 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Judge is Bad, Based on AI Attempting the Exam Qualifying for the Member of the Polish National Board of Appeal
Nov 06, 2025


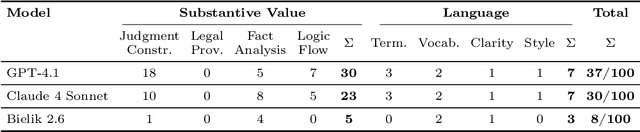
This study provides an empirical assessment of whether current large language models (LLMs) can pass the official qualifying examination for membership in Poland's National Appeal Chamber (Krajowa Izba Odwoławcza). The authors examine two related ideas: using LLM as actual exam candidates and applying the 'LLM-as-a-judge' approach, in which model-generated answers are automatically evaluated by other models. The paper describes the structure of the exam, which includes a multiple-choice knowledge test on public procurement law and a written judgment, and presents the hybrid information recovery and extraction pipeline built to support the models. Several LLMs (including GPT-4.1, Claude 4 Sonnet and Bielik-11B-v2.6) were tested in closed-book and various Retrieval-Augmented Generation settings. The results show that although the models achieved satisfactory scores in the knowledge test, none met the passing threshold in the practical written part, and the evaluations of the 'LLM-as-a-judge' often diverged from the judgments of the official examining committee. The authors highlight key limitations: susceptibility to hallucinations, incorrect citation of legal provisions, weaknesses in logical argumentation, and the need for close collaboration between legal experts and technical teams. The findings indicate that, despite rapid technological progress, current LLMs cannot yet replace human judges or independent examiners in Polish public procurement adjudication.
ZEUS: Zero-shot Embeddings for Unsupervised Separation of Tabular Data
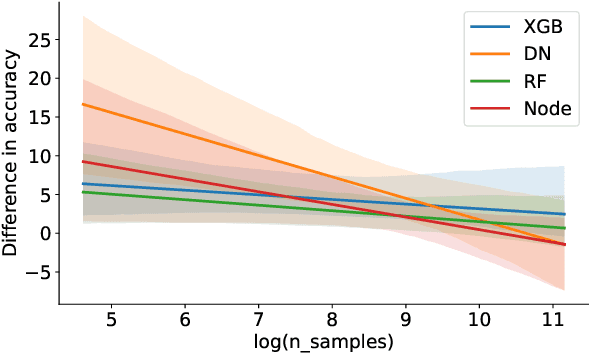
May 15, 2025Clustering tabular data remains a significant open challenge in data analysis and machine learning. Unlike for image data, similarity between tabular records often varies across datasets, making the definition of clusters highly dataset-dependent. Furthermore, the absence of supervised signals complicates hyperparameter tuning in deep learning clustering methods, frequently resulting in unstable performance. To address these issues and reduce the need for per-dataset tuning, we adopt an emerging approach in deep learning: zero-shot learning. We propose ZEUS, a self-contained model capable of clustering new datasets without any additional training or fine-tuning. It operates by decomposing complex datasets into meaningful components that can then be clustered effectively. Thanks to pre-training on synthetic datasets generated from a latent-variable prior, it generalizes across various datasets without requiring user intervention. To the best of our knowledge, ZEUS is the first zero-shot method capable of generating embeddings for tabular data in a fully unsupervised manner. Experimental results demonstrate that it performs on par with or better than traditional clustering algorithms and recent deep learning-based methods, while being significantly faster and more user-friendly.
GFSNetwork: Differentiable Feature Selection via Gumbel-Sigmoid Relaxation
Mar 17, 2025Feature selection in deep learning remains a critical challenge, particularly for high-dimensional tabular data where interpretability and computational efficiency are paramount. We present GFSNetwork, a novel neural architecture that performs differentiable feature selection through temperature-controlled Gumbel-Sigmoid sampling. Unlike traditional methods, where the user has to define the requested number of features, GFSNetwork selects it automatically during an end-to-end process. Moreover, GFSNetwork maintains constant computational overhead regardless of the number of input features. We evaluate GFSNetwork on a series of classification and regression benchmarks, where it consistently outperforms recent methods including DeepLasso, attention maps, as well as traditional feature selectors, while using significantly fewer features. Furthermore, we validate our approach on real-world metagenomic datasets, demonstrating its effectiveness in high-dimensional biological data. Concluding, our method provides a scalable solution that bridges the gap between neural network flexibility and traditional feature selection interpretability. We share our python implementation of GFSNetwork at https://github.com/wwydmanski/GFSNetwork, as well as a PyPi package (gfs_network).
VisTabNet: Adapting Vision Transformers for Tabular Data
Dec 28, 2024Although deep learning models have had great success in natural language processing and computer vision, we do not observe comparable improvements in the case of tabular data, which is still the most common data type used in biological, industrial and financial applications. In particular, it is challenging to transfer large-scale pre-trained models to downstream tasks defined on small tabular datasets. To address this, we propose VisTabNet -- a cross-modal transfer learning method, which allows for adapting Vision Transformer (ViT) with pre-trained weights to process tabular data. By projecting tabular inputs to patch embeddings acceptable by ViT, we can directly apply a pre-trained Transformer Encoder to tabular inputs. This approach eliminates the conceptual cost of designing a suitable architecture for processing tabular data, while reducing the computational cost of training the model from scratch. Experimental results on multiple small tabular datasets (less than 1k samples) demonstrate VisTabNet's superiority, outperforming both traditional ensemble methods and recent deep learning models. The proposed method goes beyond conventional transfer learning practice and shows that pre-trained image models can be transferred to solve tabular problems, extending the boundaries of transfer learning.
Machine Unlearning for Recommendation Systems: An Insight
Jan 17, 2024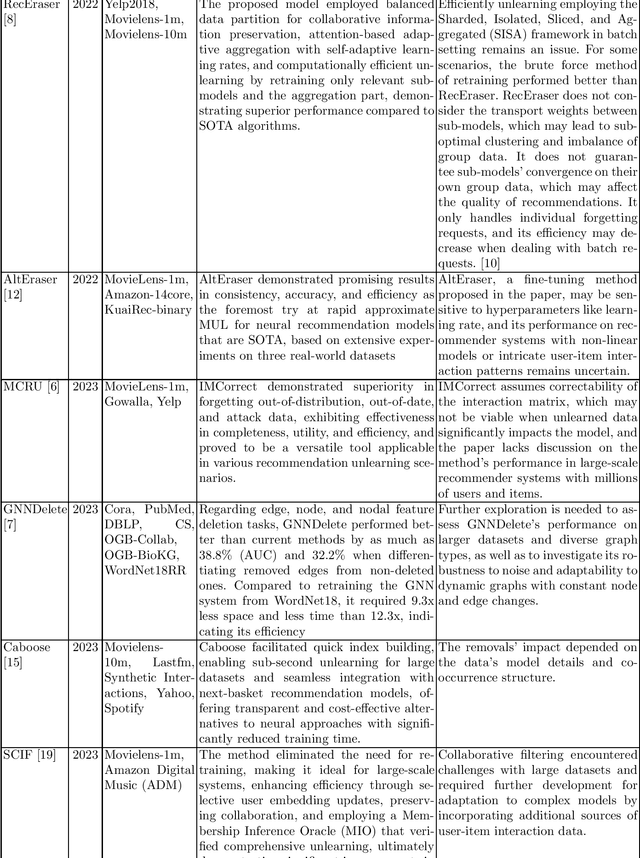
This review explores machine unlearning (MUL) in recommendation systems, addressing adaptability, personalization, privacy, and bias challenges. Unlike traditional models, MUL dynamically adjusts system knowledge based on shifts in user preferences and ethical considerations. The paper critically examines MUL's basics, real-world applications, and challenges like algorithmic transparency. It sifts through literature, offering insights into how MUL could transform recommendations, discussing user trust, and suggesting paths for future research in responsible and user-focused artificial intelligence (AI). The document guides researchers through challenges involving the trade-off between personalization and privacy, encouraging contributions to meet practical demands for targeted data removal. Emphasizing MUL's role in secure and adaptive machine learning, the paper proposes ways to push its boundaries. The novelty of this paper lies in its exploration of the limitations of the methods, which highlights exciting prospects for advancing the field.
HyperTab: Hypernetwork Approach for Deep Learning on Small Tabular Datasets
Apr 07, 2023

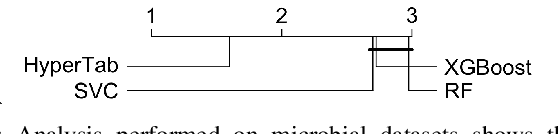
Deep learning has achieved impressive performance in many domains, such as computer vision and natural language processing, but its advantage over classical shallow methods on tabular datasets remains questionable. It is especially challenging to surpass the performance of tree-like ensembles, such as XGBoost or Random Forests, on small-sized datasets (less than 1k samples). To tackle this challenge, we introduce HyperTab, a hypernetwork-based approach to solving small sample problems on tabular datasets. By combining the advantages of Random Forests and neural networks, HyperTab generates an ensemble of neural networks, where each target model is specialized to process a specific lower-dimensional view of the data. Since each view plays the role of data augmentation, we virtually increase the number of training samples while keeping the number of trainable parameters unchanged, which prevents model overfitting. We evaluated HyperTab on more than 40 tabular datasets of a varying number of samples and domains of origin, and compared its performance with shallow and deep learning models representing the current state-of-the-art. We show that HyperTab consistently outranks other methods on small data (with a statistically significant difference) and scores comparable to them on larger datasets. We make a python package with the code available to download at https://pypi.org/project/hypertab/
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Contention Window Optimization in IEEE 802.11ax Networks with Deep Reinforcement Learning
Mar 03, 2020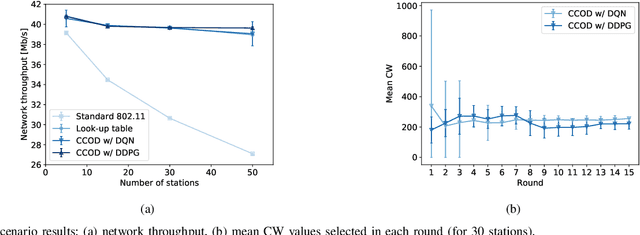
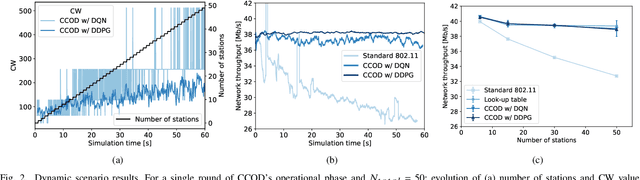
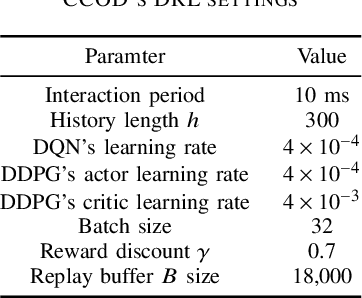
The proper setting of contention window (CW) values has a significant impact on the efficiency of Wi-Fi networks. Unfortunately, the standard method used by 802.11 networks is not scalable enough to maintain stable throughput for an increasing number of stations, despite 802.11ax being designed to improve Wi-Fi performance in dense scenarios. To this end we propose a new method of CW control which leverages deep reinforcement learning principles to learn the correct settings under different network conditions. Our method supports two trainable control algorithms, which, as we demonstrate through simulations, offer efficiency close to optimal while keeping computational cost low.