 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension Agnostic Neural Processes
Feb 28, 2025



Meta-learning aims to train models that can generalize to new tasks with limited labeled data by extracting shared features across diverse task datasets. Additionally, it accounts for prediction uncertainty during both training and evaluation, a concept known as uncertainty-aware meta-learning. Neural Process(NP) is a well-known uncertainty-aware meta-learning method that constructs implicit stochastic processes using parametric neural networks, enabling rapid adaptation to new tasks. However, existing NP methods face challenges in accommodating diverse input dimensions and learned features, limiting their broad applicability across regression tasks. To address these limitations and advance the utility of NP models as general regressors, we introduce Dimension Agnostic Neural Processes(DANP). DANP incorporates Dimension Aggregator Block(DAB) to transform input features into a fixed-dimensional space, enhancing the model's ability to handle diverse datasets. Furthermore, leveraging the Transformer architecture and latent encoding layers, DANP learns a wider range of features that are generalizable across various tasks. Through comprehensive experimentation on various synthetic and practical regression tasks, we empirically show that DANP outperforms previous NP variations, showcasing its effectiveness in overcoming the limitations of traditional NP models and its potential for broader applicability in diverse regression scenarios.
Dynamic Self-Attention : Computing Attention over Words Dynamically for Sentence Embedding
Aug 22, 2018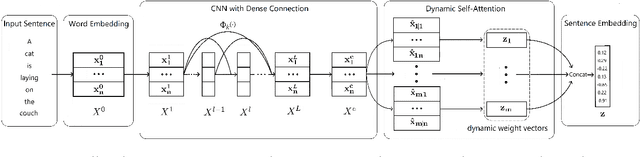
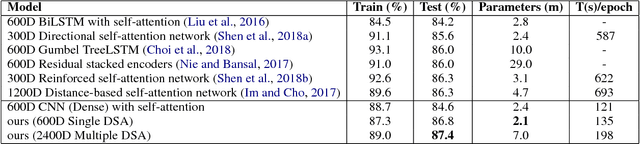

In this paper, we propose Dynamic Self-Attention (DSA), a new self-attention mechanism for sentence embedding. We design DSA by modifying dynamic routing in capsule network (Sabouretal.,2017) for natural language processing. DSA attends to informative words with a dynamic weight vector. We achieve new state-of-the-art results among sentence encoding methods in Stanford Natural Language Inference (SNLI) dataset with the least number of parameters, while showing comparative results in Stanford Sentiment Treebank (SST) dataset.