 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean and Variance Estimation Complexity in Arbitrary Distributions via Wasserstein Minimization
Jan 17, 2025Parameter estimation is a fundamental challenge in machine learning, crucial for tasks such as neural network weight fitting and Bayesian inference. This paper focuses on the complexity of estimating translation $\boldsymbol{\mu} \in \mathbb{R}^l$ and shrinkage $\sigma \in \mathbb{R}_{++}$ parameters for a distribution of the form $\frac{1}{\sigma^l} f_0 \left( \frac{\boldsymbol{x} - \boldsymbol{\mu}}{\sigma} \right)$, where $f_0$ is a known density in $\mathbb{R}^l$ given $n$ samples. We highlight that while the problem is NP-hard for Maximum Likelihood Estimation (MLE), it is possible to obtain $\varepsilon$-approximations for arbitrary $\varepsilon > 0$ within $\text{poly} \left( \frac{1}{\varepsilon} \right)$ time using the Wasserstein distance.
Re-embedding data to strengthen recovery guarantees of clustering
Jan 26, 2023We propose a clustering method that involves chaining four known techniques into a pipeline yielding an algorithm with stronger recovery guarantees than any of the four components separately. Given $n$ points in $\mathbb R^d$, the first component of our pipeline, which we call leapfrog distances, is reminiscent of density-based clustering, yielding an $n\times n$ distance matrix. The leapfrog distances are then translated to new embeddings using multidimensional scaling and spectral methods, two other known techniques, yielding new embeddings of the $n$ points in $\mathbb R^{d'}$, where $d'$ satisfies $d'\ll d$ in general. Finally, sum-of-norms (SON) clustering is applied to the re-embedded points. Although the fourth step (SON clustering) can in principle be replaced by any other clustering method, our focus is on provable guarantees of recovery of underlying structure. Therefore, we establish that the re-embedding improves recovery SON clustering, since SON clustering is a well-studied method that already has provable guarantees.
Robust Correlation Clustering with Asymmetric Noise
Oct 15, 2021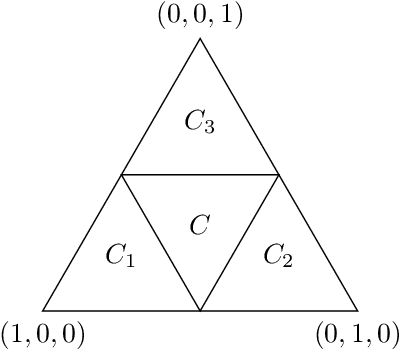

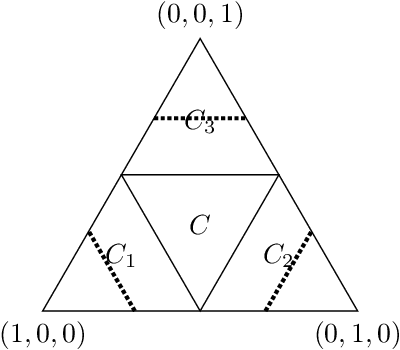
Graph clustering problems typically aim to partition the graph nodes such that two nodes belong to the same partition set if and only if they are similar. Correlation Clustering is a graph clustering formulation which: (1) takes as input a signed graph with edge weights representing a similarity/dissimilarity measure between the nodes, and (2) requires no prior estimate of the number of clusters in the input graph. However, the combinatorial optimization problem underlying Correlation Clustering is NP-hard. In this work, we propose a novel graph generative model, called the Node Factors Model (NFM), which is based on generating feature vectors/embeddings for the graph nodes. The graphs generated by the NFM contain asymmetric noise in the sense that there may exist pairs of nodes in the same cluster which are negatively correlated. We propose a novel Correlation Clustering algorithm, called \anormd, using techniques from semidefinite programming. Using a combination of theoretical and computational results, we demonstrate that $\texttt{$\ell_2$-norm-diag}$ recovers nodes with sufficiently strong cluster membership in graph instances generated by the NFM, thereby making progress towards establishing the provable robustness of our proposed algorithm.
On identifying clusters from sum-of-norms clustering computation
Jun 19, 2020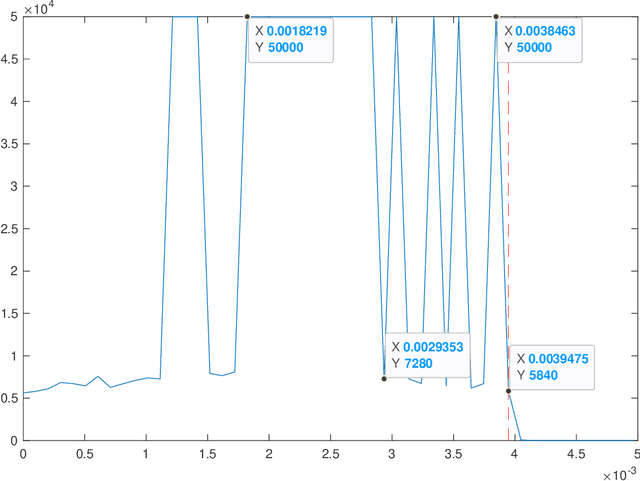
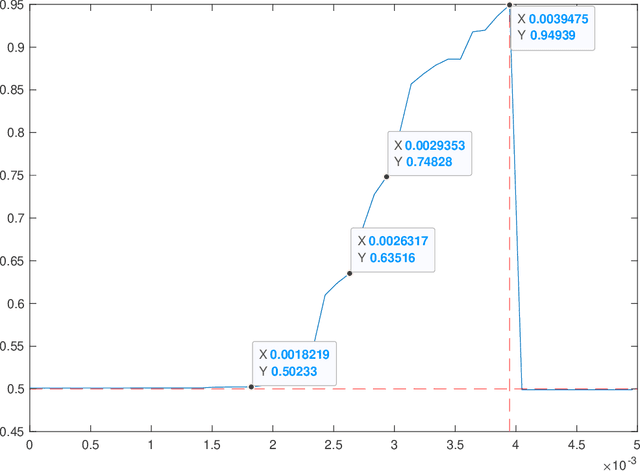
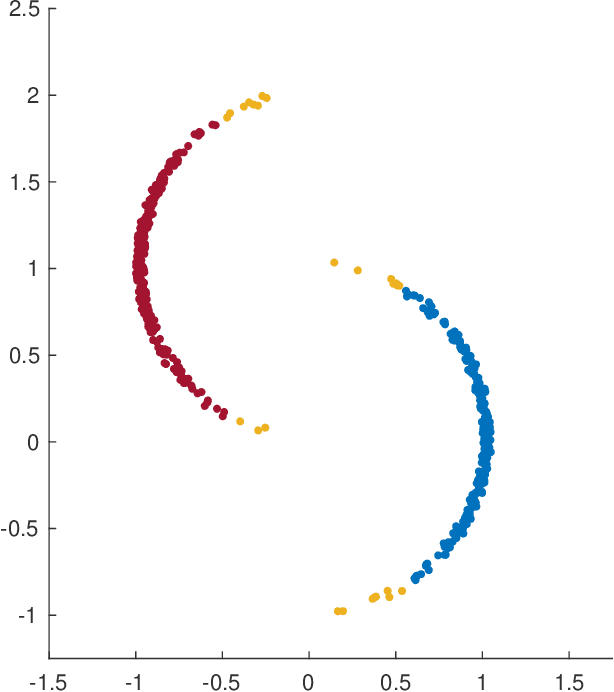
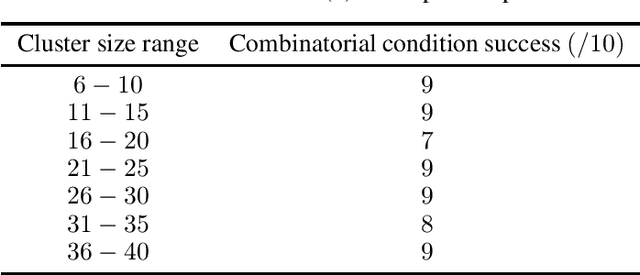
Sum-of-norms clustering is a clustering formulation based on convex optimization that automatically induces hierarchy. Multiple algorithms have been proposed to solve the optimization problem: subgradient descent by Hocking et al.\ \cite{hocking}, ADMM and ADA by Chi and Lange\ \cite{Chi}, stochastic incremental algorithm by Panahi et al.\ \cite{Panahi} and semismooth Newton-CG augmented Lagrangian method by Yuan et al.\ \cite{dsun1}. All algorithms yield approximate solutions, even though an exact solution is demanded to determine the correct cluster assignment. The purpose of this paper is to close the gap between the output from existing algorithms and the exact solution to the optimization problem. We present a clustering test which identifies and certifies the correct cluster assignment from an approximate solution yielded by any primal-dual algorithm. The test may not succeed if the approximation is inaccurate. However, we show the correct cluster assignment is guaranteed to be found by a symmetric primal-dual path following algorithm after sufficiently many iterations, provided that the model parameter $\lambda$ avoids a finite number of bad values. Numerical experiments are implemented to support our results.
Provable Overlapping Community Detection in Weighted Graphs
Apr 19, 2020


Community detection is a widely-studied unsupervised learning problem in which the task is to group similar entities together based on observed pairwise entity interactions. This problem has applications in diverse domains such as social network analysis and computational biology. There is a significant amount of literature studying this problem under the assumption that the communities do not overlap. When the communities are allowed to overlap, often a pure nodes assumption is made, i.e. each community has a node that belongs exclusively to that community. This assumption, however, may not always be satisfied in practice. In this paper, we provide a provable method to detect overlapping communities in weighted graphs without explicitly making the pure nodes assumption. Moreover, contrary to most existing algorithms, our approach is based on convex optimization, for which many useful theoretical properties are already known. We demonstrate the success of our algorithm on artificial and real-world datasets.
Recovery of a mixture of Gaussians by sum-of-norms clustering
Feb 19, 2019Sum-of-norms clustering is a method for assigning $n$ points in $\mathbb{R}^d$ to $K$ clusters, $1\le K\le n$, using convex optimization. Recently, Panahi et al.\ proved that sum-of-norms clustering is guaranteed to recover a mixture of Gaussians under the restriction that the number of samples is not too large. The purpose of this note is to lift this restriction, i.e., show that sum-of-norms clustering with equal weights can recover a mixture of Gaussians even as the number of samples tends to infinity. Our proof relies on an interesting characterization of clusters computed by sum-of-norms clustering that was developed inside a proof of the agglomeration conjecture by Chiquet et al. Because we believe this theorem has independent interest, we restate and reprove the Chiquet et al.\ result herein.