 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperTab: Hypernetwork Approach for Deep Learning on Small Tabular Datasets
Paper and Code


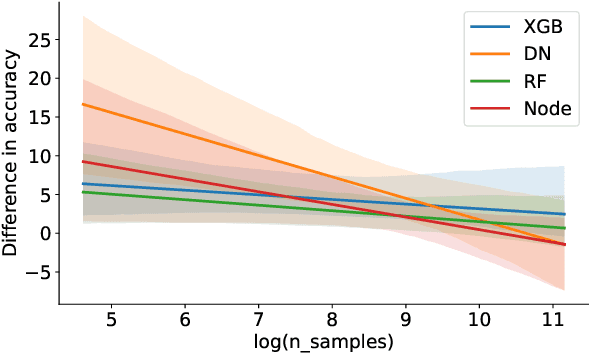
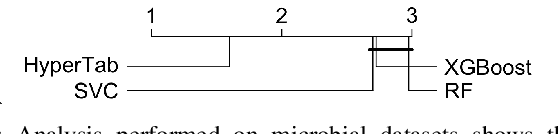
Deep learning has achieved impressive performance in many domains, such as computer vision and natural language processing, but its advantage over classical shallow methods on tabular datasets remains questionable. It is especially challenging to surpass the performance of tree-like ensembles, such as XGBoost or Random Forests, on small-sized datasets (less than 1k samples). To tackle this challenge, we introduce HyperTab, a hypernetwork-based approach to solving small sample problems on tabular datasets. By combining the advantages of Random Forests and neural networks, HyperTab generates an ensemble of neural networks, where each target model is specialized to process a specific lower-dimensional view of the data. Since each view plays the role of data augmentation, we virtually increase the number of training samples while keeping the number of trainable parameters unchanged, which prevents model overfitting. We evaluated HyperTab on more than 40 tabular datasets of a varying number of samples and domains of origin, and compared its performance with shallow and deep learning models representing the current state-of-the-art. We show that HyperTab consistently outranks other methods on small data (with a statistically significant difference) and scores comparable to them on larger datasets. We make a python package with the code available to download at https://pypi.org/project/hypertab/