 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
Paper and Code

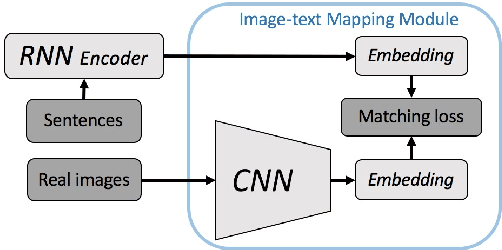
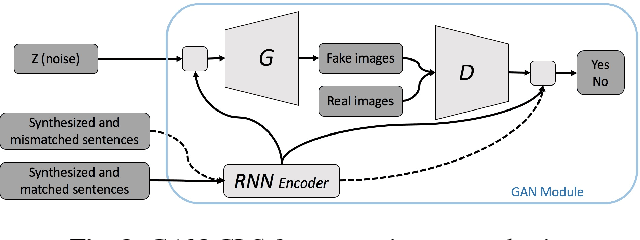
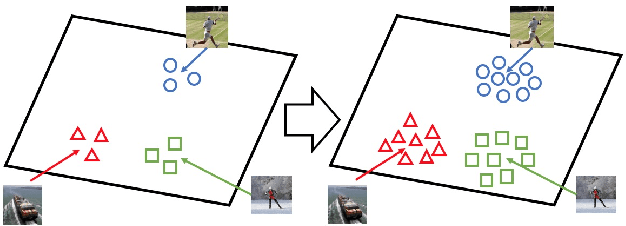
Translating information between text and image is a fundamental problem in artificial intelligence that connects natural language processing and computer vision. In the past few years, performance in image caption generation has seen significant improvement through the adoption of recurrent neural networks (RNN). Meanwhile, text-to-image generation begun to generate plausible images using datasets of specific categories like birds and flowers. We've even seen image generation from multi-category datasets such as the Microsoft Common Objects in Context (MSCOCO) through the use of generative adversarial networks (GANs). Synthesizing objects with a complex shape, however, is still challenging. For example, animals and humans have many degrees of freedom, which means that they can take on many complex shapes. We propose a new training method called Image-Text-Image (I2T2I) which integrates text-to-image and image-to-text (image captioning) synthesis to improve the performance of text-to-image synthesis. We demonstrate that %the capability of our method to understand the sentence descriptions, so as to I2T2I can generate better multi-categories images using MSCOCO than the state-of-the-art. We also demonstrate that I2T2I can achieve transfer learning by using a pre-trained image captioning module to generate human images on the MPII Human Pose