 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainDistill: Implantable Motor Decoding with Task-Specific Knowledge Distillation
Jan 24, 2026Transformer-based neural decoders with large parameter counts, pre-trained on large-scale datasets, have recently outperformed classical machine learning models and small neural networks on brain-computer interface (BCI) tasks. However, their large parameter counts and high computational demands hinder deployment in power-constrained implantable systems. To address this challenge, we introduce BrainDistill, a novel implantable motor decoding pipeline that integrates an implantable neural decoder (IND) with a task-specific knowledge distillation (TSKD) framework. Unlike standard feature distillation methods that attempt to preserve teacher representations in full, TSKD explicitly prioritizes features critical for decoding through supervised projection. Across multiple neural datasets, IND consistently outperforms prior neural decoders on motor decoding tasks, while its TSKD-distilled variant further surpasses alternative distillation methods in few-shot calibration settings. Finally, we present a quantization-aware training scheme that enables integer-only inference with activation clipping ranges learned during training. The quantized IND enables deployment under the strict power constraints of implantable BCIs with minimal performance loss.
Seedream 3.0 Technical Report
Apr 16, 2025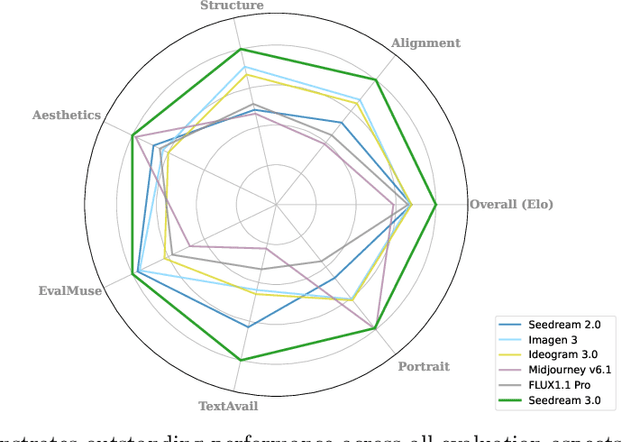


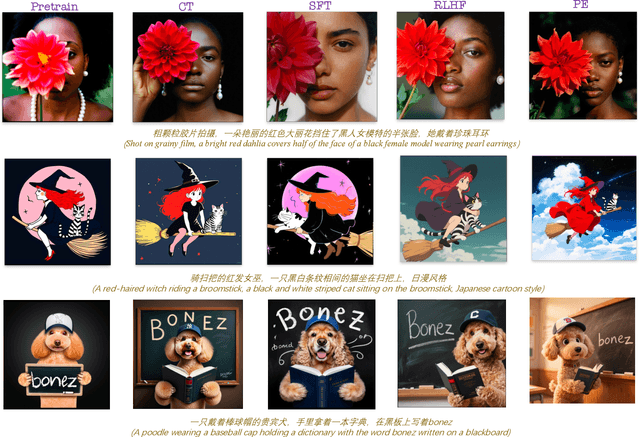
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
AlterMOMA: Fusion Redundancy Pruning for Camera-LiDAR Fusion Models with Alternative Modality Masking
Sep 26, 2024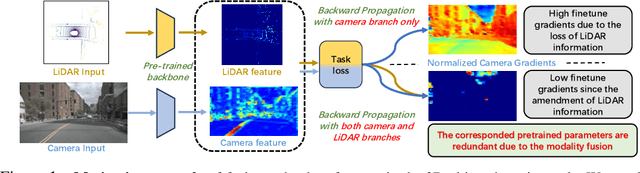

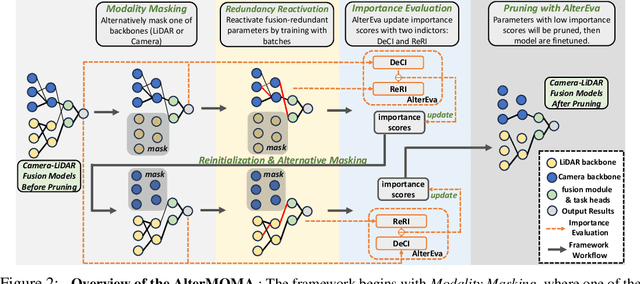

Camera-LiDAR fusion models significantly enhance perception performance in autonomous driving. The fusion mechanism leverages the strengths of each modality while minimizing their weaknesses. Moreover, in practice, camera-LiDAR fusion models utilize pre-trained backbones for efficient training. However, we argue that directly loading single-modal pre-trained camera and LiDAR backbones into camera-LiDAR fusion models introduces similar feature redundancy across modalities due to the nature of the fusion mechanism. Unfortunately, existing pruning methods are developed explicitly for single-modal models, and thus, they struggle to effectively identify these specific redundant parameters in camera-LiDAR fusion models. In this paper, to address the issue above on camera-LiDAR fusion models, we propose a novelty pruning framework Alternative Modality Masking Pruning (AlterMOMA), which employs alternative masking on each modality and identifies the redundant parameters. Specifically, when one modality parameters are masked (deactivated), the absence of features from the masked backbone compels the model to reactivate previous redundant features of the other modality backbone. Therefore, these redundant features and relevant redundant parameters can be identified via the reactivation process. The redundant parameters can be pruned by our proposed importance score evaluation function, Alternative Evaluation (AlterEva), which is based on the observation of the loss changes when certain modality parameters are activated and deactivated. Extensive experiments on the nuScene and KITTI datasets encompassing diverse tasks, baseline models, and pruning algorithms showcase that AlterMOMA outperforms existing pruning methods, attaining state-of-the-art performance.
Design Booster: A Text-Guided Diffusion Model for Image Translation with Spatial Layout Preservation
Feb 05, 2023



Diffusion models are able to generate photorealistic images in arbitrary scenes. However, when applying diffusion models to image translation, there exists a trade-off between maintaining spatial structure and high-quality content. Besides, existing methods are mainly based on test-time optimization or fine-tuning model for each input image, which are extremely time-consuming for practical applications. To address these issues, we propose a new approach for flexible image translation by learning a layout-aware image condition together with a text condition. Specifically, our method co-encodes images and text into a new domain during the training phase. In the inference stage, we can choose images/text or both as the conditions for each time step, which gives users more flexible control over layout and content. Experimental comparisons of our method with state-of-the-art methods demonstrate our model performs best in both style image translation and semantic image translation and took the shortest time.
SRCN3D: Sparse R-CNN 3D Surround-View Camera Object Detection and Tracking for Autonomous Driving
Jun 29, 2022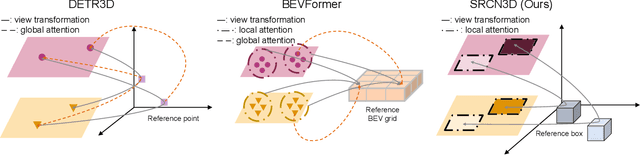

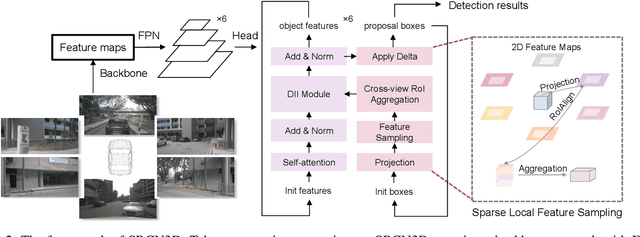
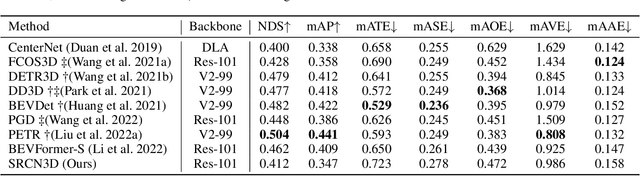
Detection And Tracking of Moving Objects (DATMO) is an essential component in environmental perception for autonomous driving. While 3D detectors using surround-view cameras are just flourishing, there is a growing tendency of using different transformer-based methods to learn queries in 3D space from 2D feature maps of perspective view. This paper proposes Sparse R-CNN 3D (SRCN3D), a novel two-stage fully-convolutional mapping pipeline for surround-view camera detection and tracking. SRCN3D adopts a cascade structure with twin-track update of both fixed number of proposal boxes and proposal latent features. Proposal boxes are projected to perspective view so as to aggregate Region of Interest (RoI) local features. Based on that, proposal features are refined via a dynamic instance interactive head, which then generates classification and the offsets applied to original bounding boxes. Compared to prior arts, our sparse feature sampling module only utilizes local 2D features for adjustment of each corresponding 3D proposal box, leading to a complete sparse paradigm. The proposal features and appearance features are both taken in data association process in a multi-hypotheses 3D multi-object tracking approach. Extensive experiments on nuScenes dataset demonstrate the effectiveness of our proposed SRCN3D detector and tracker. Code is available at https://github.com/synsin0/SRCN3D.
RAANet: Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Density Level Estimation
Nov 18, 2021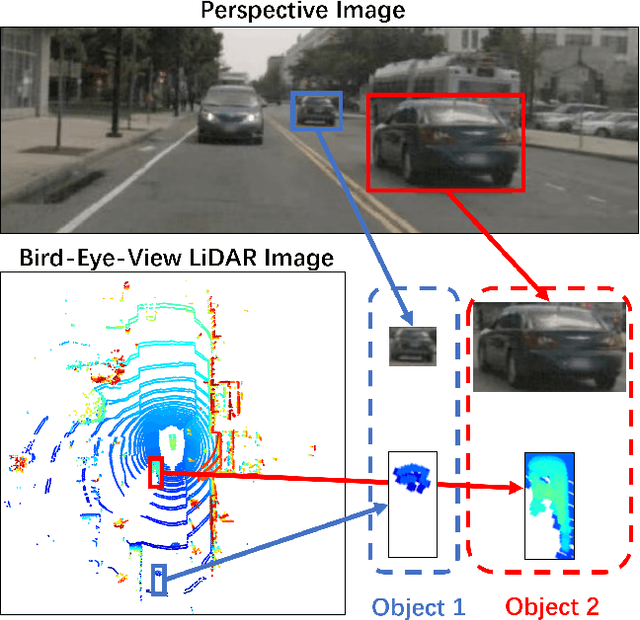
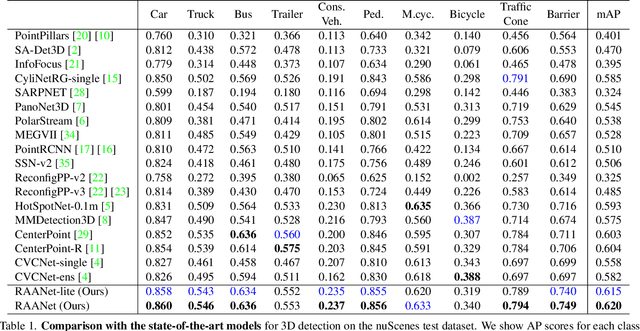


3D object detection from LiDAR data for autonomous driving has been making remarkable strides in recent years. Among the state-of-the-art methodologies, encoding point clouds into a bird's-eye view (BEV) has been demonstrated to be both effective and efficient. Different from perspective views, BEV preserves rich spatial and distance information between objects; and while farther objects of the same type do not appear smaller in the BEV, they contain sparser point cloud features. This fact weakens BEV feature extraction using shared-weight convolutional neural networks. In order to address this challenge, we propose Range-Aware Attention Network (RAANet), which extracts more powerful BEV features and generates superior 3D object detections. The range-aware attention (RAA) convolutions significantly improve feature extraction for near as well as far objects. Moreover, we propose a novel auxiliary loss for density estimation to further enhance the detection accuracy of RAANet for occluded objects. It is worth to note that our proposed RAA convolution is lightweight and compatible to be integrated into any CNN architecture used for the BEV detection. Extensive experiments on the nuScenes dataset demonstrate that our proposed approach outperforms the state-of-the-art methods for LiDAR-based 3D object detection, with real-time inference speed of 16 Hz for the full version and 22 Hz for the lite version. The code is publicly available at an anonymous Github repository https://github.com/anonymous0522/RAAN.
Formal Verification of Stochastic Systems with ReLU Neural Network Controllers
Mar 08, 2021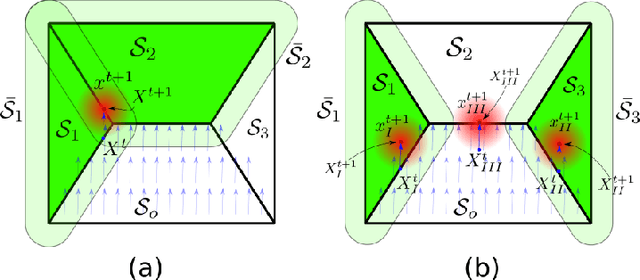
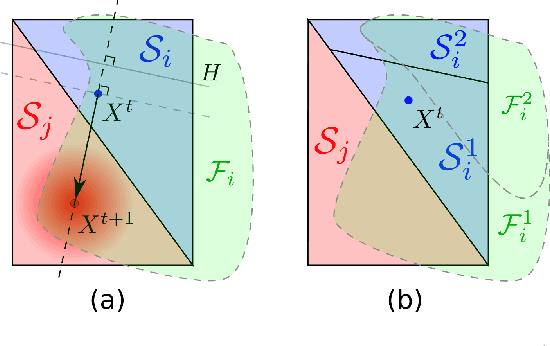
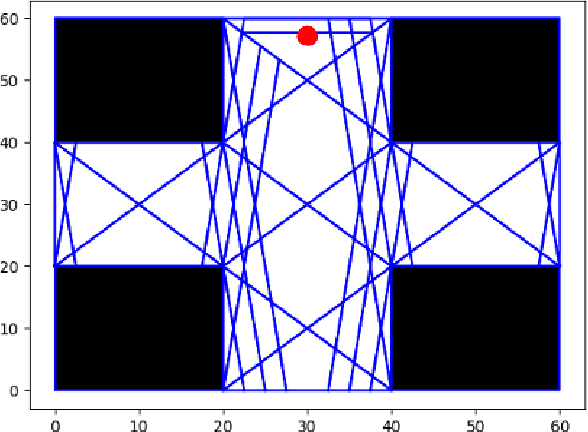
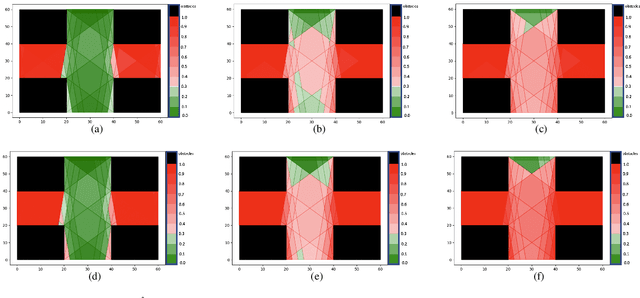
In this work, we address the problem of formal safety verification for stochastic cyber-physical systems (CPS) equipped with ReLU neural network (NN) controllers. Our goal is to find the set of initial states from where, with a predetermined confidence, the system will not reach an unsafe configuration within a specified time horizon. Specifically, we consider discrete-time LTI systems with Gaussian noise, which we abstract by a suitable graph. Then, we formulate a Satisfiability Modulo Convex (SMC) problem to estimate upper bounds on the transition probabilities between nodes in the graph. Using this abstraction, we propose a method to compute tight bounds on the safety probabilities of nodes in this graph, despite possible over-approximations of the transition probabilities between these nodes. Additionally, using the proposed SMC formula, we devise a heuristic method to refine the abstraction of the system in order to further improve the estimated safety bounds. Finally, we corroborate the efficacy of the proposed method with simulation results considering a robot navigation example and comparison against a state-of-the-art verification scheme.