 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Co-Speech Gesture and Expressive Talking Face Generation using Diffusion with Adapters
Dec 18, 2024



Recent advances in co-speech gesture and talking head generation have been impressive, yet most methods focus on only one of the two tasks. Those that attempt to generate both often rely on separate models or network modules, increasing training complexity and ignoring the inherent relationship between face and body movements. To address the challenges, in this paper, we propose a novel model architecture that jointly generates face and body motions within a single network. This approach leverages shared weights between modalities, facilitated by adapters that enable adaptation to a common latent space. Our experiments demonstrate that the proposed framework not only maintains state-of-the-art co-speech gesture and talking head generation performance but also significantly reduces the number of parameters required.
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Sep 11, 2024



Audio-driven talking video generation has advanced significantly, but existing methods often depend on video-to-video translation techniques and traditional generative networks like GANs and they typically generate taking heads and co-speech gestures separately, leading to less coherent outputs. Furthermore, the gestures produced by these methods often appear overly smooth or subdued, lacking in diversity, and many gesture-centric approaches do not integrate talking head generation. To address these limitations, we introduce DiffTED, a new approach for one-shot audio-driven TED-style talking video generation from a single image. Specifically, we leverage a diffusion model to generate sequences of keypoints for a Thin-Plate Spline motion model, precisely controlling the avatar's animation while ensuring temporally coherent and diverse gestures. This innovative approach utilizes classifier-free guidance, empowering the gestures to flow naturally with the audio input without relying on pre-trained classifiers. Experiments demonstrate that DiffTED generates temporally coherent talking videos with diverse co-speech gestures.
Layered-Garment Net: Generating Multiple Implicit Garment Layers from a Single Image
Nov 22, 2022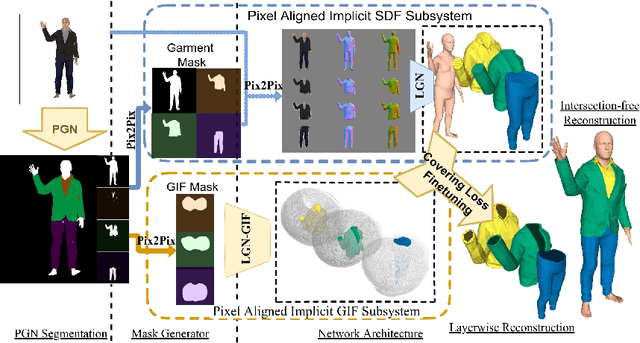

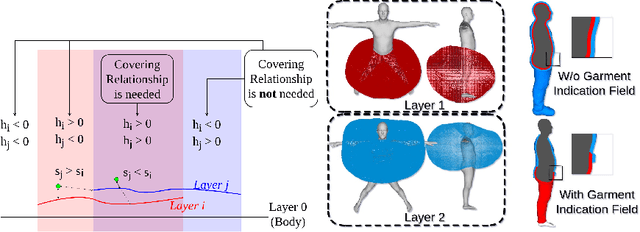
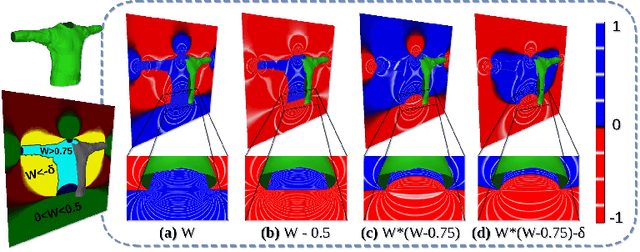
Recent research works have focused on generating human models and garments from their 2D images. However, state-of-the-art researches focus either on only a single layer of the garment on a human model or on generating multiple garment layers without any guarantee of the intersection-free geometric relationship between them. In reality, people wear multiple layers of garments in their daily life, where an inner layer of garment could be partially covered by an outer one. In this paper, we try to address this multi-layer modeling problem and propose the Layered-Garment Net (LGN) that is capable of generating intersection-free multiple layers of garments defined by implicit function fields over the body surface, given the person's near front-view image. With a special design of garment indication fields (GIF), we can enforce an implicit covering relationship between the signed distance fields (SDF) of different layers to avoid self-intersections among different garment surfaces and the human body. Experiments demonstrate the strength of our proposed LGN framework in generating multi-layer garments as compared to state-of-the-art methods. To the best of our knowledge, LGN is the first research work to generate intersection-free multiple layers of garments on the human body from a single image.