 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCPG Policies for Robot Locomotion
Feb 25, 2023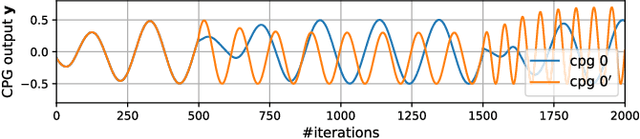
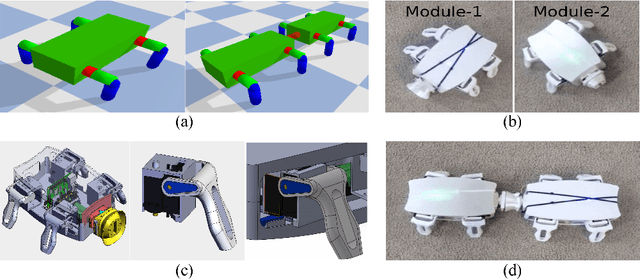
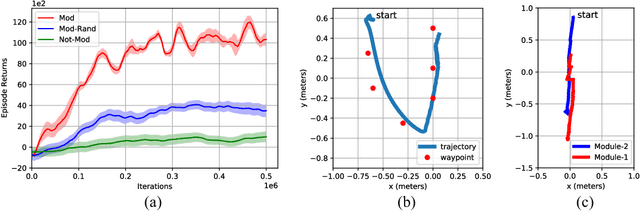
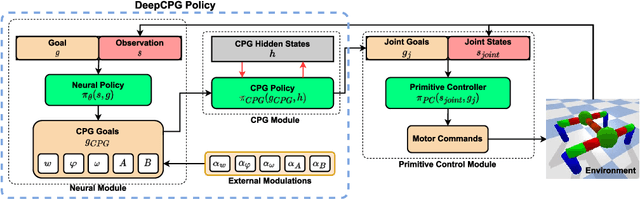
Central Pattern Generators (CPGs) form the neural basis of the observed rhythmic behaviors for locomotion in legged animals. The CPG dynamics organized into networks allow the emergence of complex locomotor behaviors. In this work, we take this inspiration for developing walking behaviors in multi-legged robots. We present novel DeepCPG policies that embed CPGs as a layer in a larger neural network and facilitate end-to-end learning of locomotion behaviors in deep reinforcement learning (DRL) setup. We demonstrate the effectiveness of this approach on physics engine-based insectoid robots. We show that, compared to traditional approaches, DeepCPG policies allow sample-efficient end-to-end learning of effective locomotion strategies even in the case of high-dimensional sensor spaces (vision). We scale the DeepCPG policies using a modular robot configuration and multi-agent DRL. Our results suggest that gradual complexification with embedded priors of these policies in a modular fashion could achieve non-trivial sensor and motor integration on a robot platform. These results also indicate the efficacy of bootstrapping more complex intelligent systems from simpler ones based on biological principles. Finally, we present the experimental results for a proof-of-concept insectoid robot system for which DeepCPG learned policies initially using the simulation engine and these were afterwards transferred to real-world robots without any additional fine-tuning.