 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere, What, Whether: Multi-modal Learning Meets Pedestrian Detection
Paper and Code
Dec 20, 2020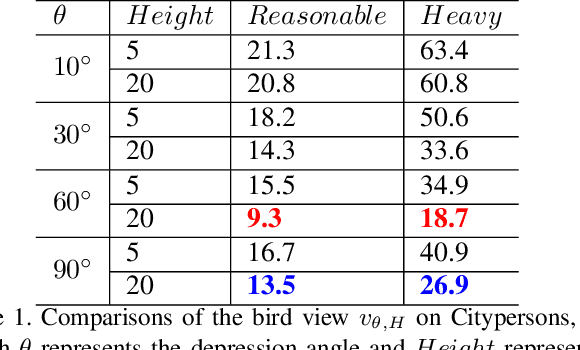
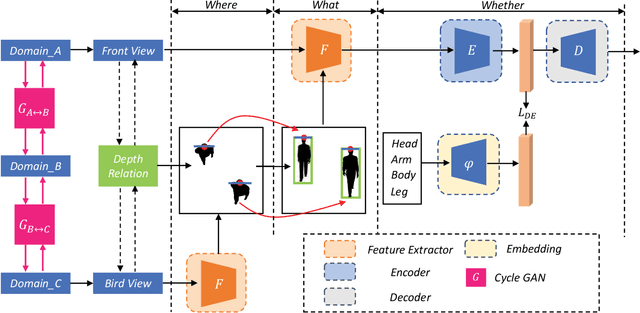
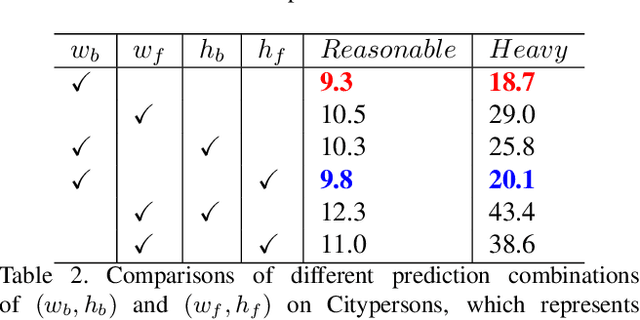
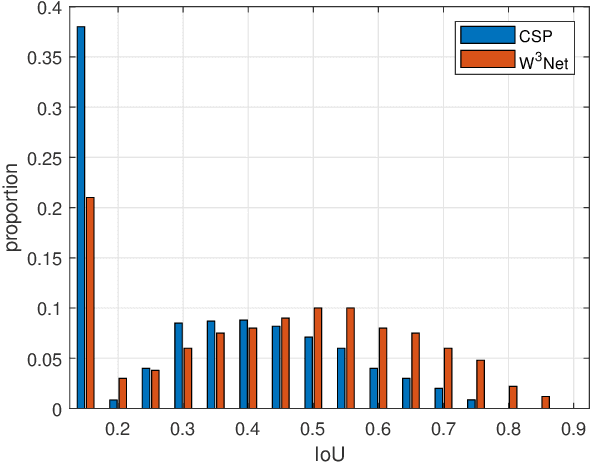
Pedestrian detection benefits greatly from deep convolutional neural networks (CNNs). However, it is inherently hard for CNNs to handle situations in the presence of occlusion and scale variation. In this paper, we propose W$^3$Net, which attempts to address above challenges by decomposing the pedestrian detection task into \textbf{\textit{W}}here, \textbf{\textit{W}}hat and \textbf{\textit{W}}hether problem directing against pedestrian localization, scale prediction and classification correspondingly. Specifically, for a pedestrian instance, we formulate its feature by three steps. i) We generate a bird view map, which is naturally free from occlusion issues, and scan all points on it to look for suitable locations for each pedestrian instance. ii) Instead of utilizing pre-fixed anchors, we model the interdependency between depth and scale aiming at generating depth-guided scales at different locations for better matching instances of different sizes. iii) We learn a latent vector shared by both visual and corpus space, by which false positives with similar vertical structure but lacking human partial features would be filtered out. We achieve state-of-the-art results on widely used datasets (Citypersons and Caltech). In particular. when evaluating on heavy occlusion subset, our results reduce MR$^{-2}$ from 49.3$\%$ to 18.7$\%$ on Citypersons, and from 45.18$\%$ to 28.33$\%$ on Caltech.