 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Sensitive are Meta-Learners to Dataset Imbalance?
Apr 12, 2021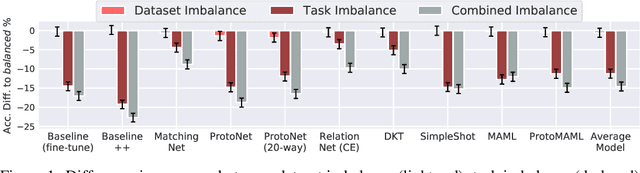
Meta-Learning (ML) has proven to be a useful tool for training Few-Shot Learning (FSL) algorithms by exposure to batches of tasks sampled from a meta-dataset. However, the standard training procedure overlooks the dynamic nature of the real-world where object classes are likely to occur at different frequencies. While it is generally understood that imbalanced tasks harm the performance of supervised methods, there is no significant research examining the impact of imbalanced meta-datasets on the FSL evaluation task. This study exposes the magnitude and extent of this problem. Our results show that ML methods are more robust against meta-dataset imbalance than imbalance at the task-level with a similar imbalance ratio ($\rho<20$), with the effect holding even in long-tail datasets under a larger imbalance ($\rho=65$). Overall, these results highlight an implicit strength of ML algorithms, capable of learning generalizable features under dataset imbalance and domain-shift. The code to reproduce the experiments is released under an open-source license.
Few-Shot Learning with Class Imbalance
Jan 07, 2021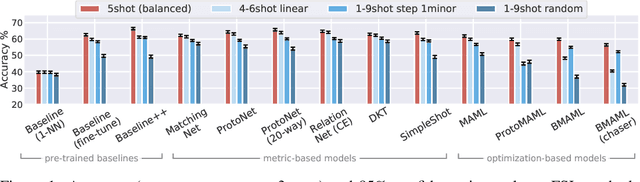
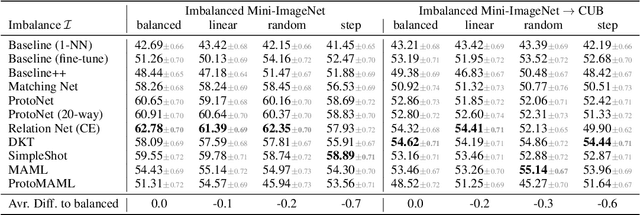
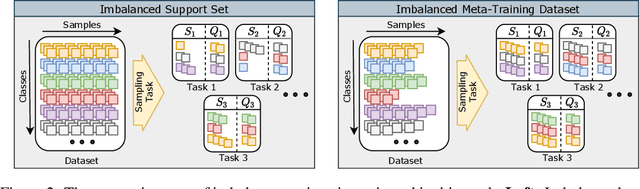
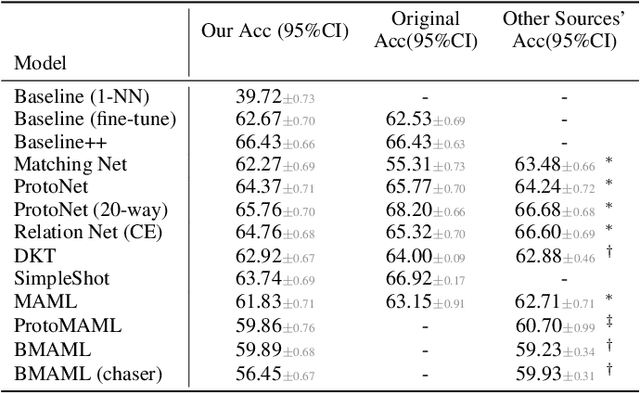
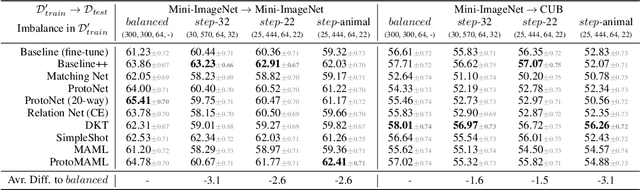
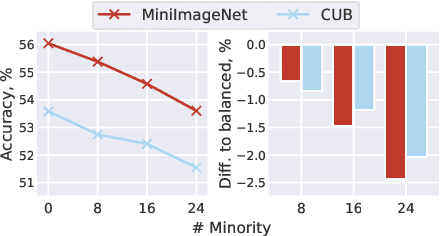
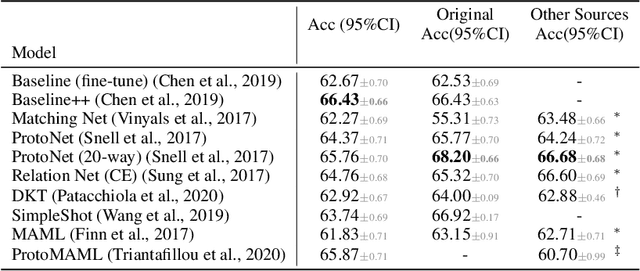
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
Similarity-based data mining for online domain adaptation of a sonar ATR system
Sep 16, 2020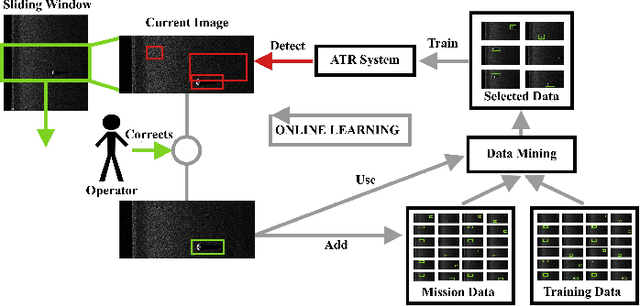
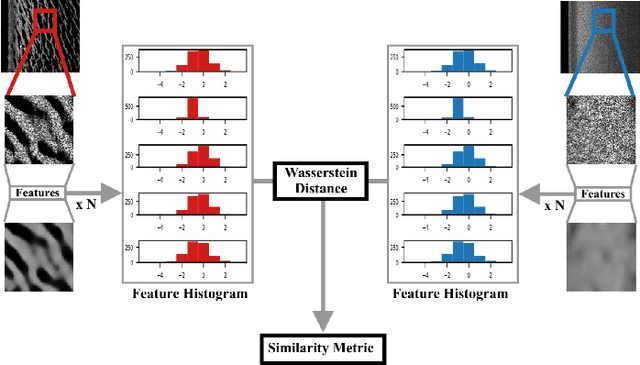

Due to the expensive nature of field data gathering, the lack of training data often limits the performance of Automatic Target Recognition (ATR) systems. This problem is often addressed with domain adaptation techniques, however the currently existing methods fail to satisfy the constraints of resource and time-limited underwater systems. We propose to address this issue via an online fine-tuning of the ATR algorithm using a novel data-selection method. Our proposed data-mining approach relies on visual similarity and outperforms the traditionally employed hard-mining methods. We present a comparative performance analysis in a wide range of simulated environments and highlight the benefits of using our method for the rapid adaptation to previously unseen environments.
* Accepted for publication in IEEE OCEANS2020
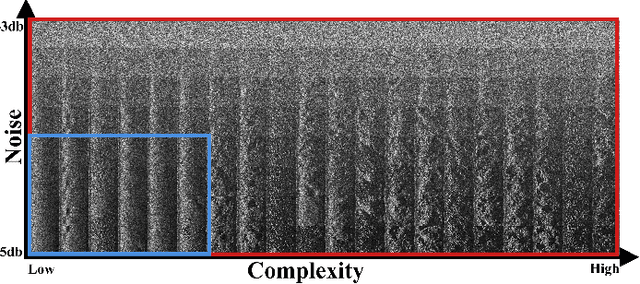
A Comparison of Few-Shot Learning Methods for Underwater Optical and Sonar Image Classification
May 10, 2020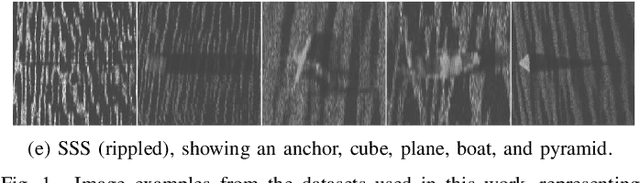
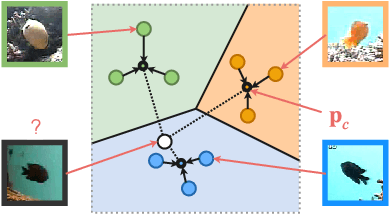
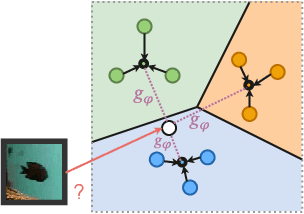
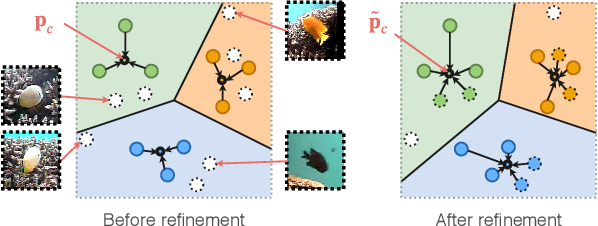
Deep convolutional neural networks have shown to perform well in underwater object recognition tasks, on both optical and sonar images. However, many such methods require hundreds, if not thousands, of images per class to generalize well to unseen examples. This is restricting in situations where obtaining and labeling larger volumes of data is impractical, such as observing a rare object, performing real-time operations, or operating in new underwater environments. Finding an algorithm capable of learning from only a few samples could reduce the time spent obtaining and labeling datasets, and accelerate the training of deep-learning models. To the best of our knowledge, this is the first paper to evaluate and compare several Few-Shot Learning (FSL) methods using underwater optical and side-scan sonar imagery. Our results show that FSL methods offer a significant advantage over the traditional transfer learning methods that employ fine-tuning of pre-trained models. Our findings show that FSL methods are not too far from being used on real-world robotics scenarios and expanding the capabilities of autonomous underwater systems.
Unlimited Resolution Image Generation with R2D2-GANs
Mar 02, 2020

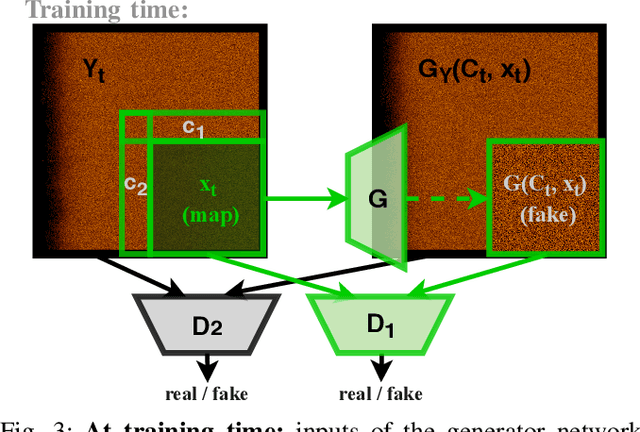
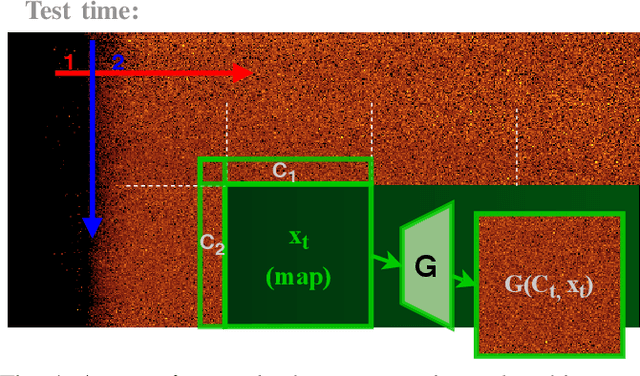
In this paper we present a novel simulation technique for generating high quality images of any predefined resolution. This method can be used to synthesize sonar scans of size equivalent to those collected during a full-length mission, with across track resolutions of any chosen magnitude. In essence, our model extends Generative Adversarial Networks (GANs) based architecture into a conditional recursive setting, that facilitates the continuity of the generated images. The data produced is continuous, realistically-looking, and can also be generated at least two times faster than the real speed of acquisition for the sonars with higher resolutions, such as EdgeTech. The seabed topography can be fully controlled by the user. The visual assessment tests demonstrate that humans cannot distinguish the simulated images from real. Moreover, experimental results suggest that in the absence of real data the autonomous recognition systems can benefit greatly from training with the synthetic data, produced by the R2D2-GANs.
Full-Scale Continuous Synthetic Sonar Data Generation with Markov Conditional Generative Adversarial Networks
Oct 15, 2019
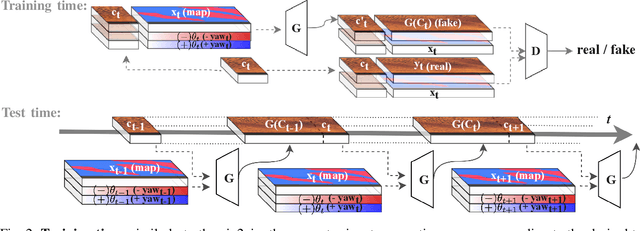


Deployment and operation of autonomous underwater vehicles is expensive and time-consuming. High-quality realistic sonar data simulation could be of benefit to multiple applications, including training of human operators for post-mission analysis, as well as tuning and validation of autonomous target recognition (ATR) systems for underwater vehicles. Producing realistic synthetic sonar imagery is a challenging problem as the model has to account for specific artefacts of real acoustic sensors, vehicle altitude, and a variety of environmental factors. We propose a novel method for generating realistic-looking sonar side-scans of full-length missions, called Markov Conditional pix2pix (MC-pix2pix). Quantitative assessment results confirm that the quality of the produced data is almost indistinguishable from real. Furthermore, we show that bootstrapping ATR systems with MC-pix2pix data can improve the performance. Synthetic data is generated 18 times faster than real acquisition speed, with full user control over the topography of the generated data.