 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerva: Reinforcement Learning with Verifiable Rewards for Cyber Threat Intelligence LLMs
Jan 31, 2026Cyber threat intelligence (CTI) analysts routinely convert noisy, unstructured security artifacts into standardized, automation-ready representations. Although large language models (LLMs) show promise for this task, existing approaches remain brittle when producing structured CTI outputs and have largely relied on supervised fine-tuning (SFT). In contrast, CTI standards and community-maintained resources define canonical identifiers and schemas that enable deterministic verification of model outputs. We leverage this structure to study reinforcement learning with verifiable rewards (RLVR) for CTI tasks. We introduce \textit{Minerva}, a unified dataset and training pipeline spanning multiple CTI subtasks, each paired with task-specific verifiers that score structured outputs and identifier predictions. To address reward sparsity during rollout, we propose a lightweight self-training mechanism that generates additional verified trajectories and distills them back into the model. Experiments across LLM backbones show consistent improvements in accuracy and robustness over SFT across multiple benchmarks.
Adapting Large Language Models to Emerging Cybersecurity using Retrieval Augmented Generation
Oct 31, 2025Security applications are increasingly relying on large language models (LLMs) for cyber threat detection; however, their opaque reasoning often limits trust, particularly in decisions that require domain-specific cybersecurity knowledge. Because security threats evolve rapidly, LLMs must not only recall historical incidents but also adapt to emerging vulnerabilities and attack patterns. Retrieval-Augmented Generation (RAG) has demonstrated effectiveness in general LLM applications, but its potential for cybersecurity remains underexplored. In this work, we introduce a RAG-based framework designed to contextualize cybersecurity data and enhance LLM accuracy in knowledge retention and temporal reasoning. Using external datasets and the Llama-3-8B-Instruct model, we evaluate baseline RAG, an optimized hybrid retrieval approach, and conduct a comparative analysis across multiple performance metrics. Our findings highlight the promise of hybrid retrieval in strengthening the adaptability and reliability of LLMs for cybersecurity tasks.
Towards Understanding Self-play for LLM Reasoning
Oct 31, 2025Recent advances in large language model (LLM) reasoning, led by reinforcement learning with verifiable rewards (RLVR), have inspired self-play post-training, where models improve by generating and solving their own problems. While self-play has shown strong in-domain and out-of-domain gains, the mechanisms behind these improvements remain poorly understood. In this work, we analyze the training dynamics of self-play through the lens of the Absolute Zero Reasoner, comparing it against RLVR and supervised fine-tuning (SFT). Our study examines parameter update sparsity, entropy dynamics of token distributions, and alternative proposer reward functions. We further connect these dynamics to reasoning performance using pass@k evaluations. Together, our findings clarify how self-play differs from other post-training strategies, highlight its inherent limitations, and point toward future directions for improving LLM math reasoning through self-play.
Limits of Generalization in RLVR: Two Case Studies in Mathematical Reasoning
Oct 30, 2025Mathematical reasoning is a central challenge for large language models (LLMs), requiring not only correct answers but also faithful reasoning processes. Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising approach for enhancing such capabilities; however, its ability to foster genuine reasoning remains unclear. We investigate RLVR on two combinatorial problems with fully verifiable solutions: \emph{Activity Scheduling} and the \emph{Longest Increasing Subsequence}, using carefully curated datasets with unique optima. Across multiple reward designs, we find that RLVR improves evaluation metrics but often by reinforcing superficial heuristics rather than acquiring new reasoning strategies. These findings highlight the limits of RLVR generalization, emphasizing the importance of benchmarks that disentangle genuine mathematical reasoning from shortcut exploitation and provide faithful measures of progress. Code available at https://github.com/xashru/rlvr-seq-generalization.
Revisiting Static Feature-Based Android Malware Detection
Sep 11, 2024The increasing reliance on machine learning (ML) in computer security, particularly for malware classification, has driven significant advancements. However, the replicability and reproducibility of these results are often overlooked, leading to challenges in verifying research findings. This paper highlights critical pitfalls that undermine the validity of ML research in Android malware detection, focusing on dataset and methodological issues. We comprehensively analyze Android malware detection using two datasets and assess offline and continual learning settings with six widely used ML models. Our study reveals that when properly tuned, simpler baseline methods can often outperform more complex models. To address reproducibility challenges, we propose solutions for improving datasets and methodological practices, enabling fairer model comparisons. Additionally, we open-source our code to facilitate malware analysis, making it extensible for new models and datasets. Our paper aims to support future research in Android malware detection and other security domains, enhancing the reliability and reproducibility of published results.
Actionable Cyber Threat Intelligence using Knowledge Graphs and Large Language Models
Jun 30, 2024



Cyber threats are constantly evolving. Extracting actionable insights from unstructured Cyber Threat Intelligence (CTI) data is essential to guide cybersecurity decisions. Increasingly, organizations like Microsoft, Trend Micro, and CrowdStrike are using generative AI to facilitate CTI extraction. This paper addresses the challenge of automating the extraction of actionable CTI using advancements in Large Language Models (LLMs) and Knowledge Graphs (KGs). We explore the application of state-of-the-art open-source LLMs, including the Llama 2 series, Mistral 7B Instruct, and Zephyr for extracting meaningful triples from CTI texts. Our methodology evaluates techniques such as prompt engineering, the guidance framework, and fine-tuning to optimize information extraction and structuring. The extracted data is then utilized to construct a KG, offering a structured and queryable representation of threat intelligence. Experimental results demonstrate the effectiveness of our approach in extracting relevant information, with guidance and fine-tuning showing superior performance over prompt engineering. However, while our methods prove effective in small-scale tests, applying LLMs to large-scale data for KG construction and Link Prediction presents ongoing challenges.
CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Jun 11, 2024
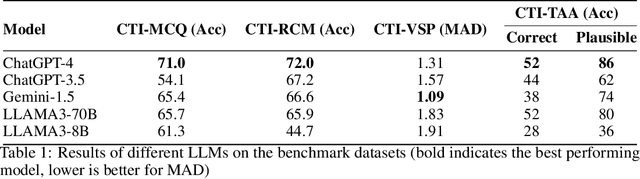
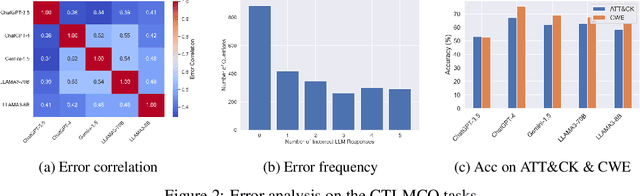
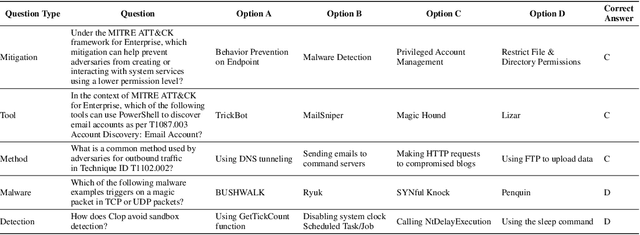
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
SECURE: Benchmarking Generative Large Language Models for Cybersecurity Advisory
May 30, 2024Large Language Models (LLMs) have demonstrated potential in cybersecurity applications but have also caused lower confidence due to problems like hallucinations and a lack of truthfulness. Existing benchmarks provide general evaluations but do not sufficiently address the practical and applied aspects of LLM performance in cybersecurity-specific tasks. To address this gap, we introduce the SECURE (Security Extraction, Understanding \& Reasoning Evaluation), a benchmark designed to assess LLMs performance in realistic cybersecurity scenarios. SECURE includes six datasets focussed on the Industrial Control System sector to evaluate knowledge extraction, understanding, and reasoning based on industry-standard sources. Our study evaluates seven state-of-the-art models on these tasks, providing insights into their strengths and weaknesses in cybersecurity contexts, and offer recommendations for improving LLMs reliability as cyber advisory tools.
PASA: Attack Agnostic Unsupervised Adversarial Detection using Prediction & Attribution Sensitivity Analysis
Apr 12, 2024



Deep neural networks for classification are vulnerable to adversarial attacks, where small perturbations to input samples lead to incorrect predictions. This susceptibility, combined with the black-box nature of such networks, limits their adoption in critical applications like autonomous driving. Feature-attribution-based explanation methods provide relevance of input features for model predictions on input samples, thus explaining model decisions. However, we observe that both model predictions and feature attributions for input samples are sensitive to noise. We develop a practical method for this characteristic of model prediction and feature attribution to detect adversarial samples. Our method, PASA, requires the computation of two test statistics using model prediction and feature attribution and can reliably detect adversarial samples using thresholds learned from benign samples. We validate our lightweight approach by evaluating the performance of PASA on varying strengths of FGSM, PGD, BIM, and CW attacks on multiple image and non-image datasets. On average, we outperform state-of-the-art statistical unsupervised adversarial detectors on CIFAR-10 and ImageNet by 14\% and 35\% ROC-AUC scores, respectively. Moreover, our approach demonstrates competitive performance even when an adversary is aware of the defense mechanism.
MORPH: Towards Automated Concept Drift Adaptation for Malware Detection
Jan 23, 2024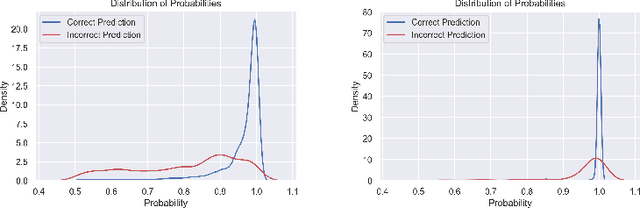

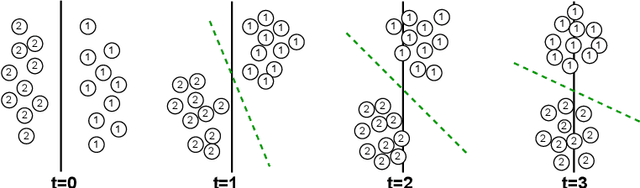
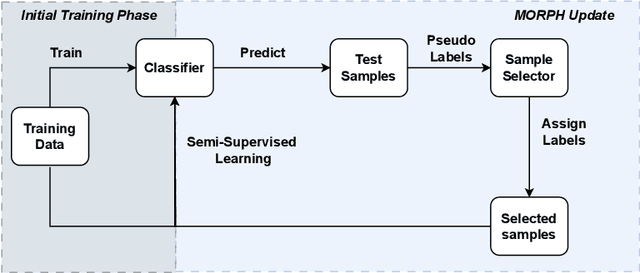
Concept drift is a significant challenge for malware detection, as the performance of trained machine learning models degrades over time, rendering them impractical. While prior research in malware concept drift adaptation has primarily focused on active learning, which involves selecting representative samples to update the model, self-training has emerged as a promising approach to mitigate concept drift. Self-training involves retraining the model using pseudo labels to adapt to shifting data distributions. In this research, we propose MORPH -- an effective pseudo-label-based concept drift adaptation method specifically designed for neural networks. Through extensive experimental analysis of Android and Windows malware datasets, we demonstrate the efficacy of our approach in mitigating the impact of concept drift. Our method offers the advantage of reducing annotation efforts when combined with active learning. Furthermore, our method significantly improves over existing works in automated concept drift adaptation for malware detection.