 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASA: Attack Agnostic Unsupervised Adversarial Detection using Prediction & Attribution Sensitivity Analysis
Apr 12, 2024



Deep neural networks for classification are vulnerable to adversarial attacks, where small perturbations to input samples lead to incorrect predictions. This susceptibility, combined with the black-box nature of such networks, limits their adoption in critical applications like autonomous driving. Feature-attribution-based explanation methods provide relevance of input features for model predictions on input samples, thus explaining model decisions. However, we observe that both model predictions and feature attributions for input samples are sensitive to noise. We develop a practical method for this characteristic of model prediction and feature attribution to detect adversarial samples. Our method, PASA, requires the computation of two test statistics using model prediction and feature attribution and can reliably detect adversarial samples using thresholds learned from benign samples. We validate our lightweight approach by evaluating the performance of PASA on varying strengths of FGSM, PGD, BIM, and CW attacks on multiple image and non-image datasets. On average, we outperform state-of-the-art statistical unsupervised adversarial detectors on CIFAR-10 and ImageNet by 14\% and 35\% ROC-AUC scores, respectively. Moreover, our approach demonstrates competitive performance even when an adversary is aware of the defense mechanism.
Invisible Reflections: Leveraging Infrared Laser Reflections to Target Traffic Sign Perception
Jan 07, 2024



All vehicles must follow the rules that govern traffic behavior, regardless of whether the vehicles are human-driven or Connected Autonomous Vehicles (CAVs). Road signs indicate locally active rules, such as speed limits and requirements to yield or stop. Recent research has demonstrated attacks, such as adding stickers or projected colored patches to signs, that cause CAV misinterpretation, resulting in potential safety issues. Humans can see and potentially defend against these attacks. But humans can not detect what they can not observe. We have developed an effective physical-world attack that leverages the sensitivity of filterless image sensors and the properties of Infrared Laser Reflections (ILRs), which are invisible to humans. The attack is designed to affect CAV cameras and perception, undermining traffic sign recognition by inducing misclassification. In this work, we formulate the threat model and requirements for an ILR-based traffic sign perception attack to succeed. We evaluate the effectiveness of the ILR attack with real-world experiments against two major traffic sign recognition architectures on four IR-sensitive cameras. Our black-box optimization methodology allows the attack to achieve up to a 100% attack success rate in indoor, static scenarios and a >80.5% attack success rate in our outdoor, moving vehicle scenarios. We find the latest state-of-the-art certifiable defense is ineffective against ILR attacks as it mis-certifies >33.5% of cases. To address this, we propose a detection strategy based on the physical properties of IR laser reflections which can detect 96% of ILR attacks.
Explaining RADAR features for detecting spoofing attacks in Connected Autonomous Vehicles
Mar 01, 2022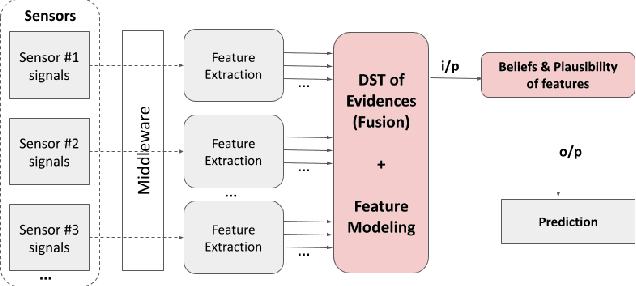

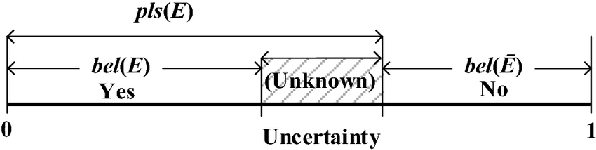

Connected autonomous vehicles (CAVs) are anticipated to have built-in AI systems for defending against cyberattacks. Machine learning (ML) models form the basis of many such AI systems. These models are notorious for acting like black boxes, transforming inputs into solutions with great accuracy, but no explanations support their decisions. Explanations are needed to communicate model performance, make decisions transparent, and establish trust in the models with stakeholders. Explanations can also indicate when humans must take control, for instance, when the ML model makes low confidence decisions or offers multiple or ambiguous alternatives. Explanations also provide evidence for post-incident forensic analysis. Research on explainable ML to security problems is limited, and more so concerning CAVs. This paper surfaces a critical yet under-researched sensor data \textit{uncertainty} problem for training ML attack detection models, especially in highly mobile and risk-averse platforms such as autonomous vehicles. We present a model that explains \textit{certainty} and \textit{uncertainty} in sensor input -- a missing characteristic in data collection. We hypothesize that model explanation is inaccurate for a given system without explainable input data quality. We estimate \textit{uncertainty} and mass functions for features in radar sensor data and incorporate them into the training model through experimental evaluation. The mass function allows the classifier to categorize all spoofed inputs accurately with an incorrect class label.