 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerva: Reinforcement Learning with Verifiable Rewards for Cyber Threat Intelligence LLMs
Jan 31, 2026Cyber threat intelligence (CTI) analysts routinely convert noisy, unstructured security artifacts into standardized, automation-ready representations. Although large language models (LLMs) show promise for this task, existing approaches remain brittle when producing structured CTI outputs and have largely relied on supervised fine-tuning (SFT). In contrast, CTI standards and community-maintained resources define canonical identifiers and schemas that enable deterministic verification of model outputs. We leverage this structure to study reinforcement learning with verifiable rewards (RLVR) for CTI tasks. We introduce \textit{Minerva}, a unified dataset and training pipeline spanning multiple CTI subtasks, each paired with task-specific verifiers that score structured outputs and identifier predictions. To address reward sparsity during rollout, we propose a lightweight self-training mechanism that generates additional verified trajectories and distills them back into the model. Experiments across LLM backbones show consistent improvements in accuracy and robustness over SFT across multiple benchmarks.
PROVEX: Enhancing SOC Analyst Trust with Explainable Provenance-Based IDS
Dec 20, 2025



Modern intrusion detection systems (IDS) leverage graph neural networks (GNNs) to detect malicious activity in system provenance data, but their decisions often remain a black box to analysts. This paper presents a comprehensive XAI framework designed to bridge the trust gap in Security Operations Centers (SOCs) by making graph-based detection transparent. We implement this framework on top of KAIROS, a state-of-the-art temporal graph-based IDS, though our design is applicable to any temporal graph-based detector with minimal adaptation. The complete codebase is available at https://github.com/devang1304/provex.git. We augment the detection pipeline with post-hoc explanations that highlight why an alert was triggered, identifying key causal subgraphs and events. We adapt three GNN explanation methods - GraphMask, GNNExplainer, and a variational temporal GNN explainer (VA-TGExplainer) - to the temporal provenance context. These tools output human-interpretable representations of anomalous behavior, including important edges and uncertainty estimates. Our contributions focus on the practical integration of these explainers, addressing challenges in memory management and reproducibility. We demonstrate our framework on the DARPA CADETS Engagement 3 dataset and show that it produces concise window-level explanations for detected attacks. Our evaluation reveals that the explainers preserve the TGNN's decisions with high fidelity, surfacing critical edges such as malicious file interactions and anomalous netflows. The average explanation overhead is 3-5 seconds per event. By providing insight into the model's reasoning, our framework aims to improve analyst trust and triage speed.
Adapting Large Language Models to Emerging Cybersecurity using Retrieval Augmented Generation
Oct 31, 2025Security applications are increasingly relying on large language models (LLMs) for cyber threat detection; however, their opaque reasoning often limits trust, particularly in decisions that require domain-specific cybersecurity knowledge. Because security threats evolve rapidly, LLMs must not only recall historical incidents but also adapt to emerging vulnerabilities and attack patterns. Retrieval-Augmented Generation (RAG) has demonstrated effectiveness in general LLM applications, but its potential for cybersecurity remains underexplored. In this work, we introduce a RAG-based framework designed to contextualize cybersecurity data and enhance LLM accuracy in knowledge retention and temporal reasoning. Using external datasets and the Llama-3-8B-Instruct model, we evaluate baseline RAG, an optimized hybrid retrieval approach, and conduct a comparative analysis across multiple performance metrics. Our findings highlight the promise of hybrid retrieval in strengthening the adaptability and reliability of LLMs for cybersecurity tasks.
Towards Understanding Self-play for LLM Reasoning
Oct 31, 2025Recent advances in large language model (LLM) reasoning, led by reinforcement learning with verifiable rewards (RLVR), have inspired self-play post-training, where models improve by generating and solving their own problems. While self-play has shown strong in-domain and out-of-domain gains, the mechanisms behind these improvements remain poorly understood. In this work, we analyze the training dynamics of self-play through the lens of the Absolute Zero Reasoner, comparing it against RLVR and supervised fine-tuning (SFT). Our study examines parameter update sparsity, entropy dynamics of token distributions, and alternative proposer reward functions. We further connect these dynamics to reasoning performance using pass@k evaluations. Together, our findings clarify how self-play differs from other post-training strategies, highlight its inherent limitations, and point toward future directions for improving LLM math reasoning through self-play.
Limits of Generalization in RLVR: Two Case Studies in Mathematical Reasoning
Oct 30, 2025Mathematical reasoning is a central challenge for large language models (LLMs), requiring not only correct answers but also faithful reasoning processes. Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising approach for enhancing such capabilities; however, its ability to foster genuine reasoning remains unclear. We investigate RLVR on two combinatorial problems with fully verifiable solutions: \emph{Activity Scheduling} and the \emph{Longest Increasing Subsequence}, using carefully curated datasets with unique optima. Across multiple reward designs, we find that RLVR improves evaluation metrics but often by reinforcing superficial heuristics rather than acquiring new reasoning strategies. These findings highlight the limits of RLVR generalization, emphasizing the importance of benchmarks that disentangle genuine mathematical reasoning from shortcut exploitation and provide faithful measures of progress. Code available at https://github.com/xashru/rlvr-seq-generalization.
Concept-Based Masking: A Patch-Agnostic Defense Against Adversarial Patch Attacks
Oct 05, 2025Adversarial patch attacks pose a practical threat to deep learning models by forcing targeted misclassifications through localized perturbations, often realized in the physical world. Existing defenses typically assume prior knowledge of patch size or location, limiting their applicability. In this work, we propose a patch-agnostic defense that leverages concept-based explanations to identify and suppress the most influential concept activation vectors, thereby neutralizing patch effects without explicit detection. Evaluated on Imagenette with a ResNet-50, our method achieves higher robust and clean accuracy than the state-of-the-art PatchCleanser, while maintaining strong performance across varying patch sizes and locations. Our results highlight the promise of combining interpretability with robustness and suggest concept-driven defenses as a scalable strategy for securing machine learning models against adversarial patch attacks.
Gun Detection Using Combined Human Pose and Weapon Appearance
Mar 15, 2025



The increasing frequency of firearm-related incidents has necessitated advancements in security and surveillance systems, particularly in firearm detection within public spaces. Traditional gun detection methods rely on manual inspections and continuous human monitoring of CCTV footage, which are labor-intensive and prone to high false positive and negative rates. To address these limitations, we propose a novel approach that integrates human pose estimation with weapon appearance recognition using deep learning techniques. Unlike prior studies that focus on either body pose estimation or firearm detection in isolation, our method jointly analyzes posture and weapon presence to enhance detection accuracy in real-world, dynamic environments. To train our model, we curated a diverse dataset comprising images from open-source repositories such as IMFDB and Monash Guns, supplemented with AI-generated and manually collected images from web sources. This dataset ensures robust generalization and realistic performance evaluation under various surveillance conditions. Our research aims to improve the precision and reliability of firearm detection systems, contributing to enhanced public safety and threat mitigation in high-risk areas.
Survey Perspective: The Role of Explainable AI in Threat Intelligence
Mar 03, 2025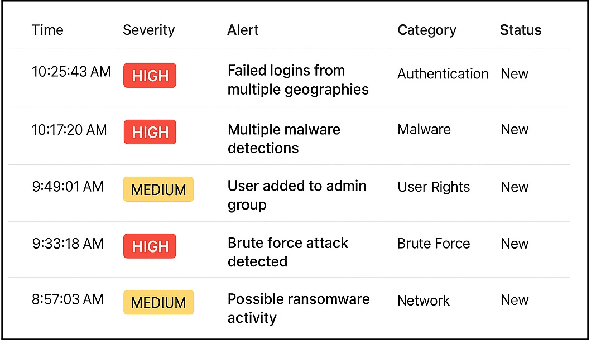



The increasing reliance on AI-based security tools in Security Operations Centers (SOCs) has transformed threat detection and response, yet analysts frequently struggle with alert overload, false positives, and lack of contextual relevance. The inability to effectively analyze AI-generated security alerts lead to inefficiencies in incident response and reduces trust in automated decision-making. In this paper, we show results and analysis of our investigation of how SOC analysts navigate AI-based alerts, their challenges with current security tools, and how explainability (XAI) integrated into their security workflows has the potential to become an effective decision support. In this vein, we conducted an industry survey. Using the survey responses, we analyze how security analysts' process, retrieve, and prioritize alerts. Our findings indicate that most analysts have not yet adopted XAI-integrated tools, but they express high interest in attack attribution, confidence scores, and feature contribution explanations to improve interpretability, and triage efficiency. Based on our findings, we also propose practical design recommendations for XAI-enhanced security alert systems, enabling AI-based cybersecurity solutions to be more transparent, interpretable, and actionable.
Revisiting Static Feature-Based Android Malware Detection
Sep 11, 2024The increasing reliance on machine learning (ML) in computer security, particularly for malware classification, has driven significant advancements. However, the replicability and reproducibility of these results are often overlooked, leading to challenges in verifying research findings. This paper highlights critical pitfalls that undermine the validity of ML research in Android malware detection, focusing on dataset and methodological issues. We comprehensively analyze Android malware detection using two datasets and assess offline and continual learning settings with six widely used ML models. Our study reveals that when properly tuned, simpler baseline methods can often outperform more complex models. To address reproducibility challenges, we propose solutions for improving datasets and methodological practices, enabling fairer model comparisons. Additionally, we open-source our code to facilitate malware analysis, making it extensible for new models and datasets. Our paper aims to support future research in Android malware detection and other security domains, enhancing the reliability and reproducibility of published results.
Actionable Cyber Threat Intelligence using Knowledge Graphs and Large Language Models
Jun 30, 2024



Cyber threats are constantly evolving. Extracting actionable insights from unstructured Cyber Threat Intelligence (CTI) data is essential to guide cybersecurity decisions. Increasingly, organizations like Microsoft, Trend Micro, and CrowdStrike are using generative AI to facilitate CTI extraction. This paper addresses the challenge of automating the extraction of actionable CTI using advancements in Large Language Models (LLMs) and Knowledge Graphs (KGs). We explore the application of state-of-the-art open-source LLMs, including the Llama 2 series, Mistral 7B Instruct, and Zephyr for extracting meaningful triples from CTI texts. Our methodology evaluates techniques such as prompt engineering, the guidance framework, and fine-tuning to optimize information extraction and structuring. The extracted data is then utilized to construct a KG, offering a structured and queryable representation of threat intelligence. Experimental results demonstrate the effectiveness of our approach in extracting relevant information, with guidance and fine-tuning showing superior performance over prompt engineering. However, while our methods prove effective in small-scale tests, applying LLMs to large-scale data for KG construction and Link Prediction presents ongoing challenges.