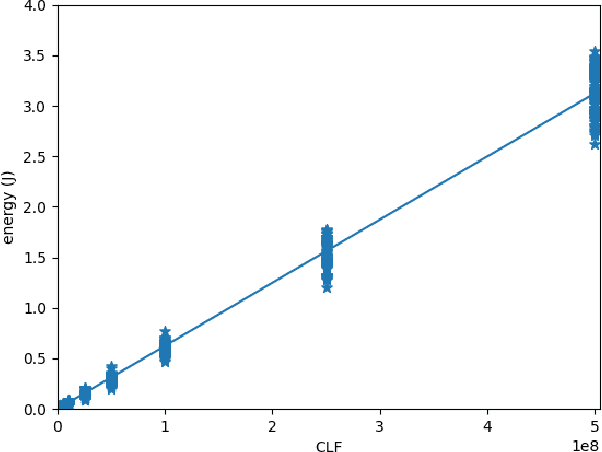
Recently, there has been a trend of shifting the execution of deep learning inference tasks toward the edge of the network, closer to the user, to reduce latency and preserve data privacy. At the same time, growing interest is being devoted to the energetic sustainability of machine learning. At the intersection of these trends, we hence find the energetic characterization of machine learning at the edge, which is attracting increasing attention. Unfortunately, calculating the energy consumption of a given neural network during inference is complicated by the heterogeneity of the possible underlying hardware implementation. In this work, we hence aim at profiling the energetic consumption of inference tasks for some modern edge nodes and deriving simple but realistic models. To this end, we performed a large number of experiments to collect the energy consumption of convolutional and fully connected layers on two well-known edge boards by NVIDIA, namely Jetson TX2 and Xavier. From the measurements, we have then distilled a simple, practical model that can provide an estimate of the energy consumption of a certain inference task on the considered boards. We believe that this model can be used in many contexts as, for instance, to guide the search for efficient architectures in Neural Architecture Search, as a heuristic in Neural Network pruning, or to find energy-efficient offloading strategies in a Split computing context, or simply to evaluate the energetic performance of Deep Neural Network architectures.