 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered-Garment Net: Generating Multiple Implicit Garment Layers from a Single Image
Nov 22, 2022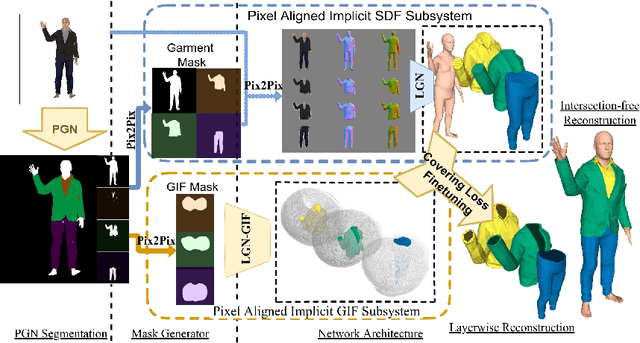

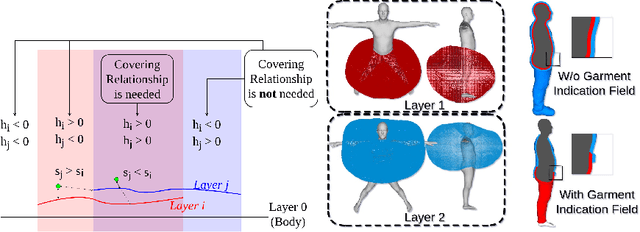
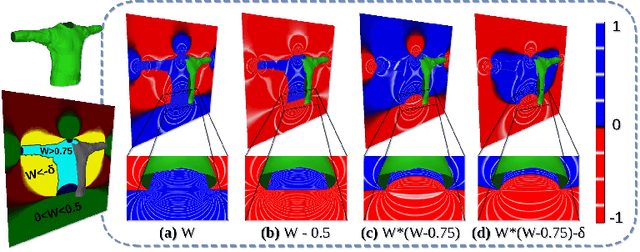
Recent research works have focused on generating human models and garments from their 2D images. However, state-of-the-art researches focus either on only a single layer of the garment on a human model or on generating multiple garment layers without any guarantee of the intersection-free geometric relationship between them. In reality, people wear multiple layers of garments in their daily life, where an inner layer of garment could be partially covered by an outer one. In this paper, we try to address this multi-layer modeling problem and propose the Layered-Garment Net (LGN) that is capable of generating intersection-free multiple layers of garments defined by implicit function fields over the body surface, given the person's near front-view image. With a special design of garment indication fields (GIF), we can enforce an implicit covering relationship between the signed distance fields (SDF) of different layers to avoid self-intersections among different garment surfaces and the human body. Experiments demonstrate the strength of our proposed LGN framework in generating multi-layer garments as compared to state-of-the-art methods. To the best of our knowledge, LGN is the first research work to generate intersection-free multiple layers of garments on the human body from a single image.
FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
Aug 18, 2021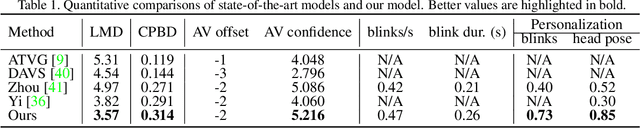
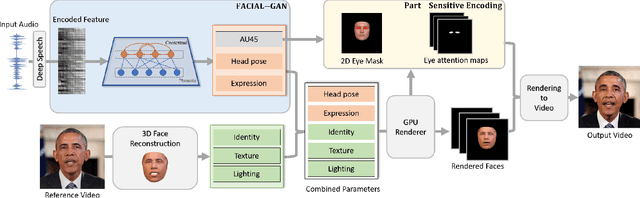
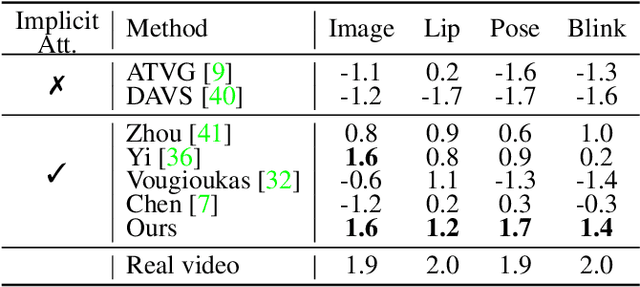
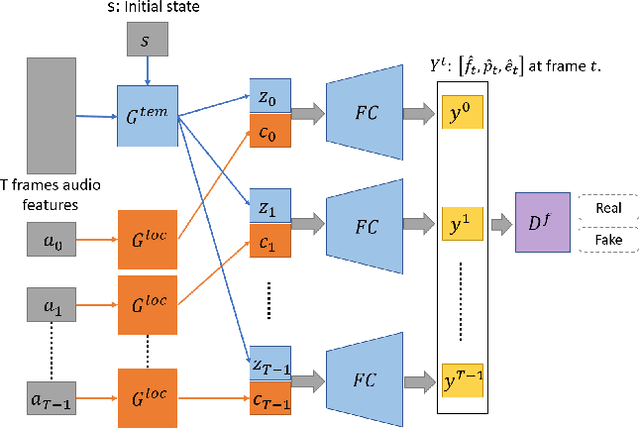
In this paper, we propose a talking face generation method that takes an audio signal as input and a short target video clip as reference, and synthesizes a photo-realistic video of the target face with natural lip motions, head poses, and eye blinks that are in-sync with the input audio signal. We note that the synthetic face attributes include not only explicit ones such as lip motions that have high correlations with speech, but also implicit ones such as head poses and eye blinks that have only weak correlation with the input audio. To model such complicated relationships among different face attributes with input audio, we propose a FACe Implicit Attribute Learning Generative Adversarial Network (FACIAL-GAN), which integrates the phonetics-aware, context-aware, and identity-aware information to synthesize the 3D face animation with realistic motions of lips, head poses, and eye blinks. Then, our Rendering-to-Video network takes the rendered face images and the attention map of eye blinks as input to generate the photo-realistic output video frames. Experimental results and user studies show our method can generate realistic talking face videos with not only synchronized lip motions, but also natural head movements and eye blinks, with better qualities than the results of state-of-the-art methods.
Dual-fisheye lens stitching for 360-degree imaging
Aug 20, 2017



Dual-fisheye lens cameras have been increasingly used for 360-degree immersive imaging. However, the limited overlapping field of views and misalignment between the two lenses give rise to visible discontinuities in the stitching boundaries. This paper introduces a novel method for dual-fisheye camera stitching that adaptively minimizes the discontinuities in the overlapping regions to generate full spherical 360-degree images. Results show that this approach can produce good quality stitched images for Samsung Gear 360 -- a dual-fisheye camera, even with hard-to-stitch objects in the stitching borders.
Projection based advanced motion model for cubic mapping for 360-degree video
Feb 21, 2017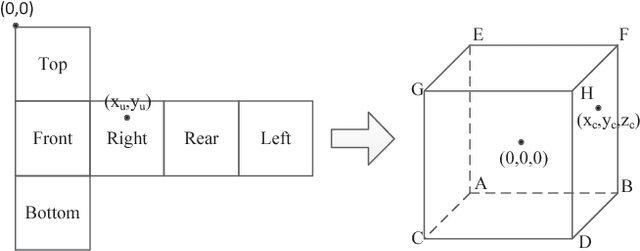



This paper proposes a novel advanced motion model to handle the irregular motion for the cubic map projection of 360-degree video. Since the irregular motion is mainly caused by the projection from the sphere to the cube map, we first try to project the pixels in both the current picture and reference picture from unfolding cube back to the sphere. Then through utilizing the characteristic that most of the motions in the sphere are uniform, we can derive the relationship between the motion vectors of various pixels in the unfold cube. The proposed advanced motion model is implemented in the High Efficiency Video Coding reference software. Experimental results demonstrate that quite obvious performance improvement can be achieved for the sequences with obvious motions.