 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement-Learning-Based Variational Quantum Circuits Optimization for Combinatorial Problems
Paper and Code
Nov 11, 2019
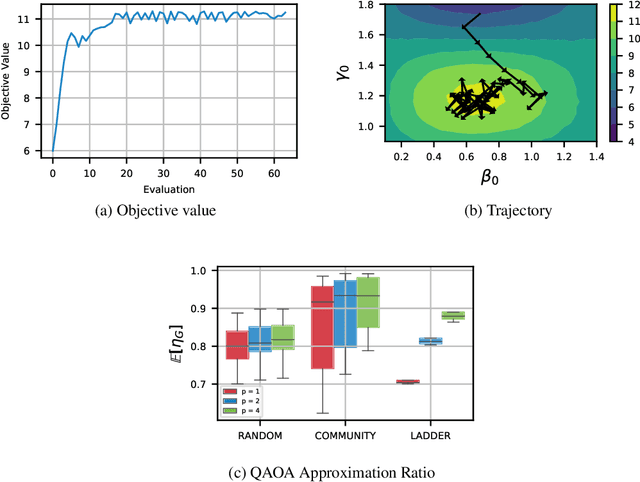
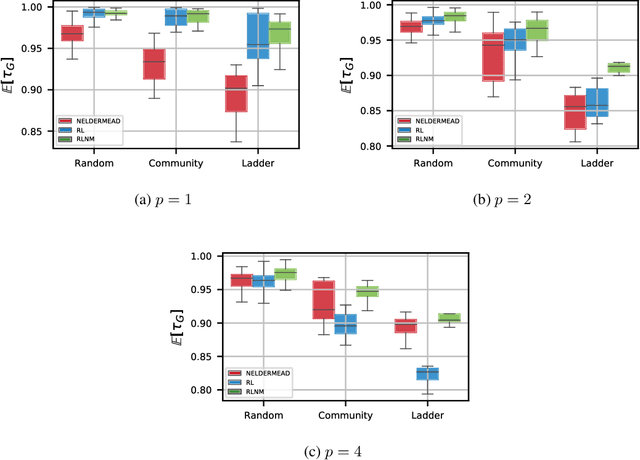
Quantum computing exploits basic quantum phenomena such as state superposition and entanglement to perform computations. The Quantum Approximate Optimization Algorithm (QAOA) is arguably one of the leading quantum algorithms that can outperform classical state-of-the-art methods in the near term. QAOA is a hybrid quantum-classical algorithm that combines a parameterized quantum state evolution with a classical optimization routine to approximately solve combinatorial problems. The quality of the solution obtained by QAOA within a fixed budget of calls to the quantum computer depends on the performance of the classical optimization routine used to optimize the variational parameters. In this work, we propose an approach based on reinforcement learning (RL) to train a policy network that can be used to quickly find high-quality variational parameters for unseen combinatorial problem instances. The RL agent is trained on small problem instances which can be simulated on a classical computer, yet the learned RL policy is generalizable and can be used to efficiently solve larger instances. Extensive simulations using the IBM Qiskit Aer quantum circuit simulator demonstrate that our trained RL policy can reduce the optimality gap by a factor up to 8.61 compared with other off-the-shelf optimizers tested.