 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Pre-training Based on Graph Attention Network for Document Understanding
Paper and Code

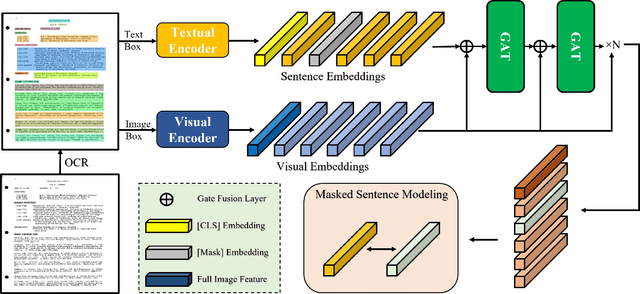
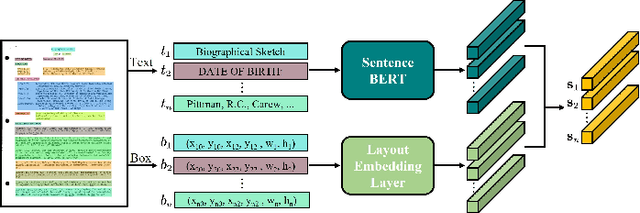
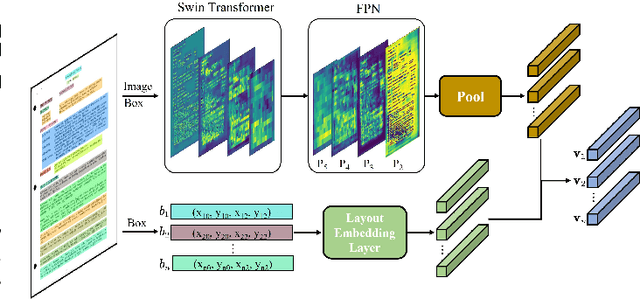
Document intelligence as a relatively new research topic supports many business applications. Its main task is to automatically read, understand, and analyze documents. However, due to the diversity of formats (invoices, reports, forms, etc.) and layouts in documents, it is difficult to make machines understand documents. In this paper, we present the GraphDoc, a multimodal graph attention-based model for various document understanding tasks. GraphDoc is pre-trained in a multimodal framework by utilizing text, layout, and image information simultaneously. In a document, a text block relies heavily on its surrounding contexts, so we inject the graph structure into the attention mechanism to form a graph attention layer so that each input node can only attend to its neighborhoods. The input nodes of each graph attention layer are composed of textual, visual, and positional features from semantically meaningful regions in a document image. We do the multimodal feature fusion of each node by the gate fusion layer. The contextualization between each node is modeled by the graph attention layer. GraphDoc learns a generic representation from only 320k unlabeled documents via the Masked Sentence Modeling task. Extensive experimental results on the publicly available datasets show that GraphDoc achieves state-of-the-art performance, which demonstrates the effectiveness of our proposed method.