 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024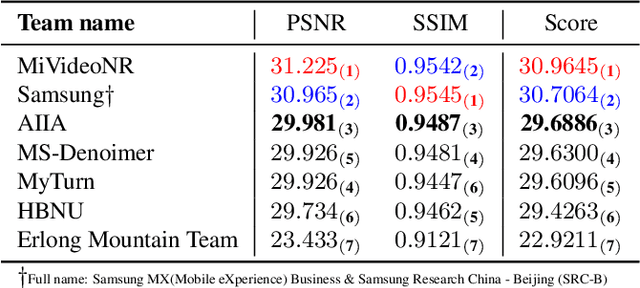
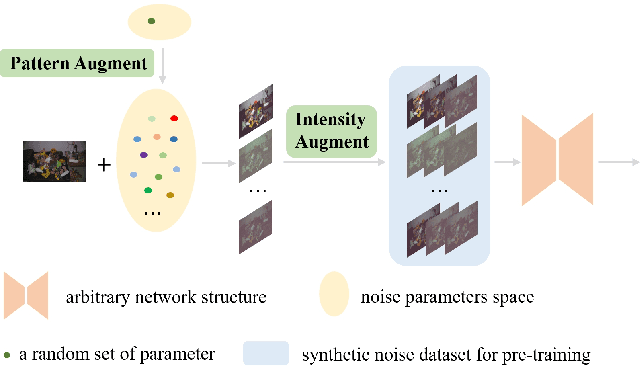

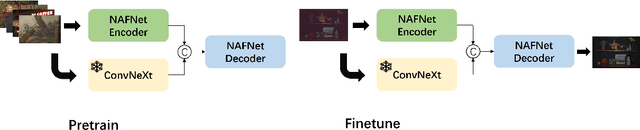
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
Hierarchical Gaussian Mixture Normalizing Flow Modeling for Unified Anomaly Detection
Mar 20, 2024Unified anomaly detection (AD) is one of the most challenges for anomaly detection, where one unified model is trained with normal samples from multiple classes with the objective to detect anomalies in these classes. For such a challenging task, popular normalizing flow (NF) based AD methods may fall into a "homogeneous mapping" issue,where the NF-based AD models are biased to generate similar latent representations for both normal and abnormal features, and thereby lead to a high missing rate of anomalies. In this paper, we propose a novel Hierarchical Gaussian mixture normalizing flow modeling method for accomplishing unified Anomaly Detection, which we call HGAD. Our HGAD consists of two key components: inter-class Gaussian mixture modeling and intra-class mixed class centers learning. Compared to the previous NF-based AD methods, the hierarchical Gaussian mixture modeling approach can bring stronger representation capability to the latent space of normalizing flows, so that even complex multi-class distribution can be well represented and learned in the latent space. In this way, we can avoid mapping different class distributions into the same single Gaussian prior, thus effectively avoiding or mitigating the "homogeneous mapping" issue. We further indicate that the more distinguishable different class centers, the more conducive to avoiding the bias issue. Thus, we further propose a mutual information maximization loss for better structuring the latent feature space. We evaluate our method on four real-world AD benchmarks, where we can significantly improve the previous NF-based AD methods and also outperform the SOTA unified AD methods.
Focus the Discrepancy: Intra- and Inter-Correlation Learning for Image Anomaly Detection
Aug 06, 2023



Humans recognize anomalies through two aspects: larger patch-wise representation discrepancies and weaker patch-to-normal-patch correlations. However, the previous AD methods didn't sufficiently combine the two complementary aspects to design AD models. To this end, we find that Transformer can ideally satisfy the two aspects as its great power in the unified modeling of patch-wise representations and patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can simultaneously spot the patch-wise, intra- and inter-discrepancies of anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to Intra-Inter-Correlation (I2Correlation). The I2Correlation contains a two-branch structure to first explicitly establish intra- and inter-image correlations, and then fuses the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning. Besides, we introduce an entropy constraint strategy to solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability. Extensive experiments on three unsupervised real-world AD benchmarks show the superior performance of our approach. Code will be available at https://github.com/xcyao00/FOD.
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Better Anomaly Detection
Jul 04, 2022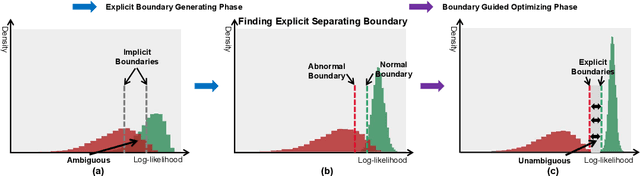
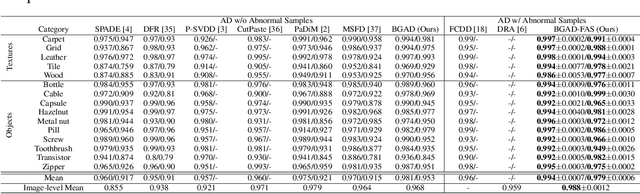


Most of anomaly detection algorithms are mainly focused on modeling the distribution of normal samples and treating anomalies as outliers. However, the discriminative performance of the model may be insufficient due to the lack of knowledge about anomalies. Thus, anomalies should be exploited as possible. However, utilizing a few known anomalies during training may cause another issue that model may be biased by those known anomalies and fail to generalize to unseen anomalies. In this paper, we aim to exploit a few existing anomalies with a carefully designed explicit boundary guided semi-push-pull learning strategy, which can enhance discriminability while mitigating bias problem caused by insufficient known anomalies. Our model is based on two core designs: First, finding one explicit separating boundary as the guidance for further contrastive learning. Specifically, we employ normalizing flow to learn normal feature distribution, then find an explicit separating boundary close to the distribution edge. The obtained explicit and compact separating boundary only relies on the normal feature distribution, thus the bias problem caused by a few known anomalies can be mitigated. Second, learning more discriminative features under the guidance of the explicit separating boundary. A boundary guided semi-push-pull loss is developed to only pull the normal features together while pushing the abnormal features apart from the separating boundary beyond a certain margin region. In this way, our model can form a more explicit and discriminative decision boundary to achieve better results for known and also unseen anomalies, while also maintaining high training efficiency. Extensive experiments on the widely-used MVTecAD benchmark show that the proposed method achieves new state-of-the-art results, with the performance of 98.8% image-level AUROC and 99.4% pixel-level AUROC.