 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining RADAR features for detecting spoofing attacks in Connected Autonomous Vehicles
Paper and Code
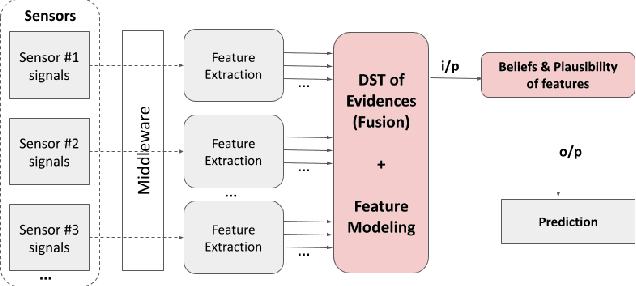

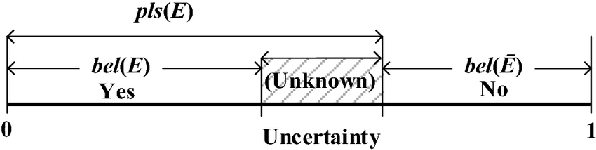

Connected autonomous vehicles (CAVs) are anticipated to have built-in AI systems for defending against cyberattacks. Machine learning (ML) models form the basis of many such AI systems. These models are notorious for acting like black boxes, transforming inputs into solutions with great accuracy, but no explanations support their decisions. Explanations are needed to communicate model performance, make decisions transparent, and establish trust in the models with stakeholders. Explanations can also indicate when humans must take control, for instance, when the ML model makes low confidence decisions or offers multiple or ambiguous alternatives. Explanations also provide evidence for post-incident forensic analysis. Research on explainable ML to security problems is limited, and more so concerning CAVs. This paper surfaces a critical yet under-researched sensor data \textit{uncertainty} problem for training ML attack detection models, especially in highly mobile and risk-averse platforms such as autonomous vehicles. We present a model that explains \textit{certainty} and \textit{uncertainty} in sensor input -- a missing characteristic in data collection. We hypothesize that model explanation is inaccurate for a given system without explainable input data quality. We estimate \textit{uncertainty} and mass functions for features in radar sensor data and incorporate them into the training model through experimental evaluation. The mass function allows the classifier to categorize all spoofed inputs accurately with an incorrect class label.