 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCPG Policies for Robot Locomotion
Feb 25, 2023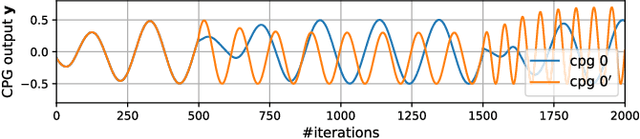
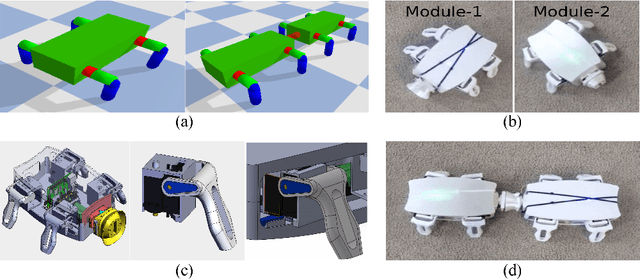
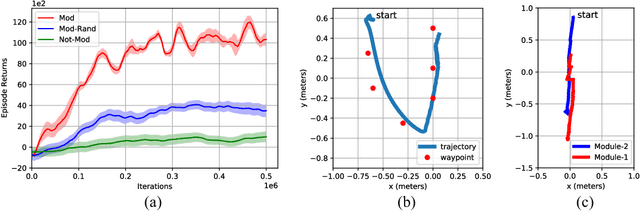
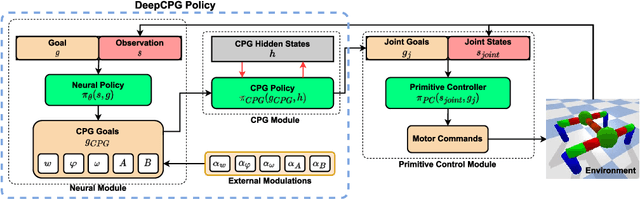
Central Pattern Generators (CPGs) form the neural basis of the observed rhythmic behaviors for locomotion in legged animals. The CPG dynamics organized into networks allow the emergence of complex locomotor behaviors. In this work, we take this inspiration for developing walking behaviors in multi-legged robots. We present novel DeepCPG policies that embed CPGs as a layer in a larger neural network and facilitate end-to-end learning of locomotion behaviors in deep reinforcement learning (DRL) setup. We demonstrate the effectiveness of this approach on physics engine-based insectoid robots. We show that, compared to traditional approaches, DeepCPG policies allow sample-efficient end-to-end learning of effective locomotion strategies even in the case of high-dimensional sensor spaces (vision). We scale the DeepCPG policies using a modular robot configuration and multi-agent DRL. Our results suggest that gradual complexification with embedded priors of these policies in a modular fashion could achieve non-trivial sensor and motor integration on a robot platform. These results also indicate the efficacy of bootstrapping more complex intelligent systems from simpler ones based on biological principles. Finally, we present the experimental results for a proof-of-concept insectoid robot system for which DeepCPG learned policies initially using the simulation engine and these were afterwards transferred to real-world robots without any additional fine-tuning.
Robust Deep Reinforcement Learning for Quadcopter Control
Nov 06, 2021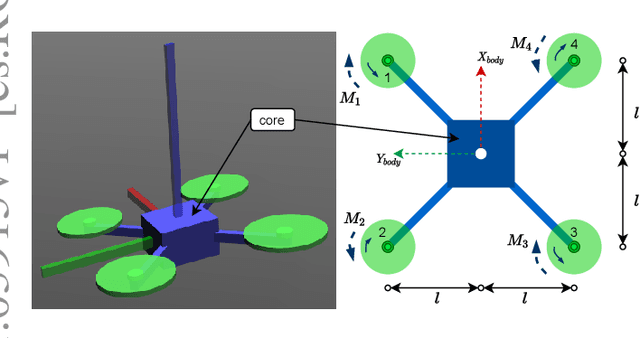

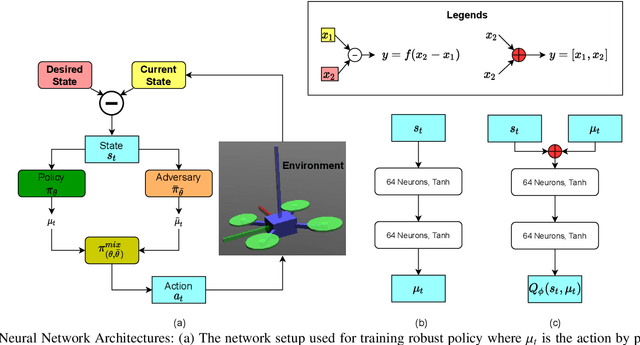
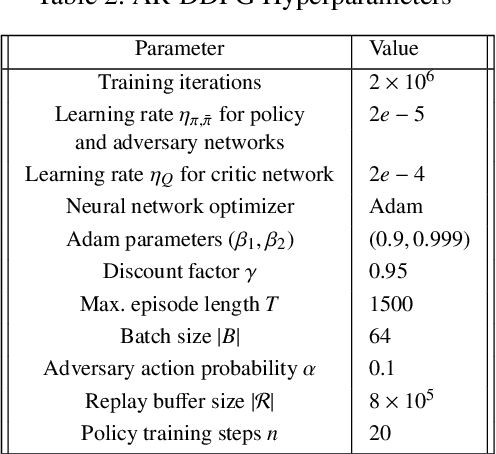
Deep reinforcement learning (RL) has made it possible to solve complex robotics problems using neural networks as function approximators. However, the policies trained on stationary environments suffer in terms of generalization when transferred from one environment to another. In this work, we use Robust Markov Decision Processes (RMDP) to train the drone control policy, which combines ideas from Robust Control and RL. It opts for pessimistic optimization to handle potential gaps between policy transfer from one environment to another. The trained control policy is tested on the task of quadcopter positional control. RL agents were trained in a MuJoCo simulator. During testing, different environment parameters (unseen during the training) were used to validate the robustness of the trained policy for transfer from one environment to another. The robust policy outperformed the standard agents in these environments, suggesting that the added robustness increases generality and can adapt to non-stationary environments. Codes: https://github.com/adipandas/gym_multirotor
Developmental Reinforcement Learning of Control Policy of a Quadcopter UAV with Thrust Vectoring Rotors
Jul 15, 2020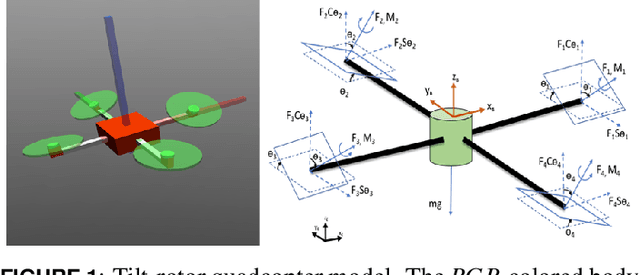
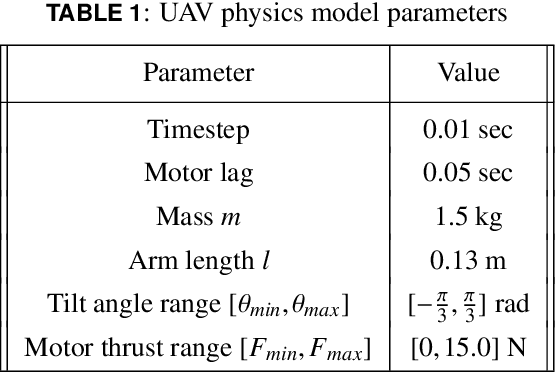
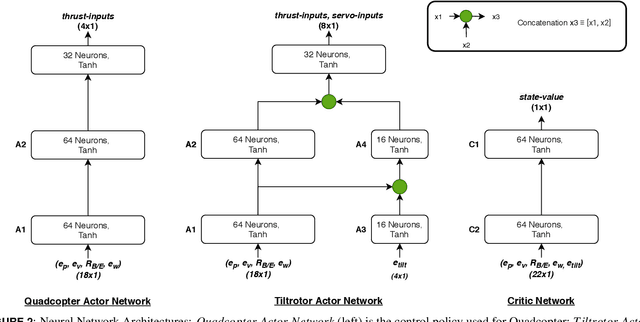
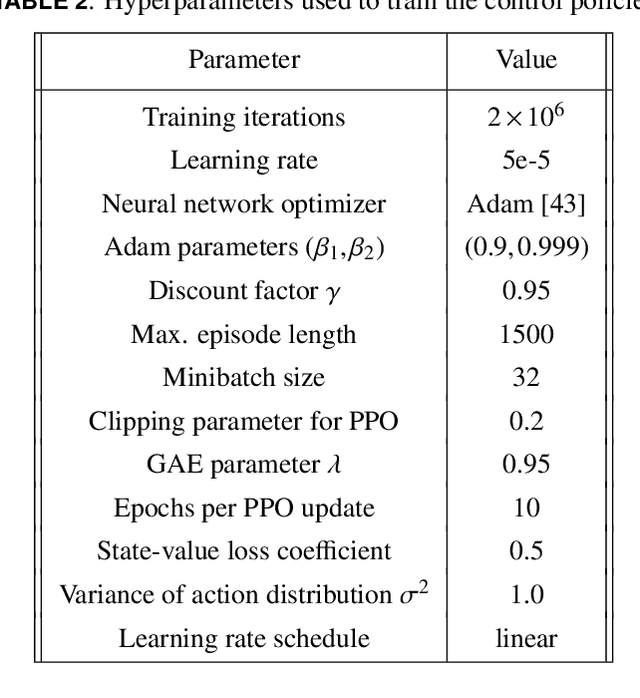
In this paper, we present a novel developmental reinforcement learning-based controller for a quadcopter with thrust vectoring capabilities. This multirotor UAV design has tilt-enabled rotors. It utilizes the rotor force magnitude and direction to achieve the desired state during flight. The control policy of this robot is learned using the policy transfer from the learned controller of the quadcopter (comparatively simple UAV design without thrust vectoring). This approach allows learning a control policy for systems with multiple inputs and multiple outputs. The performance of the learned policy is evaluated by physics-based simulations for the tasks of hovering and way-point navigation. The flight simulations utilize a flight controller based on reinforcement learning without any additional PID components. The results show faster learning with the presented approach as opposed to learning the control policy from scratch for this new UAV design created by modifications in a conventional quadcopter, i.e., the addition of more degrees of freedom (4-actuators in conventional quadcopter to 8-actuators in tilt-rotor quadcopter). We demonstrate the robustness of our learned policy by showing the recovery of the tilt-rotor platform in the simulation from various non-static initial conditions in order to reach a desired state. The developmental policy for the tilt-rotor UAV also showed superior fault tolerance when compared with the policy learned from the scratch. The results show the ability of the presented approach to bootstrap the learned behavior from a simpler system (lower-dimensional action-space) to a more complex robot (comparatively higher-dimensional action-space) and reach better performance faster.
Quaternion Feedback Based Autonomous Control of a Quadcopter UAV with Thrust Vectoring Rotors
Jun 28, 2020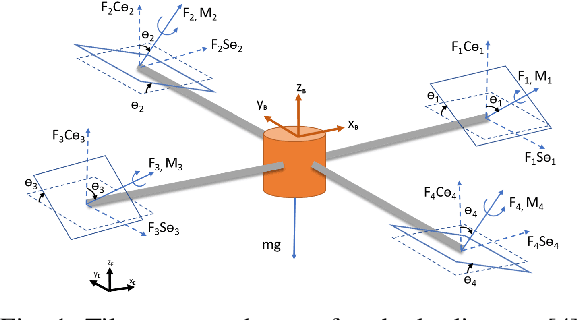

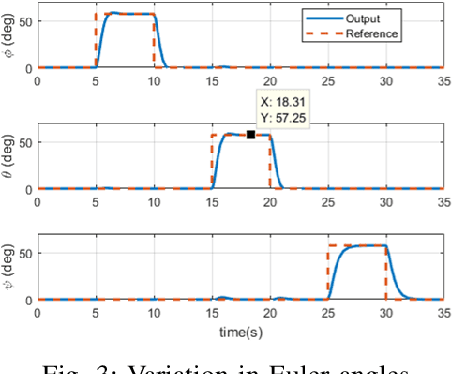
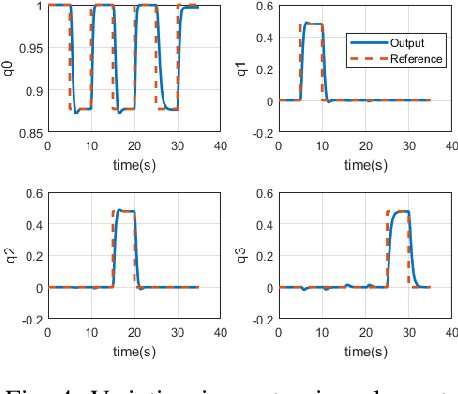
In this paper, we present an autonomous flight controller for a quadcopter with thrust vectoring capabilities. This UAV falls in the category of multirotors with tilt-motion enabled rotors. Since the vehicle considered is over-actuated in nature, the dynamics and control allocation have to be analysed carefully. Moreover, the possibility of hovering at large attitude maneuvers of this novel vehicle requires singularity-free attitude control. Hence, quaternion state feedback is utilized to compute the control commands for the UAV motors while avoiding the gimbal lock condition experienced by Euler angle based controllers. The quaternion implementation also reduces the overall complexity of state estimation due to absence of trigonometric parameters. The quadcopter dynamic model and state space is utilized to design the attitude controller and control allocation for the UAV. The control allocation, in particular, is derived by linearizing the system about hover condition. This mathematical method renders the control allocation more accurate than existing approaches. Lyapunov stability analysis of the attitude controller is shown to prove global stability. The quaternion feedback attitude controller is commanded by an outer position controller loop which generates rotor-tilt and desired quaternions commands for the system. The performance of the UAV is evaluated by numerical simulations for tracking attitude step commands and for following a way-point navigation mission.
Computer Vision Toolkit for Non-invasive Monitoring of Factory Floor Artifacts
May 12, 2020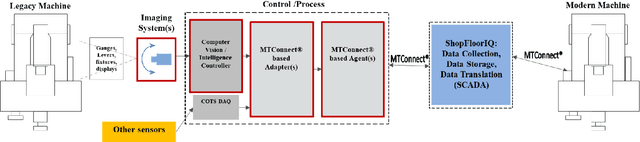
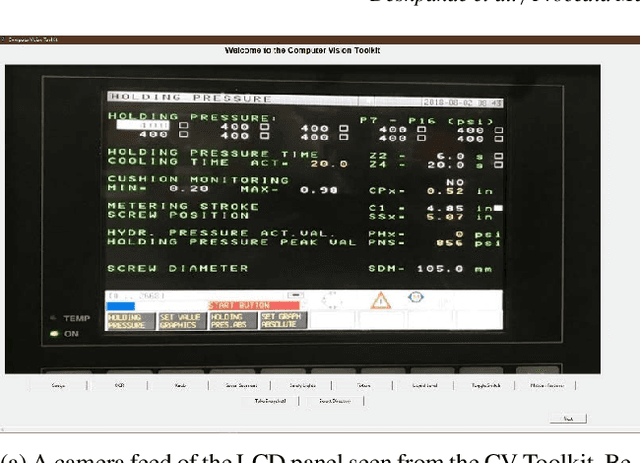


Digitization has led to smart, connected technologies be an integral part of businesses, governments and communities. For manufacturing digitization, there has been active research and development with a focus on Cloud Manufacturing (CM) and the Industrial Internet of Things (IIoT). This work presents a computer vision toolkit (CV Toolkit) for non-invasive digitization of the factory floor in line with Industry 4.0 requirements for factory data collection. Currently, technical challenges persist towards digitization of legacy systems due to the limitation for changes in their design and sensors. This novel toolkit is developed to facilitate easy integration of legacy production machinery and factory floor artifacts with the digital and smart manufacturing environment with no requirement of any physical changes in the machines. The system developed is modular, and allows real-time monitoring of production machinery. Modularity aspect allows the incorporation of new software applications in the current framework of CV Toolkit. To allow connectivity of this toolkit with manufacturing floors in a simple, deployable and cost-effective manner, the toolkit is integrated with a known manufacturing data standard, MTConnect, to "translate" the digital inputs into data streams that can be read by commercial status tracking and reporting software solutions. The proposed toolkit is demonstrated using a mock-panel environment developed in house at the University of Cincinnati to highlight its usability.
One-Shot Recognition of Manufacturing Defects in Steel Surfaces
May 12, 2020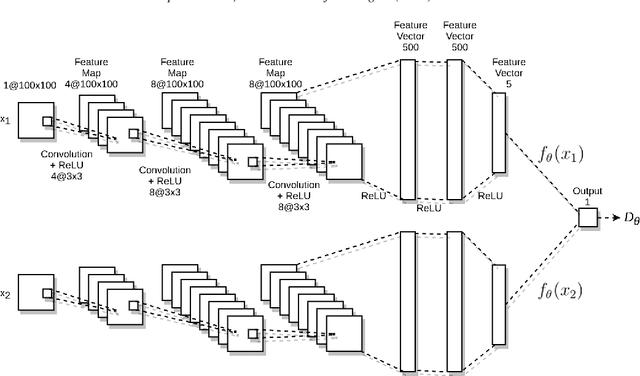
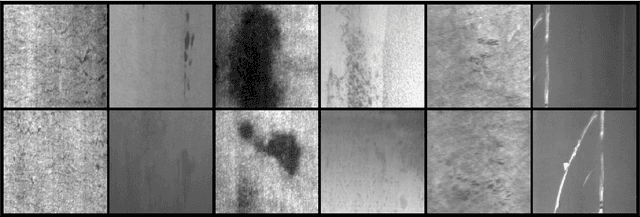

Quality control is an essential process in manufacturing to make the product defect-free as well as to meet customer needs. The automation of this process is important to maintain high quality along with the high manufacturing throughput. With recent developments in deep learning and computer vision technologies, it has become possible to detect various features from the images with near-human accuracy. However, many of these approaches are data intensive. Training and deployment of such a system on manufacturing floors may become expensive and time-consuming. The need for large amounts of training data is one of the limitations of the applicability of these approaches in real-world manufacturing systems. In this work, we propose the application of a Siamese convolutional neural network to do one-shot recognition for such a task. Our results demonstrate how one-shot learning can be used in quality control of steel by identification of defects on the steel surface. This method can significantly reduce the requirements of training data and can also be run in real-time.
Flight Control of Sliding Arm Quadcopter with Dynamic Structural Parameters
Apr 27, 2020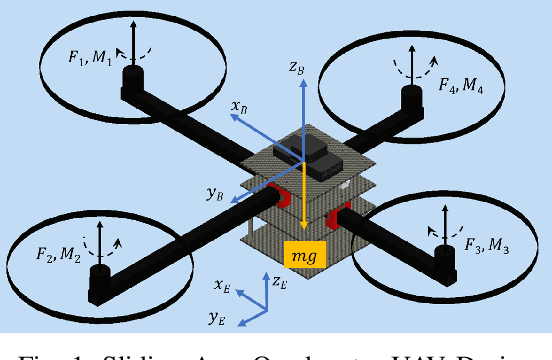
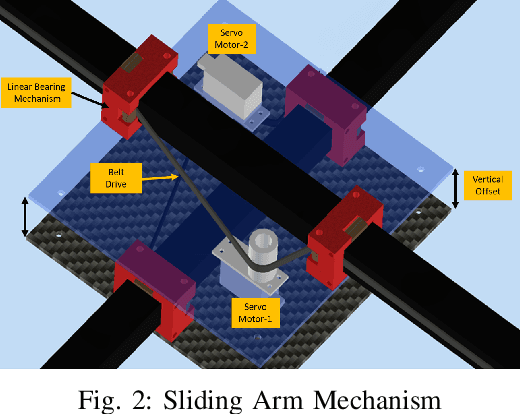
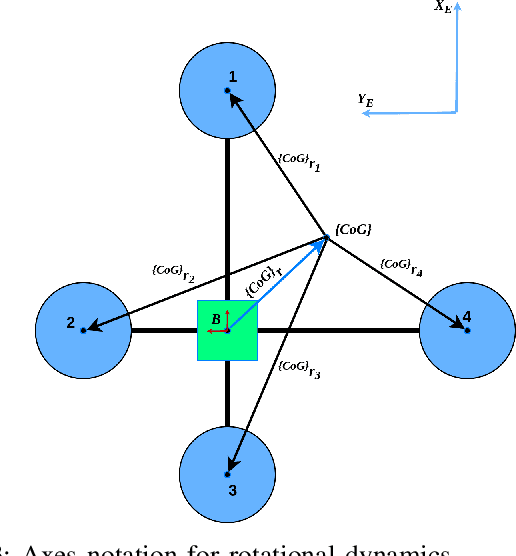
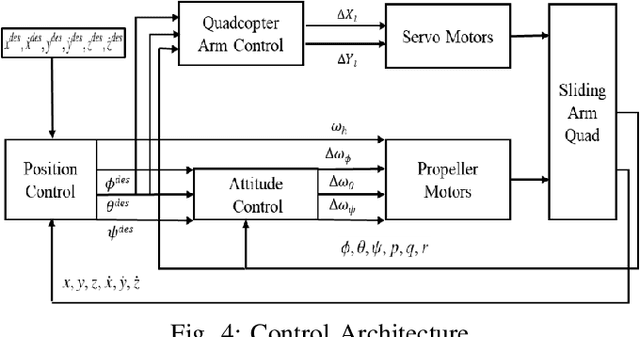
The conceptual design and flight controller of a novel kind of quadcopter are presented. This design is capable of morphing the shape of the UAV during flight to achieve position and attitude control. We consider a dynamic center of gravity (CoG) which causes continuous variation in a moment of inertia (MoI) parameters of the UAV in this design. These dynamic structural parameters play a vital role in the stability and control of the system. The length of quadcopter arms is a variable parameter, and it is actuated using attitude feedback-based control law. The MoI parameters are computed in real-time and incorporated in the equations of motion of the system. The UAV utilizes the angular motion of propellers and variable quadcopter arm lengths for position and navigation control. The movement space of the CoG is a design parameter and it is bounded by actuator limitations and stability requirements of the system. A detailed information on equations of motion, flight controller design and possible applications of this system are provided. Further, the proposed shape-changing UAV system is evaluated by comparative numerical simulations for way point navigation mission and complex trajectory tracking.