 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Framework for Video-Derived Respiratory Signals
Dec 16, 2025
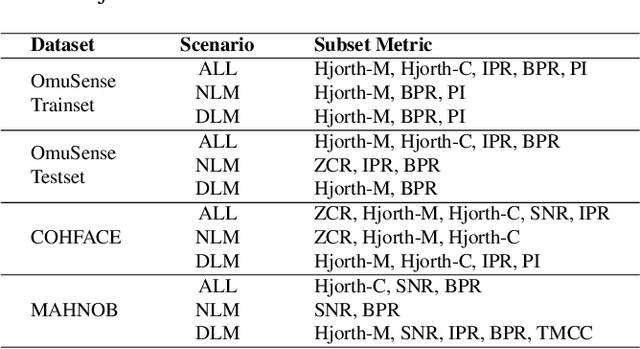
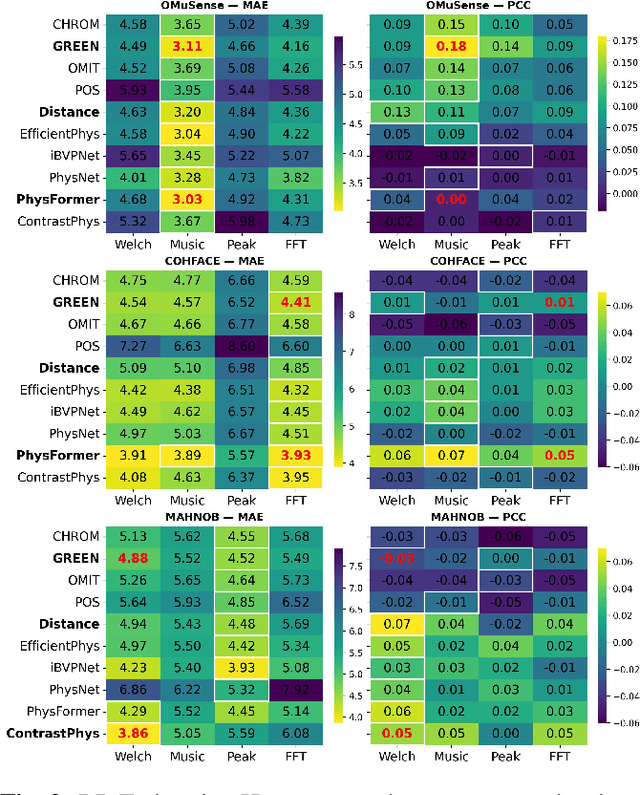
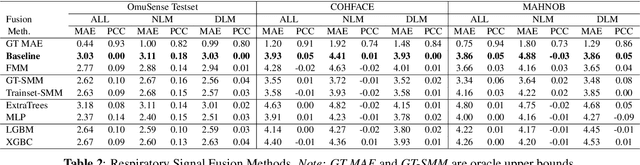
Video-based respiratory rate (RR) estimation is often unreliable due to inconsistent signal quality across extraction methods. We present a predictive, quality-aware framework that integrates heterogeneous signal sources with dynamic assessment of reliability. Ten signals are extracted from facial remote photoplethysmography (rPPG), upper-body motion, and deep learning pipelines, and analyzed using four spectral estimators: Welch's method, Multiple Signal Classification (MUSIC), Fast Fourier Transform (FFT), and peak detection. Segment-level quality indices are then used to train machine learning models that predict accuracy or select the most reliable signal. This enables adaptive signal fusion and quality-based segment filtering. Experiments on three public datasets (OMuSense-23, COHFACE, MAHNOB-HCI) show that the proposed framework achieves lower RR estimation errors than individual methods in most cases, with performance gains depending on dataset characteristics. These findings highlight the potential of quality-driven predictive modeling to deliver scalable and generalizable video-based respiratory monitoring solutions.
Survey Perspective: The Role of Explainable AI in Threat Intelligence
Mar 03, 2025



The increasing reliance on AI-based security tools in Security Operations Centers (SOCs) has transformed threat detection and response, yet analysts frequently struggle with alert overload, false positives, and lack of contextual relevance. The inability to effectively analyze AI-generated security alerts lead to inefficiencies in incident response and reduces trust in automated decision-making. In this paper, we show results and analysis of our investigation of how SOC analysts navigate AI-based alerts, their challenges with current security tools, and how explainability (XAI) integrated into their security workflows has the potential to become an effective decision support. In this vein, we conducted an industry survey. Using the survey responses, we analyze how security analysts' process, retrieve, and prioritize alerts. Our findings indicate that most analysts have not yet adopted XAI-integrated tools, but they express high interest in attack attribution, confidence scores, and feature contribution explanations to improve interpretability, and triage efficiency. Based on our findings, we also propose practical design recommendations for XAI-enhanced security alert systems, enabling AI-based cybersecurity solutions to be more transparent, interpretable, and actionable.
CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Jun 11, 2024
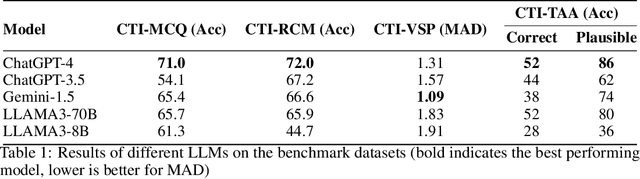
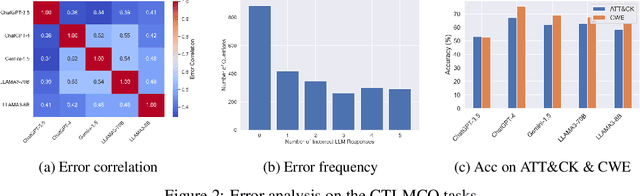
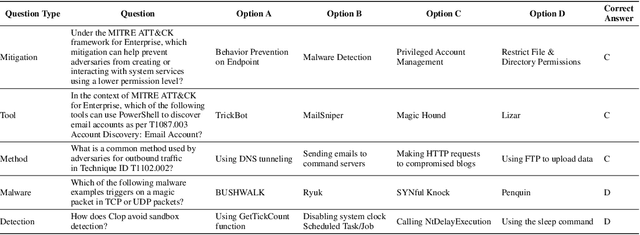
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
SECURE: Benchmarking Generative Large Language Models for Cybersecurity Advisory
May 30, 2024Large Language Models (LLMs) have demonstrated potential in cybersecurity applications but have also caused lower confidence due to problems like hallucinations and a lack of truthfulness. Existing benchmarks provide general evaluations but do not sufficiently address the practical and applied aspects of LLM performance in cybersecurity-specific tasks. To address this gap, we introduce the SECURE (Security Extraction, Understanding \& Reasoning Evaluation), a benchmark designed to assess LLMs performance in realistic cybersecurity scenarios. SECURE includes six datasets focussed on the Industrial Control System sector to evaluate knowledge extraction, understanding, and reasoning based on industry-standard sources. Our study evaluates seven state-of-the-art models on these tasks, providing insights into their strengths and weaknesses in cybersecurity contexts, and offer recommendations for improving LLMs reliability as cyber advisory tools.
Evaluation of Video-Based rPPG in Challenging Environments: Artifact Mitigation and Network Resilience
May 02, 2024Video-based remote photoplethysmography (rPPG) has emerged as a promising technology for non-contact vital sign monitoring, especially under controlled conditions. However, the accurate measurement of vital signs in real-world scenarios faces several challenges, including artifacts induced by videocodecs, low-light noise, degradation, low dynamic range, occlusions, and hardware and network constraints. In this article, we systematically investigate comprehensive investigate these issues, measuring their detrimental effects on the quality of rPPG measurements. Additionally, we propose practical strategies for mitigating these challenges to improve the dependability and resilience of video-based rPPG systems. We detail methods for effective biosignal recovery in the presence of network limitations and present denoising and inpainting techniques aimed at preserving video frame integrity. Through extensive evaluations and direct comparisons, we demonstrate the effectiveness of the approaches in enhancing rPPG measurements under challenging environments, contributing to the development of more reliable and effective remote vital sign monitoring technologies.
Estimating exercise-induced fatigue from thermal facial images
Sep 12, 2023



Exercise-induced fatigue resulting from physical activity can be an early indicator of overtraining, illness, or other health issues. In this article, we present an automated method for estimating exercise-induced fatigue levels through the use of thermal imaging and facial analysis techniques utilizing deep learning models. Leveraging a novel dataset comprising over 400,000 thermal facial images of rested and fatigued users, our results suggest that exercise-induced fatigue levels could be predicted with only one static thermal frame with an average error smaller than 15\%. The results emphasize the viability of using thermal imaging in conjunction with deep learning for reliable exercise-induced fatigue estimation.
Non-Contact Heart Rate Measurement from Deteriorated Videos
Apr 28, 2023Remote photoplethysmography (rPPG) offers a state-of-the-art, non-contact methodology for estimating human pulse by analyzing facial videos. Despite its potential, rPPG methods can be susceptible to various artifacts, such as noise, occlusions, and other obstructions caused by sunglasses, masks, or even involuntary facial contact, such as individuals inadvertently touching their faces. In this study, we apply image processing transformations to intentionally degrade video quality, mimicking these challenging conditions, and subsequently evaluate the performance of both non-learning and learning-based rPPG methods on the deteriorated data. Our results reveal a significant decrease in accuracy in the presence of these artifacts, prompting us to propose the application of restoration techniques, such as denoising and inpainting, to improve heart-rate estimation outcomes. By addressing these challenging conditions and occlusion artifacts, our approach aims to make rPPG methods more robust and adaptable to real-world situations. To assess the effectiveness of our proposed methods, we undertake comprehensive experiments on three publicly available datasets, encompassing a wide range of scenarios and artifact types. Our findings underscore the potential to construct a robust rPPG system by employing an optimal combination of restoration algorithms and rPPG techniques. Moreover, our study contributes to the advancement of privacy-conscious rPPG methodologies, thereby bolstering the overall utility and impact of this innovative technology in the field of remote heart-rate estimation under realistic and diverse conditions.
Improving Depression estimation from facial videos with face alignment, training optimization and scheduling
Dec 13, 2022Deep learning models have shown promising results in recognizing depressive states using video-based facial expressions. While successful models typically leverage using 3D-CNNs or video distillation techniques, the different use of pretraining, data augmentation, preprocessing, and optimization techniques across experiments makes it difficult to make fair architectural comparisons. We propose instead to enhance two simple models based on ResNet-50 that use only static spatial information by using two specific face alignment methods and improved data augmentation, optimization, and scheduling techniques. Our extensive experiments on benchmark datasets obtain similar results to sophisticated spatio-temporal models for single streams, while the score-level fusion of two different streams outperforms state-of-the-art methods. Our findings suggest that specific modifications in the preprocessing and training process result in noticeable differences in the performance of the models and could hide the actual originally attributed to the use of different neural network architectures.