 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving In-Bed Pose Monitoring: A Fusion and Reconstruction Study
Feb 22, 2022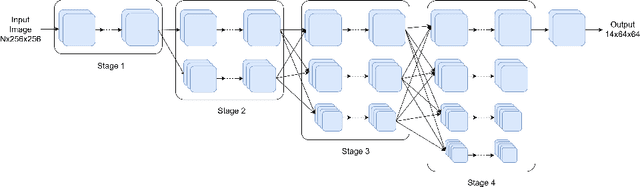

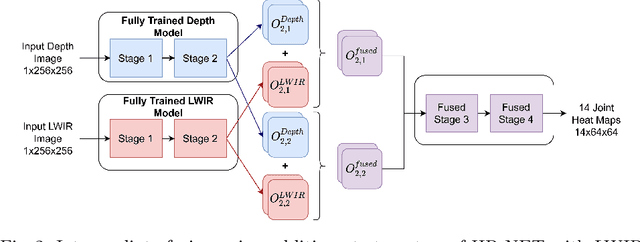
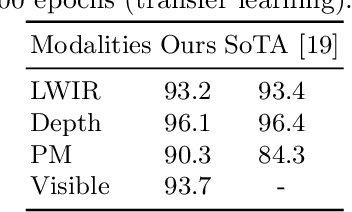
Recently, in-bed human pose estimation has attracted the interest of researchers due to its relevance to a wide range of healthcare applications. Compared to the general problem of human pose estimation, in-bed pose estimation has several inherent challenges, the most prominent being frequent and severe occlusions caused by bedding. In this paper we explore the effective use of images from multiple non-visual and privacy-preserving modalities such as depth, long-wave infrared (LWIR) and pressure maps for the task of in-bed pose estimation in two settings. First, we explore the effective fusion of information from different imaging modalities for better pose estimation. Secondly, we propose a framework that can estimate in-bed pose estimation when visible images are unavailable, and demonstrate the applicability of fusion methods to scenarios where only LWIR images are available. We analyze and demonstrate the effect of fusing features from multiple modalities. For this purpose, we consider four different techniques: 1) Addition, 2) Concatenation, 3) Fusion via learned modal weights, and 4) End-to-end fully trainable approach; with a state-of-the-art pose estimation model. We also evaluate the effect of reconstructing a data-rich modality (i.e., visible modality) from a privacy-preserving modality with data scarcity (i.e., long-wavelength infrared) for in-bed human pose estimation. For reconstruction, we use a conditional generative adversarial network. We conduct ablative studies across different design decisions of our framework. This includes selecting features with different levels of granularity, using different fusion techniques, and varying model parameters. Through extensive evaluations, we demonstrate that our method produces on par or better results compared to the state-of-the-art.