 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Self-Supervised Framework using Functional Connectivity in fMRI Data
Dec 04, 2023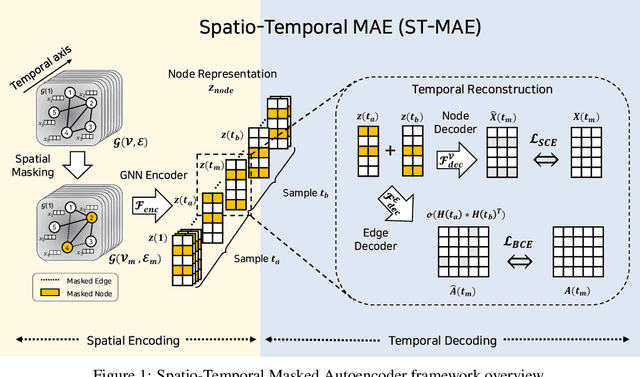
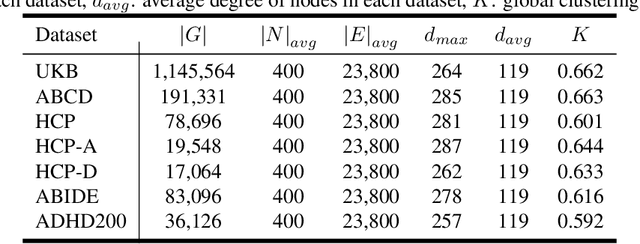
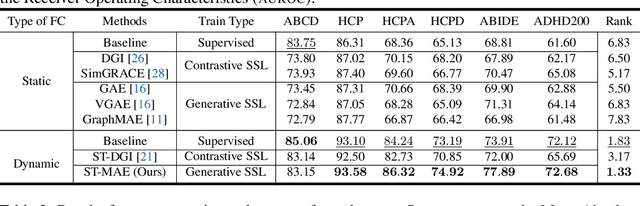
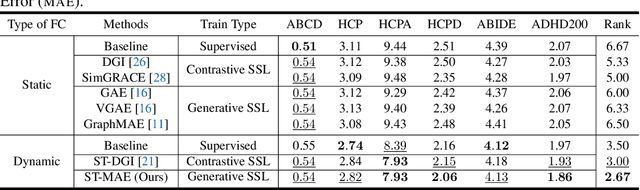
Deep neural networks trained on Functional Connectivity (FC) networks extracted from functional Magnetic Resonance Imaging (fMRI) data have gained popularity due to the increasing availability of data and advances in model architectures, including Graph Neural Network (GNN). Recent research on the application of GNN to FC suggests that exploiting the time-varying properties of the FC could significantly improve the accuracy and interpretability of the model prediction. However, the high cost of acquiring high-quality fMRI data and corresponding phenotypic labels poses a hurdle to their application in real-world settings, such that a model na\"ively trained in a supervised fashion can suffer from insufficient performance or a lack of generalization on a small number of data. In addition, most Self-Supervised Learning (SSL) approaches for GNNs to date adopt a contrastive strategy, which tends to lose appropriate semantic information when the graph structure is perturbed or does not leverage both spatial and temporal information simultaneously. In light of these challenges, we propose a generative SSL approach that is tailored to effectively harness spatio-temporal information within dynamic FC. Our empirical results, experimented with large-scale (>50,000) fMRI datasets, demonstrate that our approach learns valuable representations and enables the construction of accurate and robust models when fine-tuned for downstream tasks.
Slot-Mixup with Subsampling: A Simple Regularization for WSI Classification
Nov 29, 2023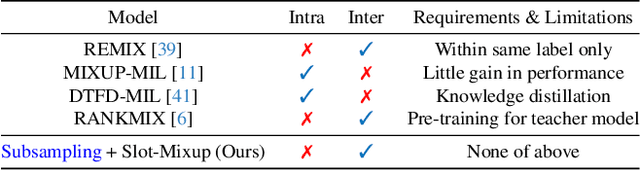
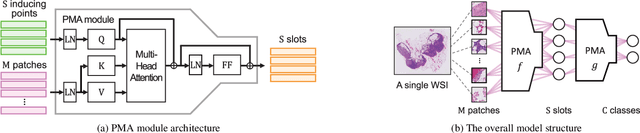
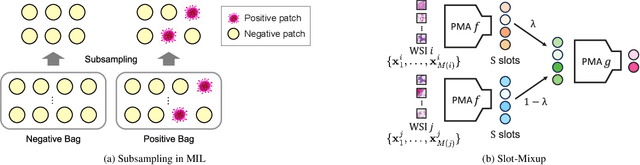
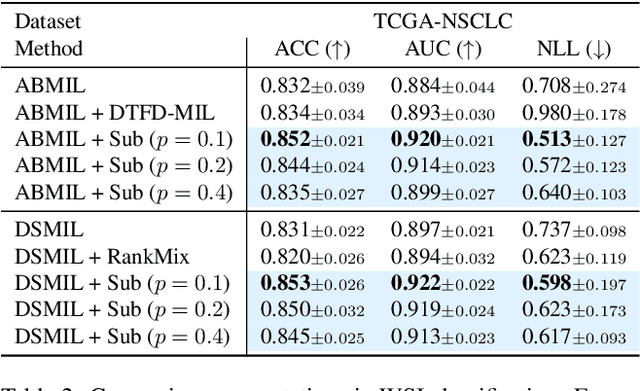
Whole slide image (WSI) classification requires repetitive zoom-in and out for pathologists, as only small portions of the slide may be relevant to detecting cancer. Due to the lack of patch-level labels, multiple instance learning (MIL) is a common practice for training a WSI classifier. One of the challenges in MIL for WSIs is the weak supervision coming only from the slide-level labels, often resulting in severe overfitting. In response, researchers have considered adopting patch-level augmentation or applying mixup augmentation, but their applicability remains unverified. Our approach augments the training dataset by sampling a subset of patches in the WSI without significantly altering the underlying semantics of the original slides. Additionally, we introduce an efficient model (Slot-MIL) that organizes patches into a fixed number of slots, the abstract representation of patches, using an attention mechanism. We empirically demonstrate that the subsampling augmentation helps to make more informative slots by restricting the over-concentration of attention and to improve interpretability. Finally, we illustrate that combining our attention-based aggregation model with subsampling and mixup, which has shown limited compatibility in existing MIL methods, can enhance both generalization and calibration. Our proposed methods achieve the state-of-the-art performance across various benchmark datasets including class imbalance and distribution shifts.