 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Federated Domain Generalization with Style Sharing: A Formal Modeling and Convergence Analysis
Paper and Code
Apr 08, 2025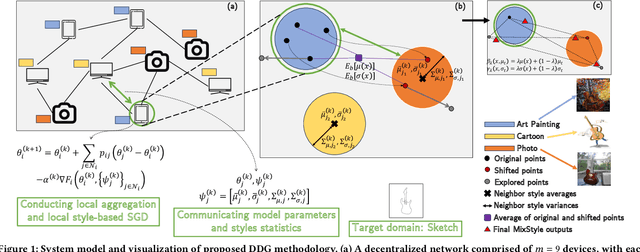
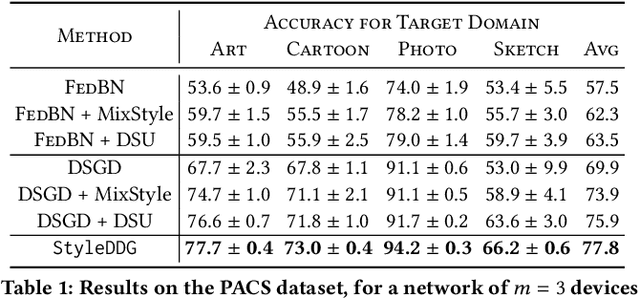
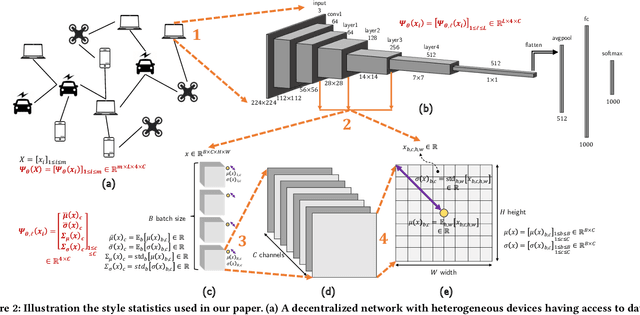
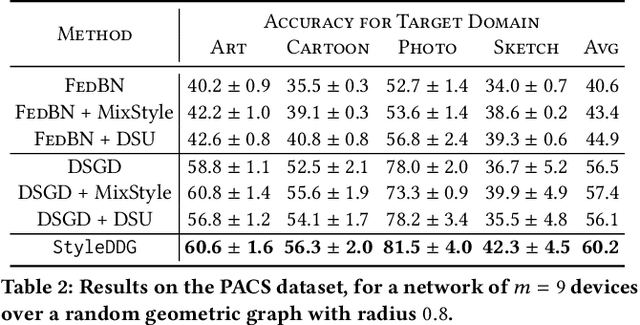
Much of the federated learning (FL) literature focuses on settings where local dataset statistics remain the same between training and testing time. Recent advances in domain generalization (DG) aim to use data from source (training) domains to train a model that generalizes well to data from unseen target (testing) domains. In this paper, we are motivated by two major gaps in existing work on FL and DG: (1) the lack of formal mathematical analysis of DG objectives and training processes; and (2) DG research in FL being limited to the conventional star-topology architecture. Addressing the second gap, we develop $\textit{Decentralized Federated Domain Generalization with Style Sharing}$ ($\texttt{StyleDDG}$), a fully decentralized DG algorithm designed to allow devices in a peer-to-peer network to achieve DG based on sharing style information inferred from their datasets. Additionally, we fill the first gap by providing the first systematic approach to mathematically analyzing style-based DG training optimization. We cast existing centralized DG algorithms within our framework, and employ their formalisms to model $\texttt{StyleDDG}$. Based on this, we obtain analytical conditions under which a sub-linear convergence rate of $\texttt{StyleDDG}$ can be obtained. Through experiments on two popular DG datasets, we demonstrate that $\texttt{StyleDDG}$ can obtain significant improvements in accuracy across target domains with minimal added communication overhead compared to decentralized gradient methods that do not employ style sharing.