 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction Space Bayesian Pseudocoreset for Bayesian Neural Networks
Oct 27, 2023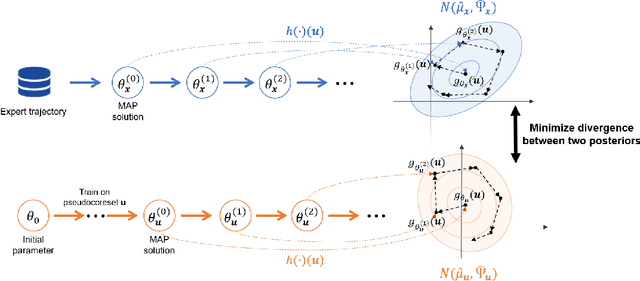
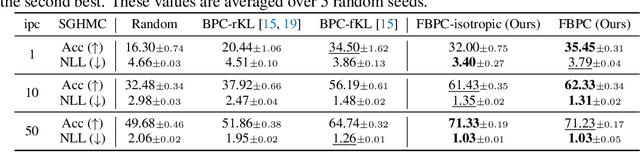
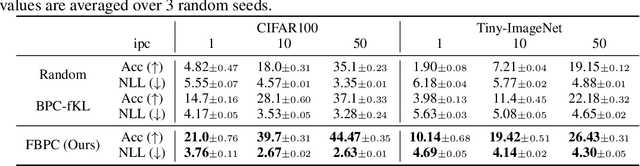
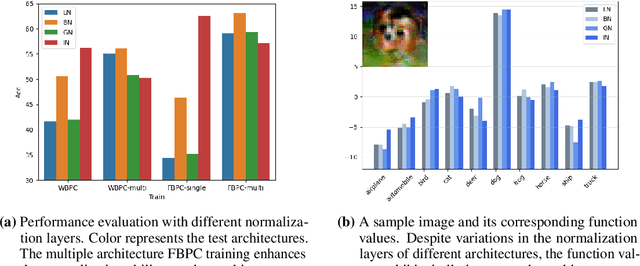
A Bayesian pseudocoreset is a compact synthetic dataset summarizing essential information of a large-scale dataset and thus can be used as a proxy dataset for scalable Bayesian inference. Typically, a Bayesian pseudocoreset is constructed by minimizing a divergence measure between the posterior conditioning on the pseudocoreset and the posterior conditioning on the full dataset. However, evaluating the divergence can be challenging, particularly for the models like deep neural networks having high-dimensional parameters. In this paper, we propose a novel Bayesian pseudocoreset construction method that operates on a function space. Unlike previous methods, which construct and match the coreset and full data posteriors in the space of model parameters (weights), our method constructs variational approximations to the coreset posterior on a function space and matches it to the full data posterior in the function space. By working directly on the function space, our method could bypass several challenges that may arise when working on a weight space, including limited scalability and multi-modality issue. Through various experiments, we demonstrate that the Bayesian pseudocoresets constructed from our method enjoys enhanced uncertainty quantification and better robustness across various model architectures.
Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models
Jul 12, 2023Large-scale image generation models, with impressive quality made possible by the vast amount of data available on the Internet, raise social concerns that these models may generate harmful or copyrighted content. The biases and harmfulness arise throughout the entire training process and are hard to completely remove, which have become significant hurdles to the safe deployment of these models. In this paper, we propose a method called SDD to prevent problematic content generation in text-to-image diffusion models. We self-distill the diffusion model to guide the noise estimate conditioned on the target removal concept to match the unconditional one. Compared to the previous methods, our method eliminates a much greater proportion of harmful content from the generated images without degrading the overall image quality. Furthermore, our method allows the removal of multiple concepts at once, whereas previous works are limited to removing a single concept at a time.
On Divergence Measures for Bayesian Pseudocoresets
Oct 12, 2022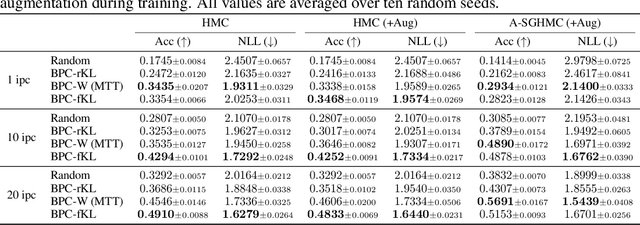
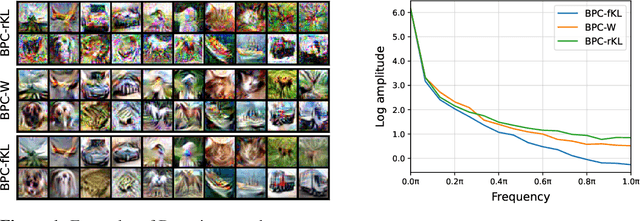

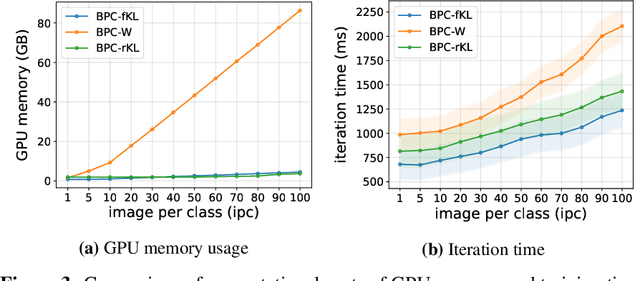
A Bayesian pseudocoreset is a small synthetic dataset for which the posterior over parameters approximates that of the original dataset. While promising, the scalability of Bayesian pseudocoresets is not yet validated in realistic problems such as image classification with deep neural networks. On the other hand, dataset distillation methods similarly construct a small dataset such that the optimization using the synthetic dataset converges to a solution with performance competitive with optimization using full data. Although dataset distillation has been empirically verified in large-scale settings, the framework is restricted to point estimates, and their adaptation to Bayesian inference has not been explored. This paper casts two representative dataset distillation algorithms as approximations to methods for constructing pseudocoresets by minimizing specific divergence measures: reverse KL divergence and Wasserstein distance. Furthermore, we provide a unifying view of such divergence measures in Bayesian pseudocoreset construction. Finally, we propose a novel Bayesian pseudocoreset algorithm based on minimizing forward KL divergence. Our empirical results demonstrate that the pseudocoresets constructed from these methods reflect the true posterior even in high-dimensional Bayesian inference problems.