 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECURE: Benchmarking Generative Large Language Models for Cybersecurity Advisory
May 30, 2024Large Language Models (LLMs) have demonstrated potential in cybersecurity applications but have also caused lower confidence due to problems like hallucinations and a lack of truthfulness. Existing benchmarks provide general evaluations but do not sufficiently address the practical and applied aspects of LLM performance in cybersecurity-specific tasks. To address this gap, we introduce the SECURE (Security Extraction, Understanding \& Reasoning Evaluation), a benchmark designed to assess LLMs performance in realistic cybersecurity scenarios. SECURE includes six datasets focussed on the Industrial Control System sector to evaluate knowledge extraction, understanding, and reasoning based on industry-standard sources. Our study evaluates seven state-of-the-art models on these tasks, providing insights into their strengths and weaknesses in cybersecurity contexts, and offer recommendations for improving LLMs reliability as cyber advisory tools.
MORPH: Towards Automated Concept Drift Adaptation for Malware Detection
Jan 23, 2024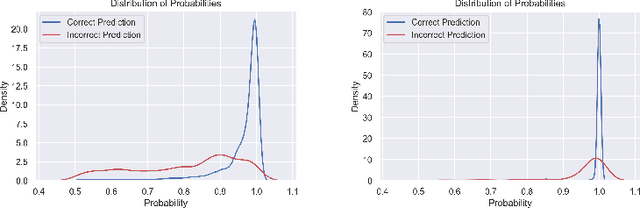

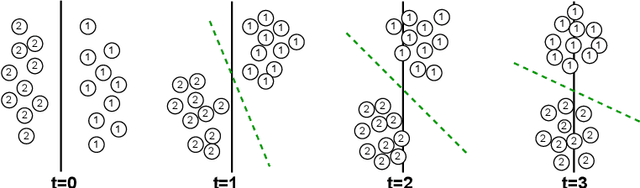
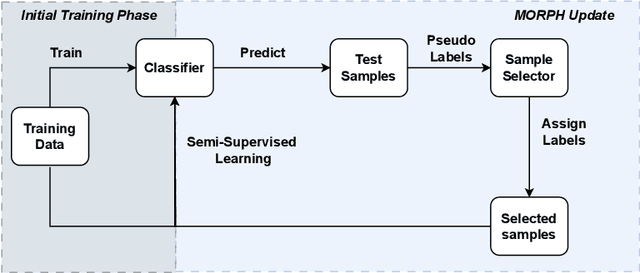
Concept drift is a significant challenge for malware detection, as the performance of trained machine learning models degrades over time, rendering them impractical. While prior research in malware concept drift adaptation has primarily focused on active learning, which involves selecting representative samples to update the model, self-training has emerged as a promising approach to mitigate concept drift. Self-training involves retraining the model using pseudo labels to adapt to shifting data distributions. In this research, we propose MORPH -- an effective pseudo-label-based concept drift adaptation method specifically designed for neural networks. Through extensive experimental analysis of Android and Windows malware datasets, we demonstrate the efficacy of our approach in mitigating the impact of concept drift. Our method offers the advantage of reducing annotation efforts when combined with active learning. Furthermore, our method significantly improves over existing works in automated concept drift adaptation for malware detection.