 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlterMOMA: Fusion Redundancy Pruning for Camera-LiDAR Fusion Models with Alternative Modality Masking
Sep 26, 2024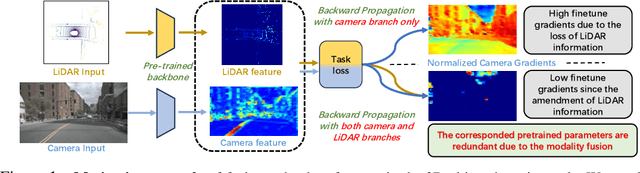

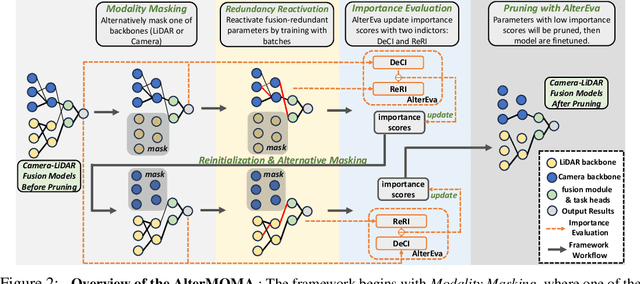

Camera-LiDAR fusion models significantly enhance perception performance in autonomous driving. The fusion mechanism leverages the strengths of each modality while minimizing their weaknesses. Moreover, in practice, camera-LiDAR fusion models utilize pre-trained backbones for efficient training. However, we argue that directly loading single-modal pre-trained camera and LiDAR backbones into camera-LiDAR fusion models introduces similar feature redundancy across modalities due to the nature of the fusion mechanism. Unfortunately, existing pruning methods are developed explicitly for single-modal models, and thus, they struggle to effectively identify these specific redundant parameters in camera-LiDAR fusion models. In this paper, to address the issue above on camera-LiDAR fusion models, we propose a novelty pruning framework Alternative Modality Masking Pruning (AlterMOMA), which employs alternative masking on each modality and identifies the redundant parameters. Specifically, when one modality parameters are masked (deactivated), the absence of features from the masked backbone compels the model to reactivate previous redundant features of the other modality backbone. Therefore, these redundant features and relevant redundant parameters can be identified via the reactivation process. The redundant parameters can be pruned by our proposed importance score evaluation function, Alternative Evaluation (AlterEva), which is based on the observation of the loss changes when certain modality parameters are activated and deactivated. Extensive experiments on the nuScene and KITTI datasets encompassing diverse tasks, baseline models, and pruning algorithms showcase that AlterMOMA outperforms existing pruning methods, attaining state-of-the-art performance.