 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Considerations For Hypothesis Rejection Modules In Spoken Language Understanding Systems
Paper and Code
Oct 31, 2022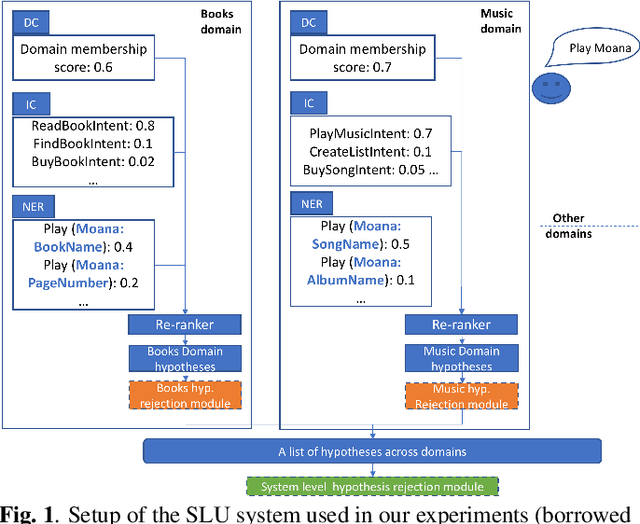



Spoken Language Understanding (SLU) systems typically consist of a set of machine learning models that operate in conjunction to produce an SLU hypothesis. The generated hypothesis is then sent to downstream components for further action. However, it is desirable to discard an incorrect hypothesis before sending it downstream. In this work, we present two designs for SLU hypothesis rejection modules: (i) scheme R1 that performs rejection on domain specific SLU hypothesis and, (ii) scheme R2 that performs rejection on hypothesis generated from the overall SLU system. Hypothesis rejection modules in both schemes reject/accept a hypothesis based on features drawn from the utterance directed to the SLU system, the associated SLU hypothesis and SLU confidence score. Our experiments suggest that both the schemes yield similar results (scheme R1: 2.5% FRR @ 4.5% FAR, scheme R2: 2.5% FRR @ 4.6% FAR), with the best performing systems using all the available features. We argue that while either of the rejection schemes can be chosen over the other, they carry some inherent differences which need to be considered while making this choice. Additionally, we incorporate ASR features in the rejection module (obtaining an 1.9% FRR @ 3.8% FAR) and analyze the improvements.