 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Stochastic Zeroth-Order Optimization for Federated Learning
Jan 24, 2022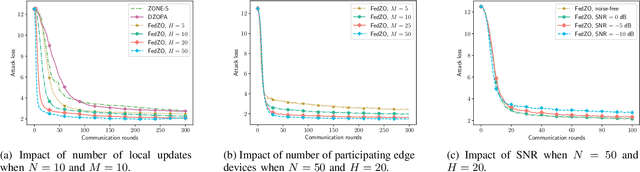
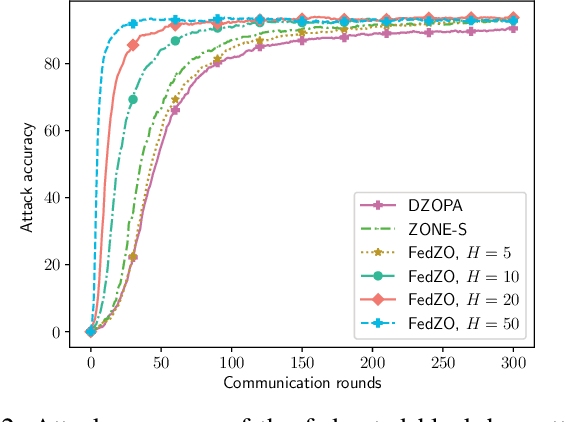
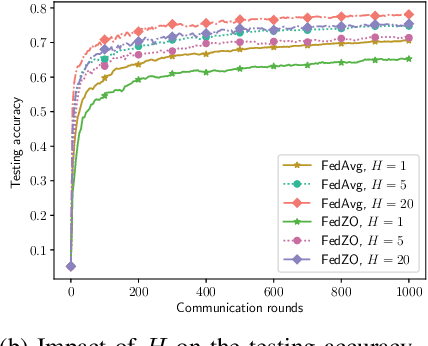
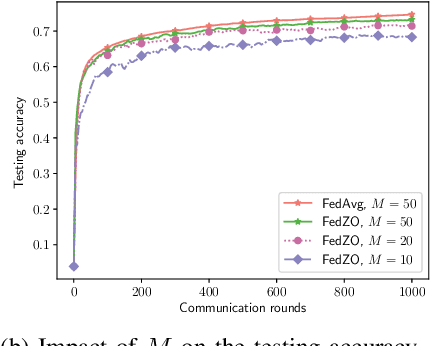
Federated learning (FL), as an emerging edge artificial intelligence paradigm, enables many edge devices to collaboratively train a global model without sharing their private data. To enhance the training efficiency of FL, various algorithms have been proposed, ranging from first-order to second-order methods. However, these algorithms cannot be applied in scenarios where the gradient information is not available, e.g., federated black-box attack and federated hyperparameter tuning. To address this issue, in this paper we propose a derivative-free federated zeroth-order optimization (FedZO) algorithm featured by performing multiple local updates based on stochastic gradient estimators in each communication round and enabling partial device participation. Under the non-convex setting, we derive the convergence performance of the FedZO algorithm and characterize the impact of the numbers of local iterates and participating edge devices on the convergence. To enable communication-efficient FedZO over wireless networks, we further propose an over-the-air computation (AirComp) assisted FedZO algorithm. With an appropriate transceiver design, we show that the convergence of AirComp-assisted FedZO can still be preserved under certain signal-to-noise ratio conditions. Simulation results demonstrate the effectiveness of the FedZO algorithm and validate the theoretical observations.