 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSporadic Gradient Tracking over Directed Graphs: A Theoretical Perspective on Decentralized Federated Learning
Jan 31, 2026Decentralized Federated Learning (DFL) enables clients with local data to collaborate in a peer-to-peer manner to train a generalized model. In this paper, we unify two branches of work that have separately solved important challenges in DFL: (i) gradient tracking techniques for mitigating data heterogeneity and (ii) accounting for diverse availability of resources across clients. We propose $\textit{Sporadic Gradient Tracking}$ ($\texttt{Spod-GT}$), the first DFL algorithm that incorporates these factors over general directed graphs by allowing (i) client-specific gradient computation frequencies and (ii) heterogeneous and asymmetric communication frequencies. We conduct a rigorous convergence analysis of our methodology with relaxed assumptions on gradient estimation variance and gradient diversity of clients, providing consensus and optimality guarantees for GT over directed graphs despite intermittent client participation. Through numerical experiments on image classification datasets, we demonstrate the efficacy of $\texttt{Spod-GT}$ compared to well-known GT baselines.
Decentralized Federated Domain Generalization with Style Sharing: A Formal Modeling and Convergence Analysis
Apr 08, 2025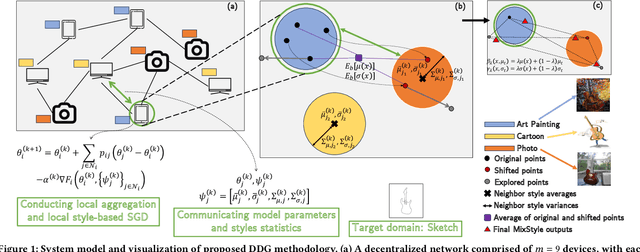
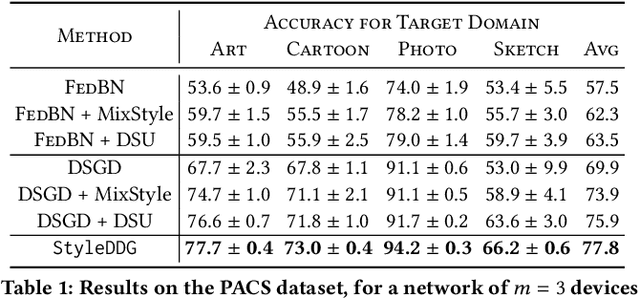
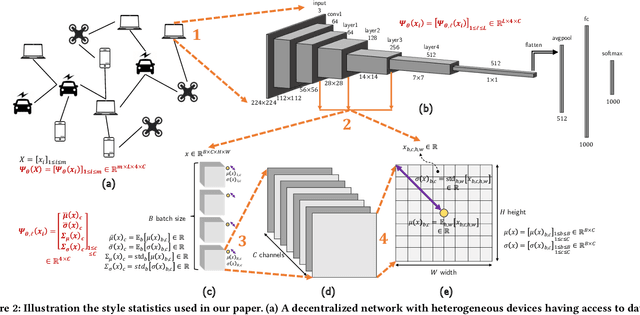
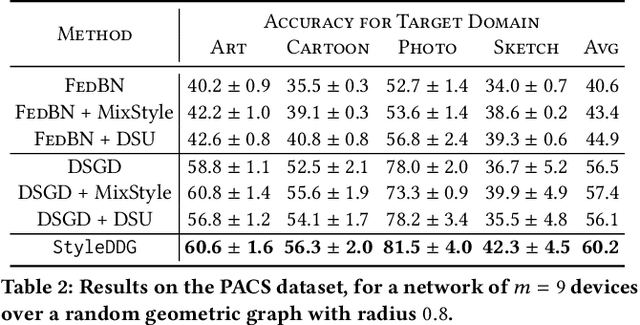
Much of the federated learning (FL) literature focuses on settings where local dataset statistics remain the same between training and testing time. Recent advances in domain generalization (DG) aim to use data from source (training) domains to train a model that generalizes well to data from unseen target (testing) domains. In this paper, we are motivated by two major gaps in existing work on FL and DG: (1) the lack of formal mathematical analysis of DG objectives and training processes; and (2) DG research in FL being limited to the conventional star-topology architecture. Addressing the second gap, we develop $\textit{Decentralized Federated Domain Generalization with Style Sharing}$ ($\texttt{StyleDDG}$), a fully decentralized DG algorithm designed to allow devices in a peer-to-peer network to achieve DG based on sharing style information inferred from their datasets. Additionally, we fill the first gap by providing the first systematic approach to mathematically analyzing style-based DG training optimization. We cast existing centralized DG algorithms within our framework, and employ their formalisms to model $\texttt{StyleDDG}$. Based on this, we obtain analytical conditions under which a sub-linear convergence rate of $\texttt{StyleDDG}$ can be obtained. Through experiments on two popular DG datasets, we demonstrate that $\texttt{StyleDDG}$ can obtain significant improvements in accuracy across target domains with minimal added communication overhead compared to decentralized gradient methods that do not employ style sharing.
Decentralized Sporadic Federated Learning: A Unified Methodology with Generalized Convergence Guarantees
Feb 05, 2024



Decentralized Federated Learning (DFL) has received significant recent research attention, capturing settings where both model updates and model aggregations -- the two key FL processes -- are conducted by the clients. In this work, we propose Decentralized Sporadic Federated Learning ($\texttt{DSpodFL}$), a DFL methodology which generalizes the notion of sporadicity in both of these processes, modeling the impact of different forms of heterogeneity that manifest in realistic DFL settings. $\texttt{DSpodFL}$ unifies many of the prominent decentralized optimization methods, e.g., distributed gradient descent (DGD), randomized gossip (RG), and decentralized federated averaging (DFedAvg), under a single modeling framework. We analytically characterize the convergence behavior of $\texttt{DSpodFL}$, showing, among other insights, that we can match a geometric convergence rate to a finite optimality gap under more general assumptions than in existing works. Through experiments, we demonstrate that $\texttt{DSpodFL}$ achieves significantly improved training speeds and robustness to variations in system parameters compared to the state-of-the-art.
Event-Triggered Decentralized Federated Learning over Resource-Constrained Edge Devices
Nov 23, 2022



Federated learning (FL) is a technique for distributed machine learning (ML), in which edge devices carry out local model training on their individual datasets. In traditional FL algorithms, trained models at the edge are periodically sent to a central server for aggregation, utilizing a star topology as the underlying communication graph. However, assuming access to a central coordinator is not always practical, e.g., in ad hoc wireless network settings. In this paper, we develop a novel methodology for fully decentralized FL, where in addition to local training, devices conduct model aggregation via cooperative consensus formation with their one-hop neighbors over the decentralized underlying physical network. We further eliminate the need for a timing coordinator by introducing asynchronous, event-triggered communications among the devices. In doing so, to account for the inherent resource heterogeneity challenges in FL, we define personalized communication triggering conditions at each device that weigh the change in local model parameters against the available local resources. We theoretically demonstrate that our methodology converges to the globally optimal learning model at a $O{(\frac{\ln{k}}{\sqrt{k}})}$ rate under standard assumptions in distributed learning and consensus literature. Our subsequent numerical evaluations demonstrate that our methodology obtains substantial improvements in convergence speed and/or communication savings compared with existing decentralized FL baselines.
Decentralized Event-Triggered Federated Learning with Heterogeneous Communication Thresholds
Apr 07, 2022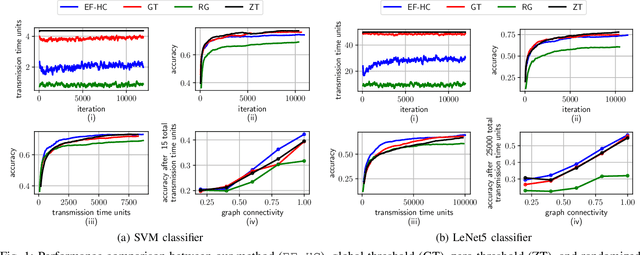
A recent emphasis of distributed learning research has been on federated learning (FL), in which model training is conducted by the data-collecting devices. Existing research on FL has mostly focused on a star topology learning architecture with synchronized (time-triggered) model training rounds, where the local models of the devices are periodically aggregated by a centralized coordinating node. However, in many settings, such a coordinating node may not exist, motivating efforts to fully decentralize FL. In this work, we propose a novel methodology for distributed model aggregations via asynchronous, event-triggered consensus iterations over the network graph topology. We consider heterogeneous communication event thresholds at each device that weigh the change in local model parameters against the available local resources in deciding the benefit of aggregations at each iteration. Through theoretical analysis, we demonstrate that our methodology achieves asymptotic convergence to the globally optimal learning model under standard assumptions in distributed learning and graph consensus literature, and without restrictive connectivity requirements on the underlying topology. Subsequent numerical results demonstrate that our methodology obtains substantial improvements in communication requirements compared with FL baselines.