 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Lottery Ticket Hypothesis for Adversarial Training
Mar 06, 2020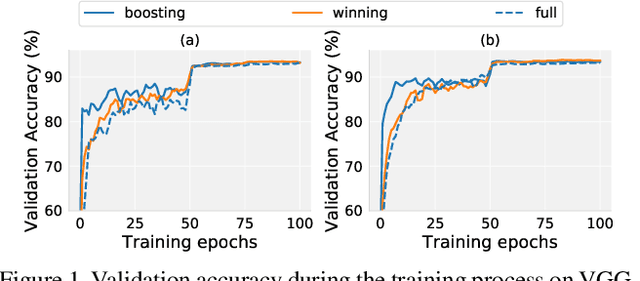

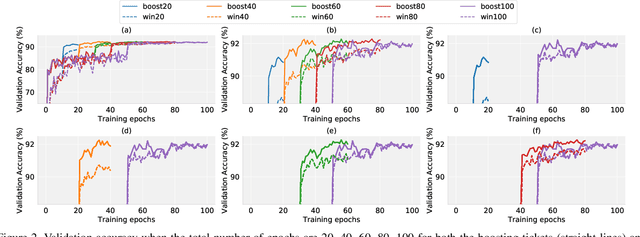

Recent research has proposed the lottery ticket hypothesis, suggesting that for a deep neural network, there exist trainable sub-networks performing equally or better than the original model with commensurate training steps. While this discovery is insightful, finding proper sub-networks requires iterative training and pruning. The high cost incurred limits the applications of the lottery ticket hypothesis. We show there exists a subset of the aforementioned sub-networks that converge significantly faster during the training process and thus can mitigate the cost issue. We conduct extensive experiments to show such sub-networks consistently exist across various model structures for a restrictive setting of hyperparameters ($e.g.$, carefully selected learning rate, pruning ratio, and model capacity). As a practical application of our findings, we demonstrate that such sub-networks can help in cutting down the total time of adversarial training, a standard approach to improve robustness, by up to 49\% on CIFAR-10 to achieve the state-of-the-art robustness.
Enhancing Cross-task Black-Box Transferability of Adversarial Examples with Dispersion Reduction
Nov 22, 2019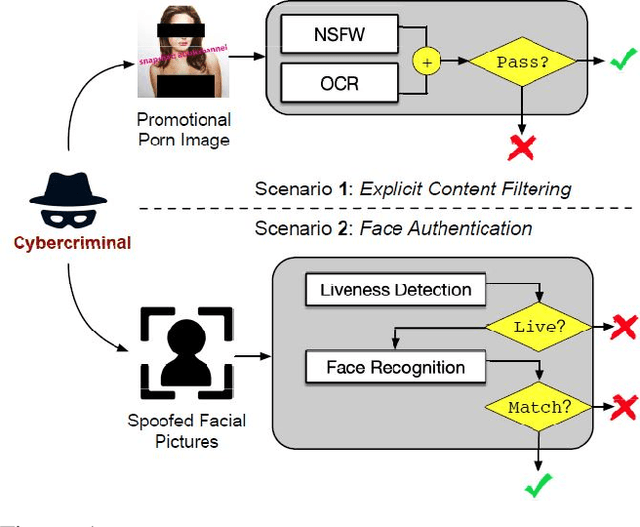
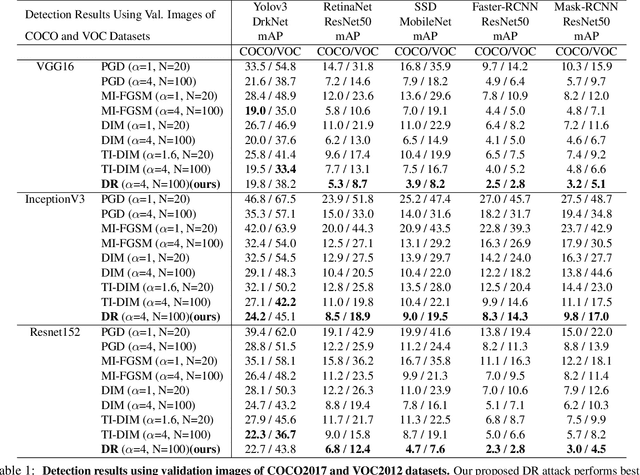
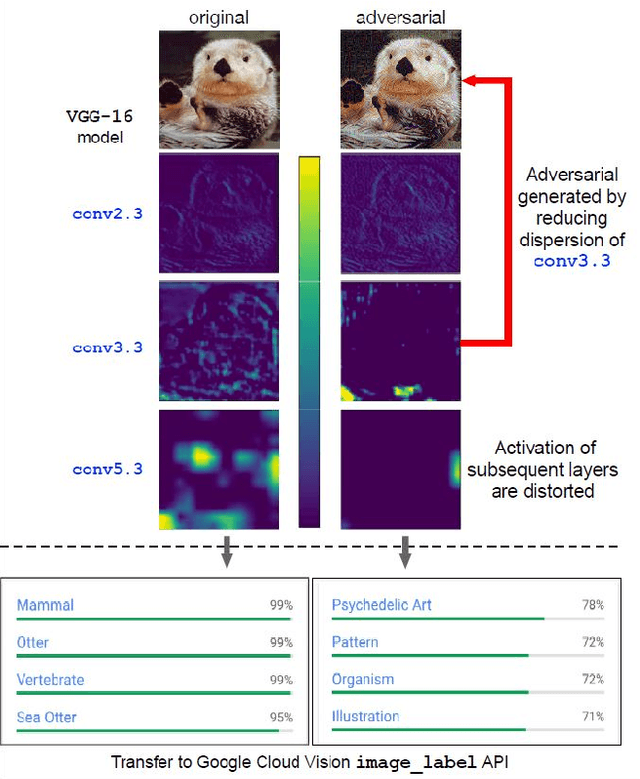

Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they remain adversarial even against other models. Although great efforts have been delved into the transferability across models, surprisingly, less attention has been paid to the cross-task transferability, which represents the real-world cybercriminal's situation, where an ensemble of different defense/detection mechanisms need to be evaded all at once. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, object detection, semantic segmentation, explicit content detection, and text detection. Our proposed attack minimizes the ``dispersion'' of the internal feature map, which overcomes existing attacks' limitation of requiring task-specific loss functions and/or probing a target model. We conduct evaluation on open source detection and segmentation models as well as four different computer vision tasks provided by Google Cloud Vision (GCV) APIs, to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations linf=16.
Explainable Machine Learning in Deployment
Sep 13, 2019
Explainable machine learning seeks to provide various stakeholders with insights into model behavior via feature importance scores, counterfactual explanations, and influential samples, among other techniques. Recent advances in this line of work, however, have gone without surveys of how organizations are using these techniques in practice. This study explores how organizations view and use explainability for stakeholder consumption. We find that the majority of deployments are not for end users affected by the model but for machine learning engineers, who use explainability to debug the model itself. There is a gap between explainability in practice and the goal of public transparency, since explanations primarily serve internal stakeholders rather than external ones. Our study synthesizes the limitations with current explainability techniques that hamper their use for end users. To facilitate end user interaction, we develop a framework for establishing clear goals for explainability, including a focus on normative desiderata.
Fooling Detection Alone is Not Enough: First Adversarial Attack against Multiple Object Tracking
May 30, 2019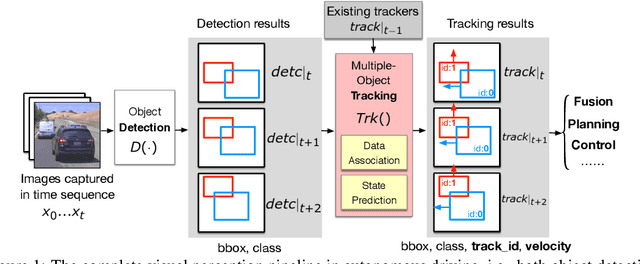
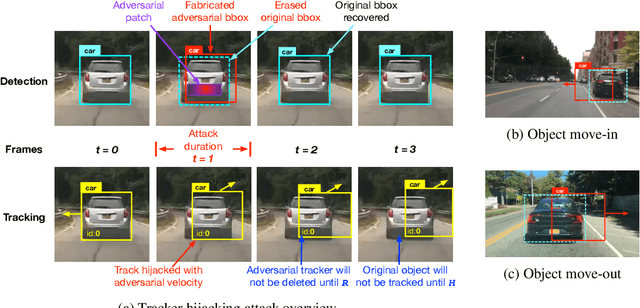
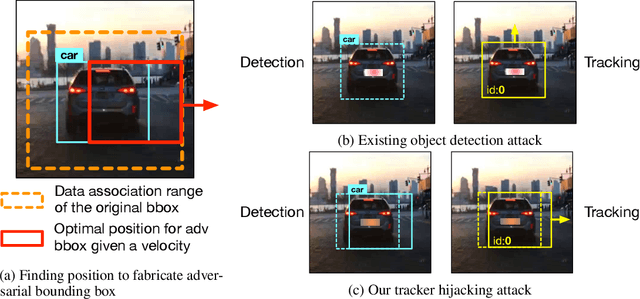
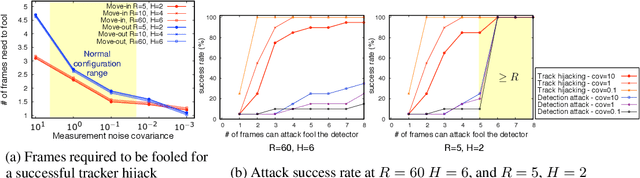
Recent work in adversarial machine learning started to focus on the visual perception in autonomous driving and studied Adversarial Examples (AEs) for object detection models. However, in such visual perception pipeline the detected objects must also be tracked, in a process called Multiple Object Tracking (MOT), to build the moving trajectories of surrounding obstacles. Since MOT is designed to be robust against errors in object detection, it poses a general challenge to existing attack techniques that blindly target objection detection: we find that a success rate of over 98% is needed for them to actually affect the tracking results, a requirement that no existing attack technique can satisfy. In this paper, we are the first to study adversarial machine learning attacks against the complete visual perception pipeline in autonomous driving, and discover a novel attack technique, tracker hijacking, that can effectively fool MOT using AEs on object detection. Using our technique, successful AEs on as few as one single frame can move an existing object in to or out of the headway of an autonomous vehicle to cause potential safety hazards. We perform evaluation using the Berkeley Deep Drive dataset and find that on average when 3 frames are attacked, our attack can have a nearly 100% success rate while attacks that blindly target object detection only have up to 25%.
Enhancing Cross-task Transferability of Adversarial Examples with Dispersion Reduction
May 08, 2019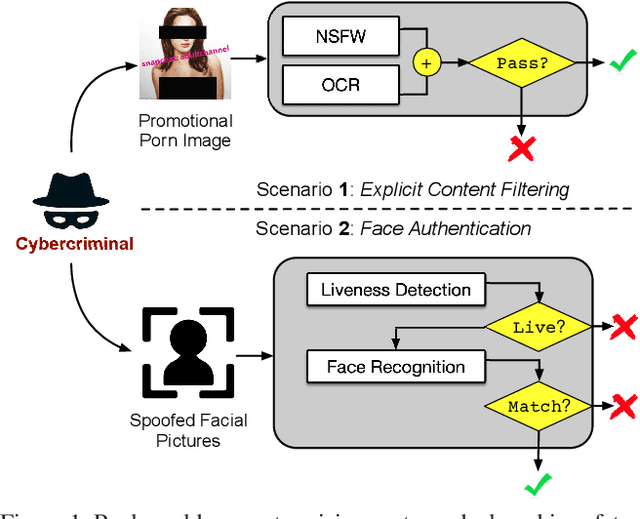
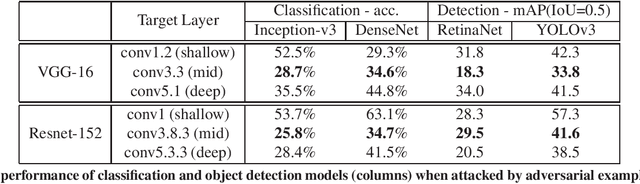

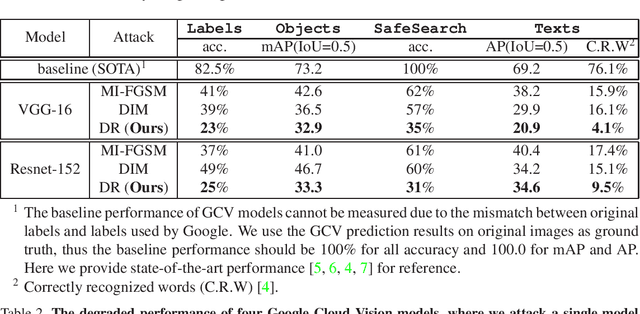
Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they maintain their effectiveness even against other models. With great efforts delved into the transferability of adversarial examples, surprisingly, less attention has been paid to its impact on real-world deep learning deployment. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, explicit content detection, optical character recognition (OCR), and object detection. It represents the cybercriminal's situation where an ensemble of different detection mechanisms need to be evaded all at once. We propose practical attack that overcomes existing attacks' limitation of requiring task-specific loss functions by targeting on the `dispersion' of internal feature map. We report evaluation on four different computer vision tasks provided by Google Cloud Vision APIs to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations.