 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing economic facts: LLMs know more than they say
May 13, 2025We investigate whether the hidden states of large language models (LLMs) can be used to estimate and impute economic and financial statistics. Focusing on county-level (e.g. unemployment) and firm-level (e.g. total assets) variables, we show that a simple linear model trained on the hidden states of open-source LLMs outperforms the models' text outputs. This suggests that hidden states capture richer economic information than the responses of the LLMs reveal directly. A learning curve analysis indicates that only a few dozen labelled examples are sufficient for training. We also propose a transfer learning method that improves estimation accuracy without requiring any labelled data for the target variable. Finally, we demonstrate the practical utility of hidden-state representations in super-resolution and data imputation tasks.
Public Health in Disaster: Emotional Health and Life Incidents Extraction during Hurricane Harvey
Aug 20, 2024Countless disasters have resulted from climate change, causing severe damage to infrastructure and the economy. These disasters have significant societal impacts, necessitating mental health services for the millions affected. To prepare for and respond effectively to such events, it is important to understand people's emotions and the life incidents they experience before and after a disaster strikes. In this case study, we collected a dataset of approximately 400,000 public tweets related to the storm. Using a BERT-based model, we predicted the emotions associated with each tweet. To efficiently identify these topics, we utilized the Latent Dirichlet Allocation (LDA) technique for topic modeling, which allowed us to bypass manual content analysis and extract meaningful patterns from the data. However, rather than stopping at topic identification like previous methods \cite{math11244910}, we further refined our analysis by integrating Graph Neural Networks (GNN) and Large Language Models (LLM). The GNN was employed to generate embeddings and construct a similarity graph of the tweets, which was then used to optimize clustering. Subsequently, we used an LLM to automatically generate descriptive names for each event cluster, offering critical insights for disaster preparedness and response strategies.
Causality Detection using Multiple Annotation Decision
Oct 26, 2022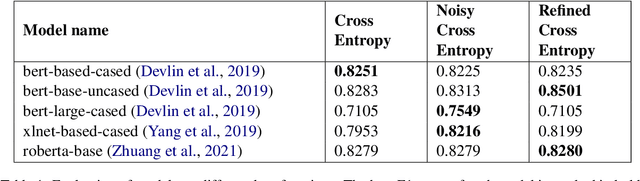
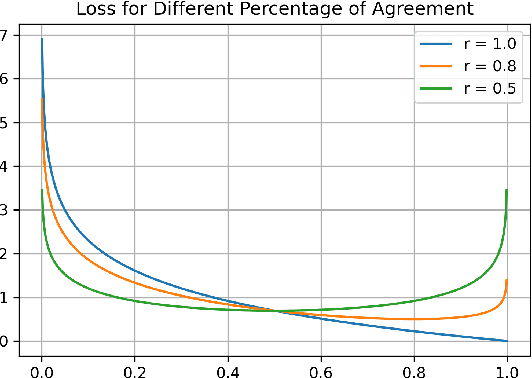
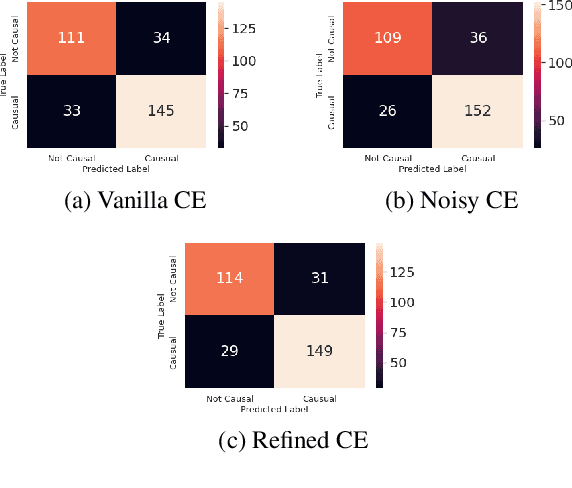
The paper describes the work that has been submitted to the 5th workshop on Challenges and Applications of Automated Extraction of socio-political events from text (CASE 2022). The work is associated with Subtask 1 of Shared Task 3 that aims to detect causality in protest news corpus. The authors used different large language models with customized cross-entropy loss functions that exploit annotation information. The experiments showed that bert-based-uncased with refined cross-entropy outperformed the others, achieving a F1 score of 0.8501 on the Causal News Corpus dataset.