 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlterMOMA: Fusion Redundancy Pruning for Camera-LiDAR Fusion Models with Alternative Modality Masking
Sep 26, 2024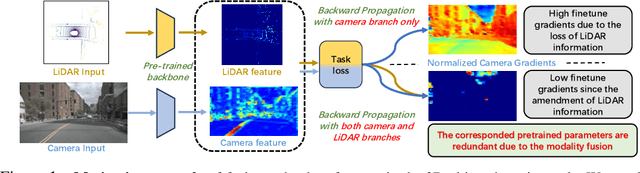

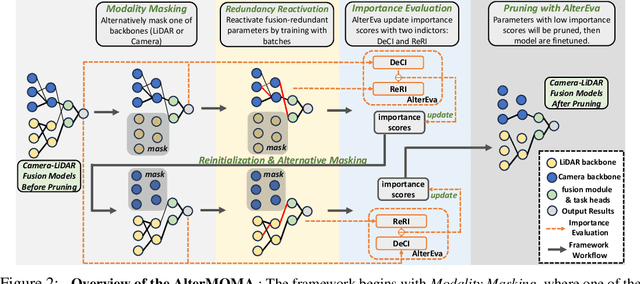

Camera-LiDAR fusion models significantly enhance perception performance in autonomous driving. The fusion mechanism leverages the strengths of each modality while minimizing their weaknesses. Moreover, in practice, camera-LiDAR fusion models utilize pre-trained backbones for efficient training. However, we argue that directly loading single-modal pre-trained camera and LiDAR backbones into camera-LiDAR fusion models introduces similar feature redundancy across modalities due to the nature of the fusion mechanism. Unfortunately, existing pruning methods are developed explicitly for single-modal models, and thus, they struggle to effectively identify these specific redundant parameters in camera-LiDAR fusion models. In this paper, to address the issue above on camera-LiDAR fusion models, we propose a novelty pruning framework Alternative Modality Masking Pruning (AlterMOMA), which employs alternative masking on each modality and identifies the redundant parameters. Specifically, when one modality parameters are masked (deactivated), the absence of features from the masked backbone compels the model to reactivate previous redundant features of the other modality backbone. Therefore, these redundant features and relevant redundant parameters can be identified via the reactivation process. The redundant parameters can be pruned by our proposed importance score evaluation function, Alternative Evaluation (AlterEva), which is based on the observation of the loss changes when certain modality parameters are activated and deactivated. Extensive experiments on the nuScene and KITTI datasets encompassing diverse tasks, baseline models, and pruning algorithms showcase that AlterMOMA outperforms existing pruning methods, attaining state-of-the-art performance.
RAANet: Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Density Level Estimation
Nov 18, 2021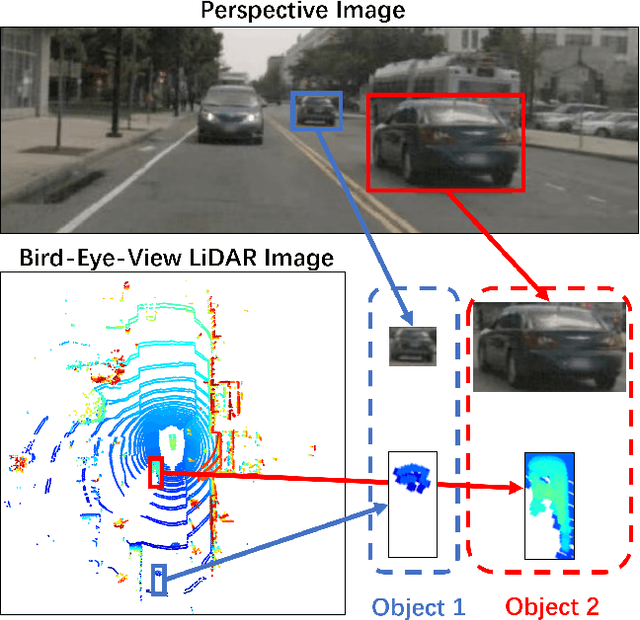
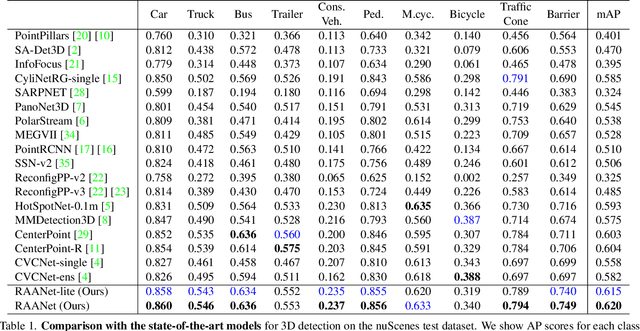


3D object detection from LiDAR data for autonomous driving has been making remarkable strides in recent years. Among the state-of-the-art methodologies, encoding point clouds into a bird's-eye view (BEV) has been demonstrated to be both effective and efficient. Different from perspective views, BEV preserves rich spatial and distance information between objects; and while farther objects of the same type do not appear smaller in the BEV, they contain sparser point cloud features. This fact weakens BEV feature extraction using shared-weight convolutional neural networks. In order to address this challenge, we propose Range-Aware Attention Network (RAANet), which extracts more powerful BEV features and generates superior 3D object detections. The range-aware attention (RAA) convolutions significantly improve feature extraction for near as well as far objects. Moreover, we propose a novel auxiliary loss for density estimation to further enhance the detection accuracy of RAANet for occluded objects. It is worth to note that our proposed RAA convolution is lightweight and compatible to be integrated into any CNN architecture used for the BEV detection. Extensive experiments on the nuScenes dataset demonstrate that our proposed approach outperforms the state-of-the-art methods for LiDAR-based 3D object detection, with real-time inference speed of 16 Hz for the full version and 22 Hz for the lite version. The code is publicly available at an anonymous Github repository https://github.com/anonymous0522/RAAN.
Towards Practical Lottery Ticket Hypothesis for Adversarial Training
Mar 06, 2020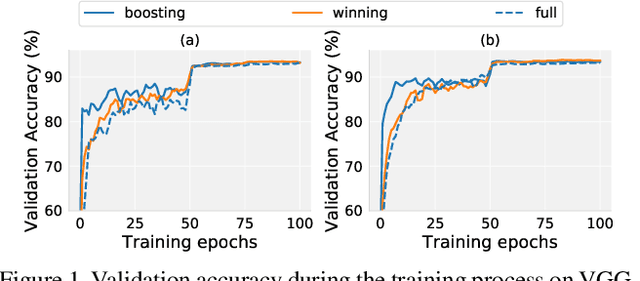

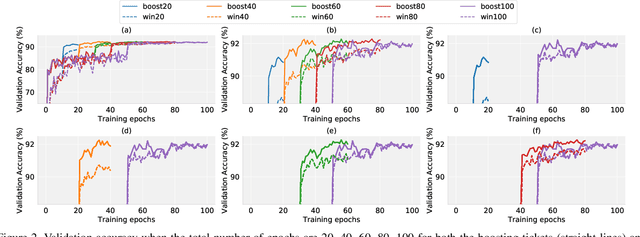

Recent research has proposed the lottery ticket hypothesis, suggesting that for a deep neural network, there exist trainable sub-networks performing equally or better than the original model with commensurate training steps. While this discovery is insightful, finding proper sub-networks requires iterative training and pruning. The high cost incurred limits the applications of the lottery ticket hypothesis. We show there exists a subset of the aforementioned sub-networks that converge significantly faster during the training process and thus can mitigate the cost issue. We conduct extensive experiments to show such sub-networks consistently exist across various model structures for a restrictive setting of hyperparameters ($e.g.$, carefully selected learning rate, pruning ratio, and model capacity). As a practical application of our findings, we demonstrate that such sub-networks can help in cutting down the total time of adversarial training, a standard approach to improve robustness, by up to 49\% on CIFAR-10 to achieve the state-of-the-art robustness.
Enhancing Cross-task Black-Box Transferability of Adversarial Examples with Dispersion Reduction
Nov 22, 2019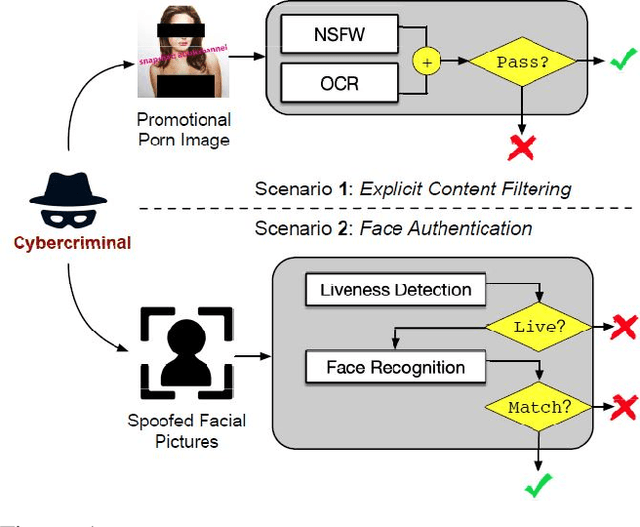
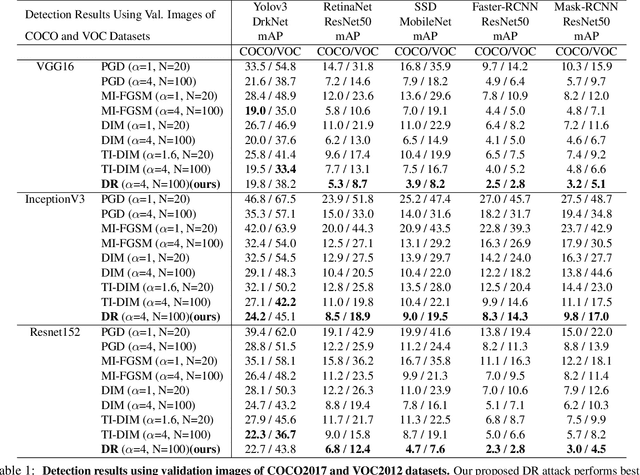
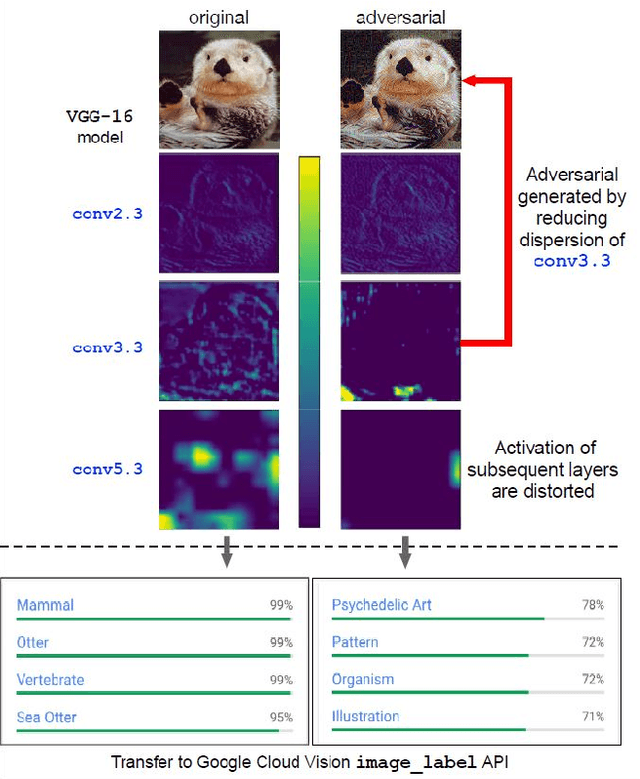

Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they remain adversarial even against other models. Although great efforts have been delved into the transferability across models, surprisingly, less attention has been paid to the cross-task transferability, which represents the real-world cybercriminal's situation, where an ensemble of different defense/detection mechanisms need to be evaded all at once. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, object detection, semantic segmentation, explicit content detection, and text detection. Our proposed attack minimizes the ``dispersion'' of the internal feature map, which overcomes existing attacks' limitation of requiring task-specific loss functions and/or probing a target model. We conduct evaluation on open source detection and segmentation models as well as four different computer vision tasks provided by Google Cloud Vision (GCV) APIs, to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations linf=16.
Fooling Detection Alone is Not Enough: First Adversarial Attack against Multiple Object Tracking
May 30, 2019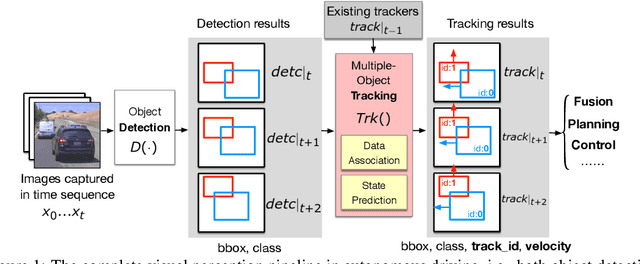
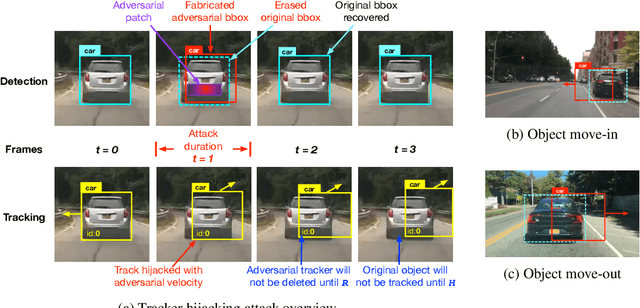
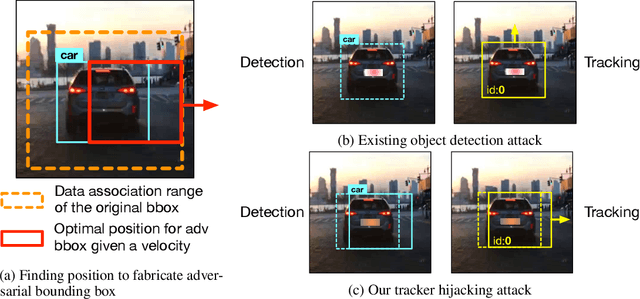
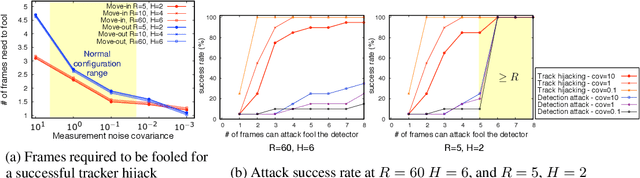
Recent work in adversarial machine learning started to focus on the visual perception in autonomous driving and studied Adversarial Examples (AEs) for object detection models. However, in such visual perception pipeline the detected objects must also be tracked, in a process called Multiple Object Tracking (MOT), to build the moving trajectories of surrounding obstacles. Since MOT is designed to be robust against errors in object detection, it poses a general challenge to existing attack techniques that blindly target objection detection: we find that a success rate of over 98% is needed for them to actually affect the tracking results, a requirement that no existing attack technique can satisfy. In this paper, we are the first to study adversarial machine learning attacks against the complete visual perception pipeline in autonomous driving, and discover a novel attack technique, tracker hijacking, that can effectively fool MOT using AEs on object detection. Using our technique, successful AEs on as few as one single frame can move an existing object in to or out of the headway of an autonomous vehicle to cause potential safety hazards. We perform evaluation using the Berkeley Deep Drive dataset and find that on average when 3 frames are attacked, our attack can have a nearly 100% success rate while attacks that blindly target object detection only have up to 25%.
Autonomous Human Activity Classification from Ego-vision Camera and Accelerometer Data
May 28, 2019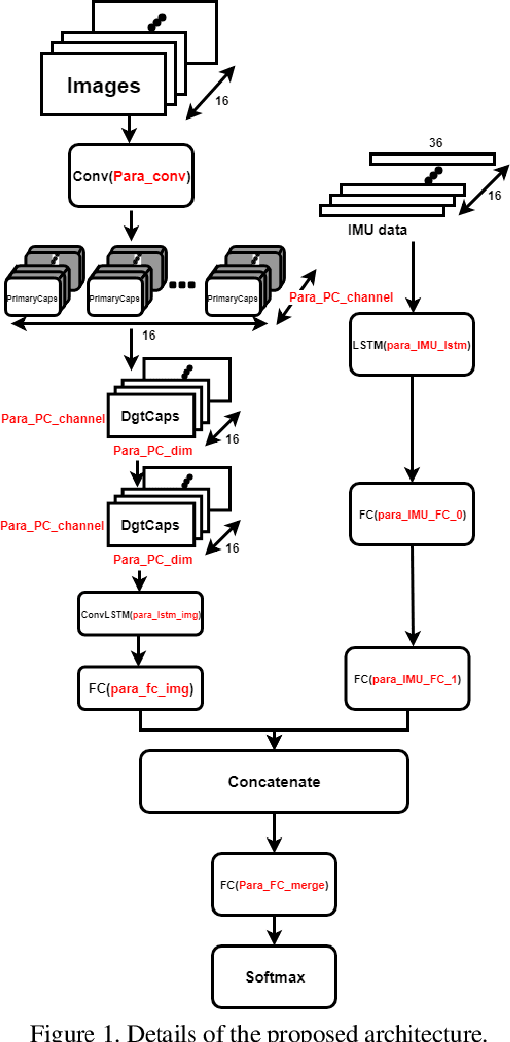
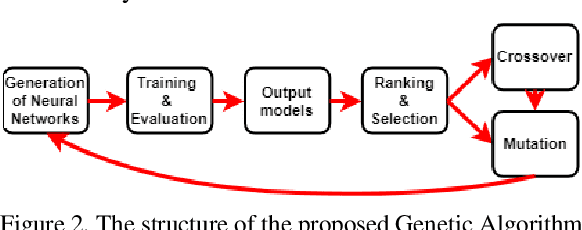
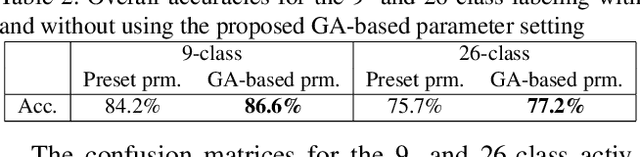
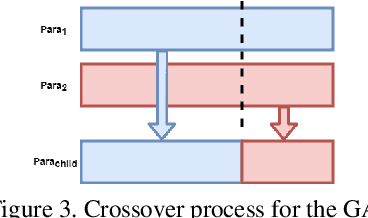
There has been significant amount of research work on human activity classification relying either on Inertial Measurement Unit (IMU) data or data from static cameras providing a third-person view. Using only IMU data limits the variety and complexity of the activities that can be detected. For instance, the sitting activity can be detected by IMU data, but it cannot be determined whether the subject has sat on a chair or a sofa, or where the subject is. To perform fine-grained activity classification from egocentric videos, and to distinguish between activities that cannot be differentiated by only IMU data, we present an autonomous and robust method using data from both ego-vision cameras and IMUs. In contrast to convolutional neural network-based approaches, we propose to employ capsule networks to obtain features from egocentric video data. Moreover, Convolutional Long Short Term Memory framework is employed both on egocentric videos and IMU data to capture temporal aspect of actions. We also propose a genetic algorithm-based approach to autonomously and systematically set various network parameters, rather than using manual settings. Experiments have been performed to perform 9- and 26-label activity classification, and the proposed method, using autonomously set network parameters, has provided very promising results, achieving overall accuracies of 86.6\% and 77.2\%, respectively. The proposed approach combining both modalities also provides increased accuracy compared to using only egovision data and only IMU data.
Enhancing Cross-task Transferability of Adversarial Examples with Dispersion Reduction
May 08, 2019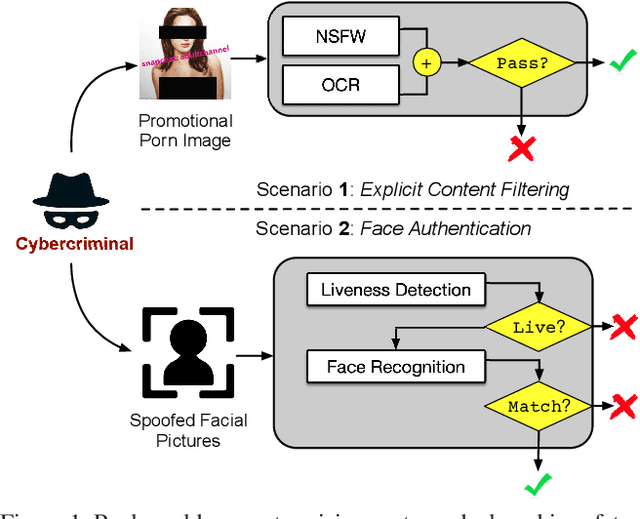
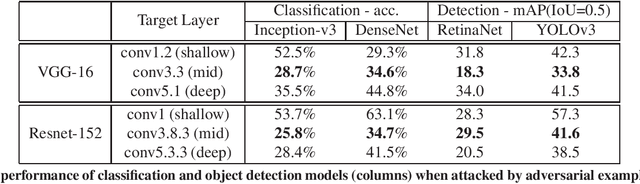

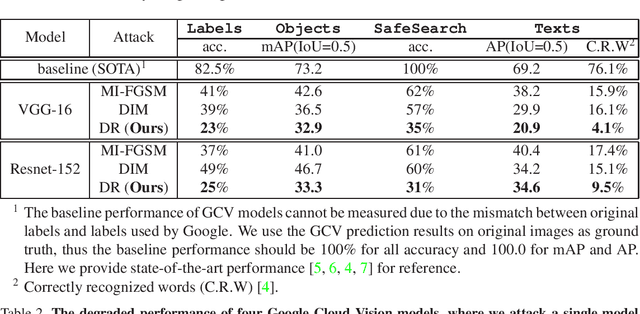
Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they maintain their effectiveness even against other models. With great efforts delved into the transferability of adversarial examples, surprisingly, less attention has been paid to its impact on real-world deep learning deployment. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, explicit content detection, optical character recognition (OCR), and object detection. It represents the cybercriminal's situation where an ensemble of different detection mechanisms need to be evaded all at once. We propose practical attack that overcomes existing attacks' limitation of requiring task-specific loss functions by targeting on the `dispersion' of internal feature map. We report evaluation on four different computer vision tasks provided by Google Cloud Vision APIs to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations.
Autonomously and Simultaneously Refining Deep Neural Network Parameters by a Bi-Generative Adversarial Network Aided Genetic Algorithm
Sep 24, 2018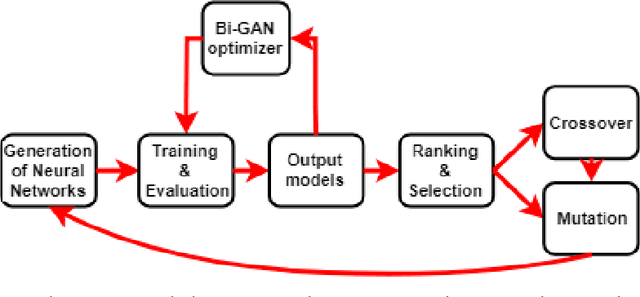
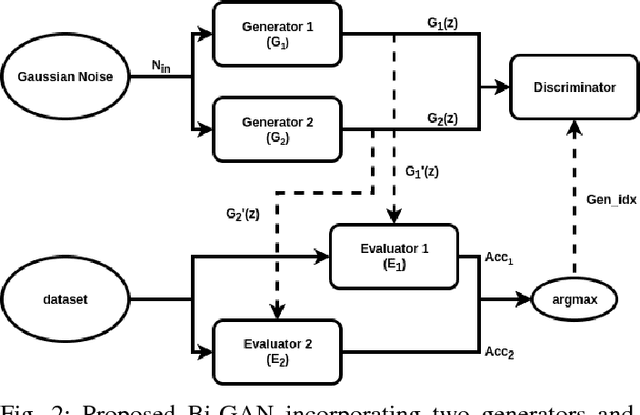

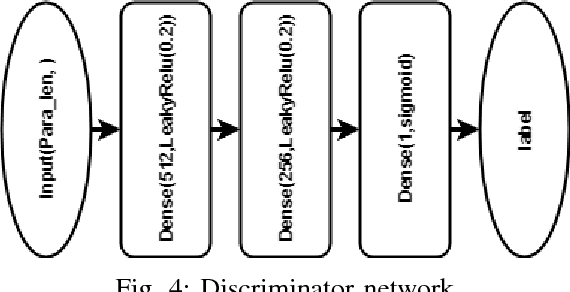
The choice of parameters, and the design of the network architecture are important factors affecting the performance of deep neural networks. Genetic Algorithms (GA) have been used before to determine parameters of a network. Yet, GAs perform a finite search over a discrete set of pre-defined candidates, and cannot, in general, generate unseen configurations. In this paper, to move from exploration to exploitation, we propose a novel and systematic method that autonomously and simultaneously optimizes multiple parameters of any deep neural network by using a GA aided by a bi-generative adversarial network (Bi-GAN). The proposed Bi-GAN allows the autonomous exploitation and choice of the number of neurons, for fully-connected layers, and number of filters, for convolutional layers, from a large range of values. Our proposed Bi-GAN involves two generators, and two different models compete and improve each other progressively with a GAN-based strategy to optimize the networks during GA evolution. Our proposed approach can be used to autonomously refine the number of convolutional layers and dense layers, number and size of kernels, and the number of neurons for the dense layers; choose the type of the activation function; and decide whether to use dropout and batch normalization or not, to improve the accuracy of different deep neural network architectures. Without loss of generality, the proposed method has been tested with the ModelNet database, and compared with the 3D Shapenets and two GA-only methods. The results show that the presented approach can simultaneously and successfully optimize multiple neural network parameters, and achieve higher accuracy even with shallower networks.
Autonomously and Simultaneously Refining Deep Neural Network Parameters by Generative Adversarial Networks
May 24, 2018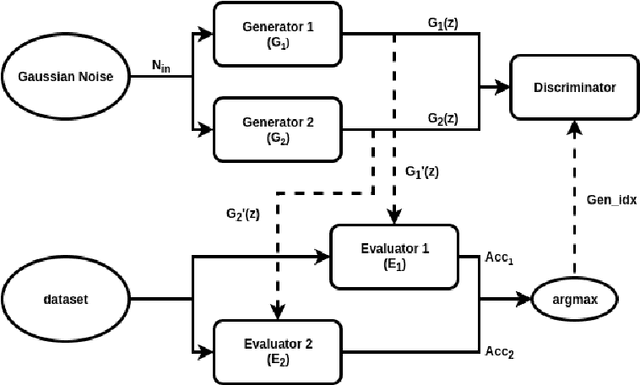

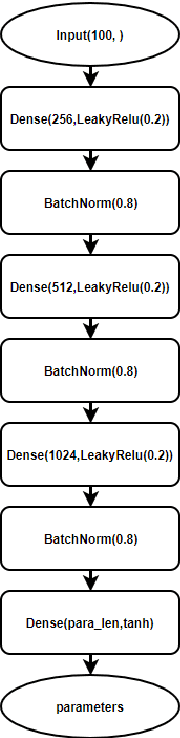

The choice of parameters, and the design of the network architecture are important factors affecting the performance of deep neural networks. However, there has not been much work on developing an established and systematic way of building the structure and choosing the parameters of a neural network, and this task heavily depends on trial and error and empirical results. Considering that there are many design and parameter choices, such as the number of neurons in each layer, the type of activation function, the choice of using drop out or not, it is very hard to cover every configuration, and find the optimal structure. In this paper, we propose a novel and systematic method that autonomously and simultaneously optimizes multiple parameters of any given deep neural network by using a generative adversarial network (GAN). In our proposed approach, two different models compete and improve each other progressively with a GAN-based strategy. Our proposed approach can be used to autonomously refine the parameters, and improve the accuracy of different deep neural network architectures. Without loss of generality, the proposed method has been tested with three different neural network architectures, and three very different datasets and applications. The results show that the presented approach can simultaneously and successfully optimize multiple neural network parameters, and achieve increased accuracy in all three scenarios.