 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Reinforcement Learning for Quadcopter Control
Paper and Code
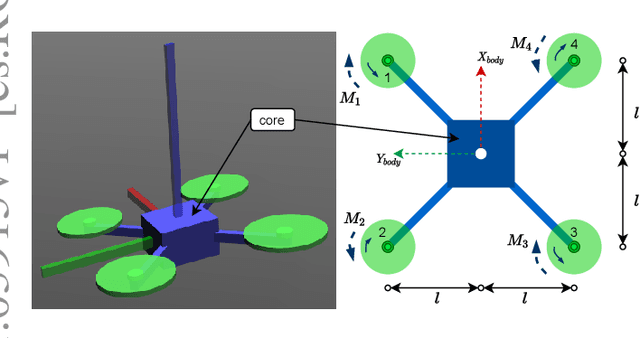

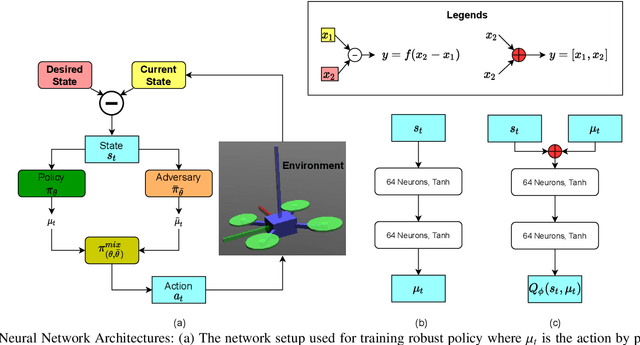
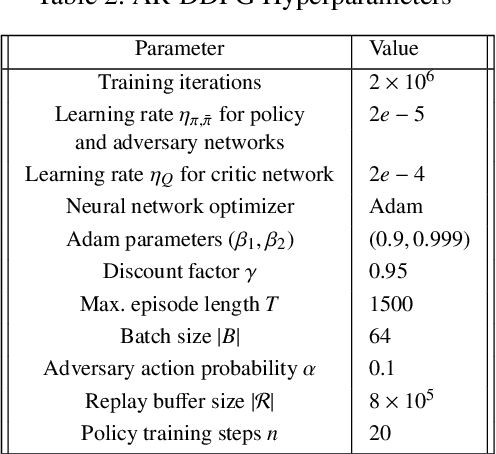
Deep reinforcement learning (RL) has made it possible to solve complex robotics problems using neural networks as function approximators. However, the policies trained on stationary environments suffer in terms of generalization when transferred from one environment to another. In this work, we use Robust Markov Decision Processes (RMDP) to train the drone control policy, which combines ideas from Robust Control and RL. It opts for pessimistic optimization to handle potential gaps between policy transfer from one environment to another. The trained control policy is tested on the task of quadcopter positional control. RL agents were trained in a MuJoCo simulator. During testing, different environment parameters (unseen during the training) were used to validate the robustness of the trained policy for transfer from one environment to another. The robust policy outperformed the standard agents in these environments, suggesting that the added robustness increases generality and can adapt to non-stationary environments. Codes: https://github.com/adipandas/gym_multirotor