 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: A Neurosymbolic Framework for Automated Conjecture and Reasoning in Quantum Circuit Analysis
May 11, 2026In this paper, we present SCALAR (Symbolic Conjecture and LLM-Assisted Reasoning), a neurosymbolic framework for automated conjecture generation in quantum circuit analysis built on top of the CUDA-Q open source framework. The system integrates quantum simulation, symbolic conjecture generation, and LLM-based interpretation. We evaluate SCALAR on 82 MaxCut instances from the MQLib benchmark dataset and extend the analysis to 2,000 randomly generated graphs across four topologies: regular, Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz. The framework generates conjectured bounds relating optimal QAOA parameters to graph invariants, including known relationships such as periodicity constraints on the phase separation parameter $γ$. SCALAR also recovers previously reported parameter transfer phenomena across structurally similar instances. Additionally, the system identifies correlations between graph structural features and optimization landscape properties, which we characterize through invariant-based descriptors. Using CUDA-Q tensor network simulator, we scale experiments to instances of up to 77 qubits. We discuss the accuracy, generality, and limitations of the generated conjectures, including sensitivity to graph class and quantum circuit depth.
QAOA-GPT: Efficient Generation of Adaptive and Regular Quantum Approximate Optimization Algorithm Circuits
Apr 23, 2025



Quantum computing has the potential to improve our ability to solve certain optimization problems that are computationally difficult for classical computers, by offering new algorithmic approaches that may provide speedups under specific conditions. In this work, we introduce QAOA-GPT, a generative framework that leverages Generative Pretrained Transformers (GPT) to directly synthesize quantum circuits for solving quadratic unconstrained binary optimization problems, and demonstrate it on the MaxCut problem on graphs. To diversify the training circuits and ensure their quality, we have generated a synthetic dataset using the adaptive QAOA approach, a method that incrementally builds and optimizes problem-specific circuits. The experiments conducted on a curated set of graph instances demonstrate that QAOA-GPT, generates high quality quantum circuits for new problem instances unseen in the training as well as successfully parametrizes QAOA. Our results show that using QAOA-GPT to generate quantum circuits will significantly decrease both the computational overhead of classical QAOA and adaptive approaches that often use gradient evaluation to generate the circuit and the classical optimization of the circuit parameters. Our work shows that generative AI could be a promising avenue to generate compact quantum circuits in a scalable way.
Quantum error mitigation and correction mediated by Yang-Baxter equation and artificial neural network
Jan 30, 2024Quantum computing shows great potential, but errors pose a significant challenge. This study explores new strategies for mitigating quantum errors using artificial neural networks (ANN) and the Yang-Baxter equation (YBE). Unlike traditional error correction methods, which are computationally intensive, we investigate artificial error mitigation. The manuscript introduces the basics of quantum error sources and explores the potential of using classical computation for error mitigation. The Yang-Baxter equation plays a crucial role, allowing us to compress time dynamics simulations into constant-depth circuits. By introducing controlled noise through the YBE, we enhance the dataset for error mitigation. We train an ANN model on partial data from quantum simulations, demonstrating its effectiveness in correcting errors in time-evolving quantum states.
QArchSearch: A Scalable Quantum Architecture Search Package
Oct 11, 2023



The current era of quantum computing has yielded several algorithms that promise high computational efficiency. While the algorithms are sound in theory and can provide potentially exponential speedup, there is little guidance on how to design proper quantum circuits to realize the appropriate unitary transformation to be applied to the input quantum state. In this paper, we present \texttt{QArchSearch}, an AI based quantum architecture search package with the \texttt{QTensor} library as a backend that provides a principled and automated approach to finding the best model given a task and input quantum state. We show that the search package is able to efficiently scale the search to large quantum circuits and enables the exploration of more complex models for different quantum applications. \texttt{QArchSearch} runs at scale and high efficiency on high-performance computing systems using a two-level parallelization scheme on both CPUs and GPUs, which has been demonstrated on the Polaris supercomputer.
Fundamental causal bounds of quantum random access memories
Jul 25, 2023Quantum devices should operate in adherence to quantum physics principles. Quantum random access memory (QRAM), a fundamental component of many essential quantum algorithms for tasks such as linear algebra, data search, and machine learning, is often proposed to offer $\mathcal{O}(\log N)$ circuit depth for $\mathcal{O}(N)$ data size, given $N$ qubits. However, this claim appears to breach the principle of relativity when dealing with a large number of qubits in quantum materials interacting locally. In our study we critically explore the intrinsic bounds of rapid quantum memories based on causality, employing the relativistic quantum field theory and Lieb-Robinson bounds in quantum many-body systems. In this paper, we consider a hardware-efficient QRAM design in hybrid quantum acoustic systems. Assuming clock cycle times of approximately $10^{-3}$ seconds and a lattice spacing of about 1 micrometer, we show that QRAM can accommodate up to $\mathcal{O}(10^7)$ logical qubits in 1 dimension, $\mathcal{O}(10^{15})$ to $\mathcal{O}(10^{20})$ in various 2D architectures, and $\mathcal{O}(10^{24})$ in 3 dimensions. We contend that this causality bound broadly applies to other quantum hardware systems. Our findings highlight the impact of fundamental quantum physics constraints on the long-term performance of quantum computing applications in data science and suggest potential quantum memory designs for performance enhancement.
Towards provably efficient quantum algorithms for large-scale machine-learning models
Mar 06, 2023Large machine learning models are revolutionary technologies of artificial intelligence whose bottlenecks include huge computational expenses, power, and time used both in the pre-training and fine-tuning process. In this work, we show that fault-tolerant quantum computing could possibly provide provably efficient resolutions for generic (stochastic) gradient descent algorithms, scaling as $O(T^2 \times \text{polylog}(n))$, where $n$ is the size of the models and $T$ is the number of iterations in the training, as long as the models are both sufficiently dissipative and sparse. Based on earlier efficient quantum algorithms for dissipative differential equations, we find and prove that similar algorithms work for (stochastic) gradient descent, the primary algorithm for machine learning. In practice, we benchmark instances of large machine learning models from 7 million to 103 million parameters. We find that, in the context of sparse training, a quantum enhancement is possible at the early stage of learning after model pruning, motivating a sparse parameter download and re-upload scheme. Our work shows solidly that fault-tolerant quantum algorithms could potentially contribute to most state-of-the-art, large-scale machine-learning problems.
Estimating the frame potential of large-scale quantum circuit sampling using tensor networks up to 50 qubits
May 19, 2022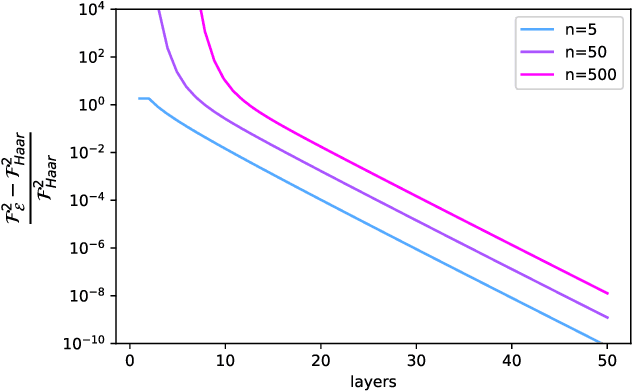
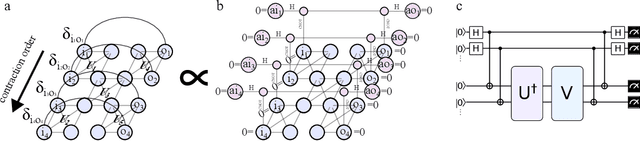

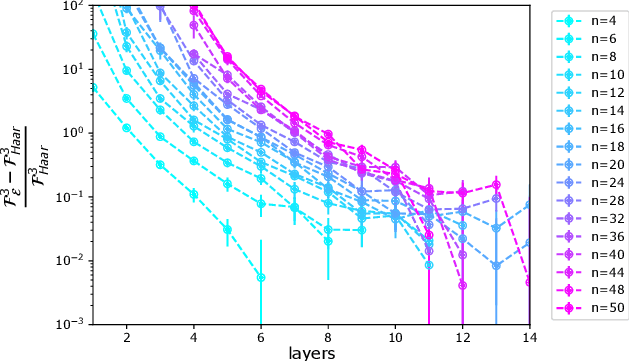
We develop numerical protocols for estimating the frame potential, the 2-norm distance between a given ensemble and the exact Haar randomness, using the \texttt{QTensor} platform. Our tensor-network-based algorithm has polynomial complexity for shallow circuits and is high performing using CPU and GPU parallelism. We apply the above methods to two problems: the Brown-Susskind conjecture, with local and parallel random circuits in terms of the Haar distance and the approximate $k$-design properties of the hardware efficient ans{\"a}tze in quantum machine learning, which induce the barren plateau problem. We estimate frame potentials with these ensembles up to 50 qubits and $k=5$, examine the Haar distance of the hardware-efficient ans{\"a}tze, and verify the Brown-Susskind conjecture numerically. Our work shows that large-scale tensor network simulations could provide important hints toward open problems in quantum information science.
Learning to Optimize Variational Quantum Circuits to Solve Combinatorial Problems
Nov 25, 2019


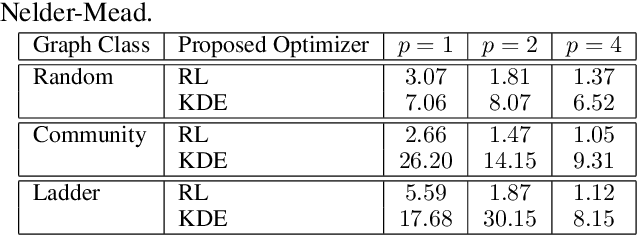
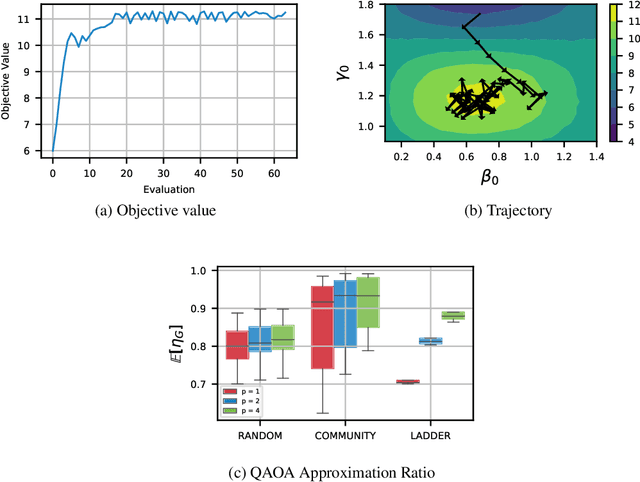
Quantum computing is a computational paradigm with the potential to outperform classical methods for a variety of problems. Proposed recently, the Quantum Approximate Optimization Algorithm (QAOA) is considered as one of the leading candidates for demonstrating quantum advantage in the near term. QAOA is a variational hybrid quantum-classical algorithm for approximately solving combinatorial optimization problems. The quality of the solution obtained by QAOA for a given problem instance depends on the performance of the classical optimizer used to optimize the variational parameters. In this paper, we formulate the problem of finding optimal QAOA parameters as a learning task in which the knowledge gained from solving training instances can be leveraged to find high-quality solutions for unseen test instances. To this end, we develop two machine-learning-based approaches. Our first approach adopts a reinforcement learning (RL) framework to learn a policy network to optimize QAOA circuits. Our second approach adopts a kernel density estimation (KDE) technique to learn a generative model of optimal QAOA parameters. In both approaches, the training procedure is performed on small-sized problem instances that can be simulated on a classical computer; yet the learned RL policy and the generative model can be used to efficiently solve larger problems. Extensive simulations using the IBM Qiskit Aer quantum circuit simulator demonstrate that our proposed RL- and KDE-based approaches reduce the optimality gap by factors up to 30.15 when compared with other commonly used off-the-shelf optimizers.
Reinforcement-Learning-Based Variational Quantum Circuits Optimization for Combinatorial Problems
Nov 11, 2019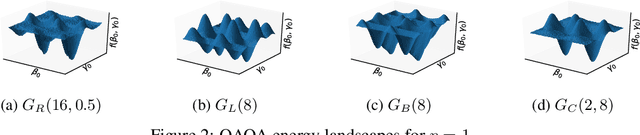
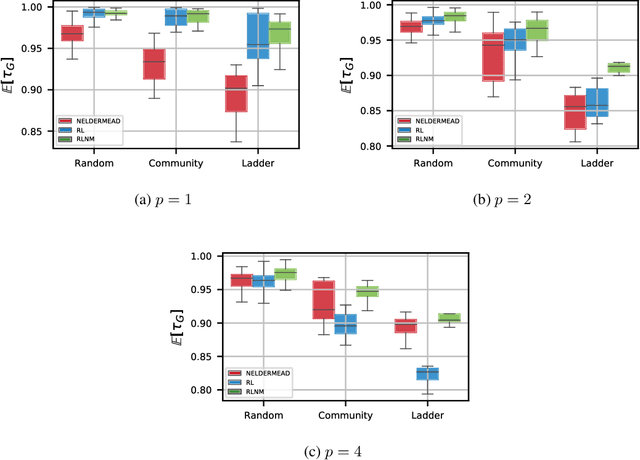
Quantum computing exploits basic quantum phenomena such as state superposition and entanglement to perform computations. The Quantum Approximate Optimization Algorithm (QAOA) is arguably one of the leading quantum algorithms that can outperform classical state-of-the-art methods in the near term. QAOA is a hybrid quantum-classical algorithm that combines a parameterized quantum state evolution with a classical optimization routine to approximately solve combinatorial problems. The quality of the solution obtained by QAOA within a fixed budget of calls to the quantum computer depends on the performance of the classical optimization routine used to optimize the variational parameters. In this work, we propose an approach based on reinforcement learning (RL) to train a policy network that can be used to quickly find high-quality variational parameters for unseen combinatorial problem instances. The RL agent is trained on small problem instances which can be simulated on a classical computer, yet the learned RL policy is generalizable and can be used to efficiently solve larger instances. Extensive simulations using the IBM Qiskit Aer quantum circuit simulator demonstrate that our trained RL policy can reduce the optimality gap by a factor up to 8.61 compared with other off-the-shelf optimizers tested.