 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deep Poincaré Map: A Novel Approach for Left Ventricle Segmentation
Oct 30, 2018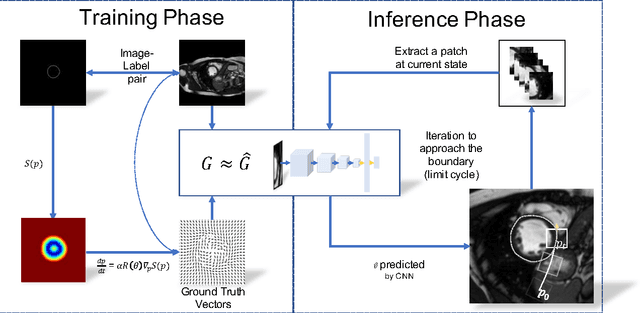
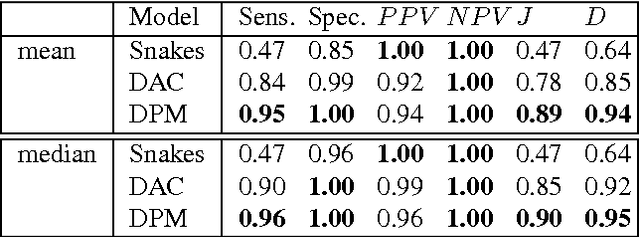
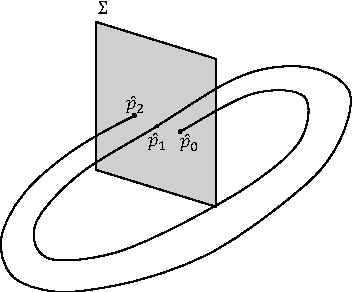
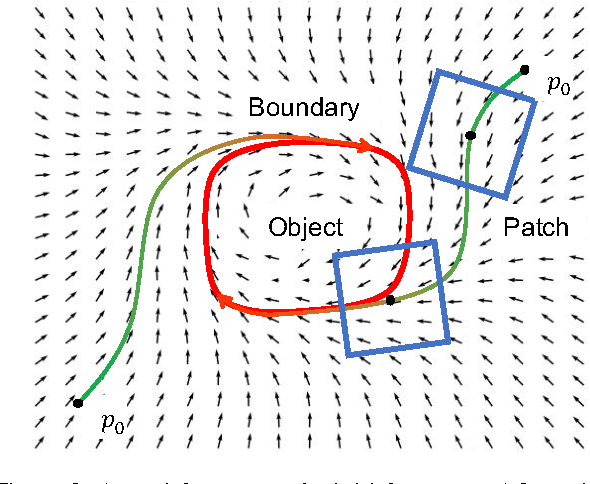
Precise segmentation of the left ventricle (LV) within cardiac MRI images is a prerequisite for the quantitative measurement of heart function. However, this task is challenging due to the limited availability of labeled data and motion artifacts from cardiac imaging. In this work, we present an iterative segmentation algorithm for LV delineation. By coupling deep learning with a novel dynamic-based labeling scheme, we present a new methodology where a policy model is learned to guide an agent to travel over the the image, tracing out a boundary of the ROI -- using the magnitude difference of the Poincar\'e map as a stopping criterion. Our method is evaluated on two datasets, namely the Sunnybrook Cardiac Dataset (SCD) and data from the STACOM 2011 LV segmentation challenge. Our method outperforms the previous research over many metrics. In order to demonstrate the transferability of our method we present encouraging results over the STACOM 2011 data, when using a model trained on the SCD dataset.
Deep Sequence Learning with Auxiliary Information for Traffic Prediction
Jun 13, 2018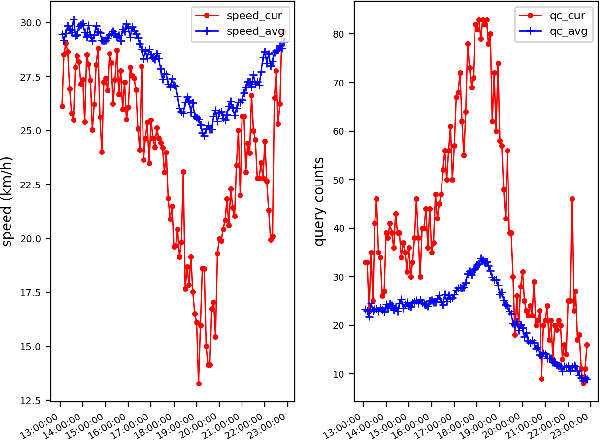

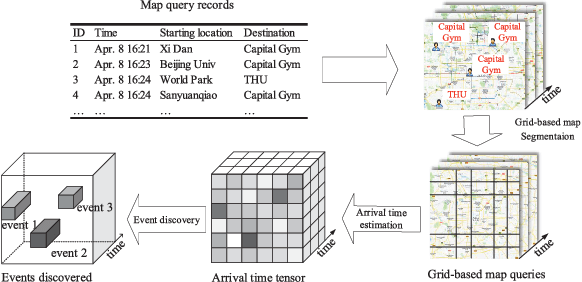
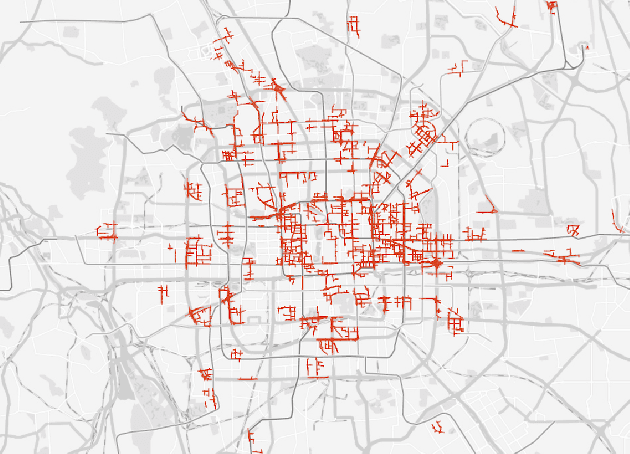
Predicting traffic conditions from online route queries is a challenging task as there are many complicated interactions over the roads and crowds involved. In this paper, we intend to improve traffic prediction by appropriate integration of three kinds of implicit but essential factors encoded in auxiliary information. We do this within an encoder-decoder sequence learning framework that integrates the following data: 1) offline geographical and social attributes. For example, the geographical structure of roads or public social events such as national celebrations; 2) road intersection information. In general, traffic congestion occurs at major junctions; 3) online crowd queries. For example, when many online queries issued for the same destination due to a public performance, the traffic around the destination will potentially become heavier at this location after a while. Qualitative and quantitative experiments on a real-world dataset from Baidu have demonstrated the effectiveness of our framework.
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
Jun 03, 2017
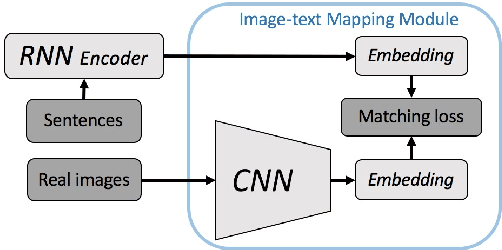
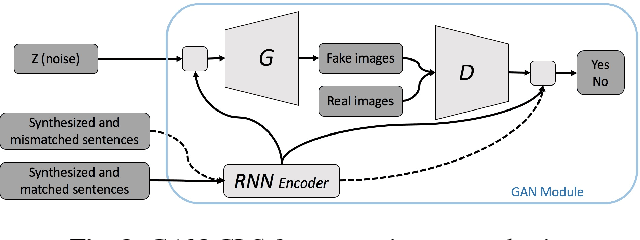
Translating information between text and image is a fundamental problem in artificial intelligence that connects natural language processing and computer vision. In the past few years, performance in image caption generation has seen significant improvement through the adoption of recurrent neural networks (RNN). Meanwhile, text-to-image generation begun to generate plausible images using datasets of specific categories like birds and flowers. We've even seen image generation from multi-category datasets such as the Microsoft Common Objects in Context (MSCOCO) through the use of generative adversarial networks (GANs). Synthesizing objects with a complex shape, however, is still challenging. For example, animals and humans have many degrees of freedom, which means that they can take on many complex shapes. We propose a new training method called Image-Text-Image (I2T2I) which integrates text-to-image and image-to-text (image captioning) synthesis to improve the performance of text-to-image synthesis. We demonstrate that %the capability of our method to understand the sentence descriptions, so as to I2T2I can generate better multi-categories images using MSCOCO than the state-of-the-art. We also demonstrate that I2T2I can achieve transfer learning by using a pre-trained image captioning module to generate human images on the MPII Human Pose