 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptivePaste: Code Adaptation through Learning Semantics-aware Variable Usage Representations
Paper and Code



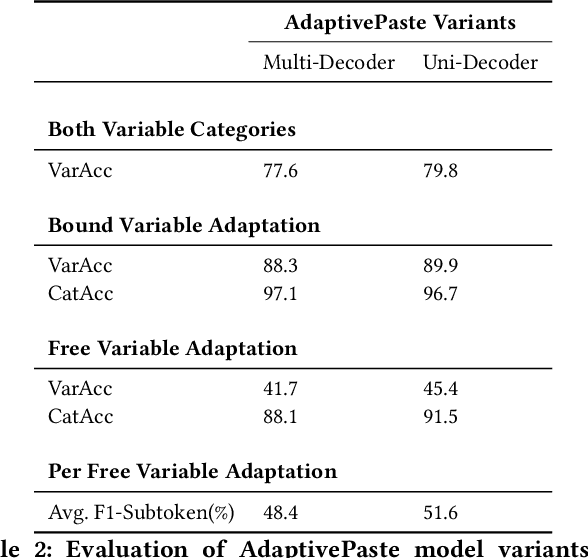
In software development, it is common for programmers to copy-paste code snippets and then adapt them to their use case. This scenario motivates \textit{code adaptation} task -- a variant of program repair which aims to adapt all variable identifiers in a pasted snippet of code to the surrounding, preexisting source code. Nevertheless, no existing approach have been shown to effectively address this task. In this paper, we introduce AdaptivePaste, a learning-based approach to source code adaptation, based on the transformer model and a dedicated dataflow-aware deobfuscation pre-training task to learn meaningful representations of variable usage patterns. We evaluate AdaptivePaste on a dataset of code snippets in Python. Evaluation results suggest that our model can learn to adapt copy-pasted code with 79.8\% accuracy.