 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind quantum machine learning with quantum bipartite correlator
Oct 19, 2023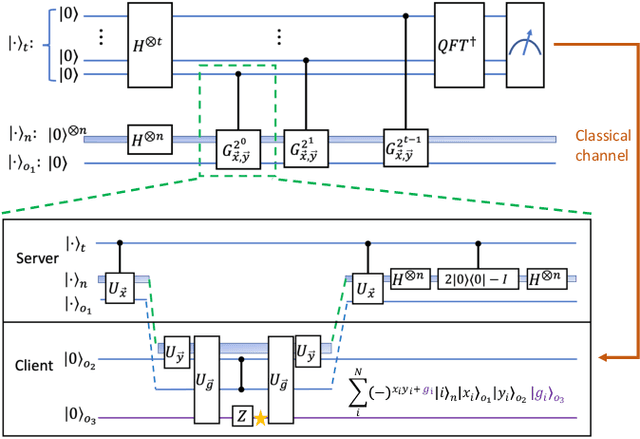
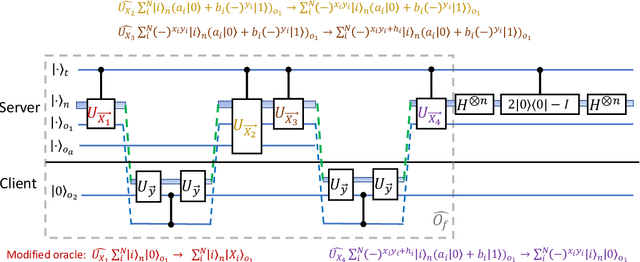
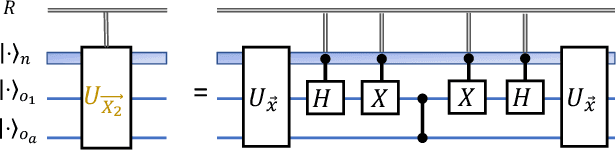
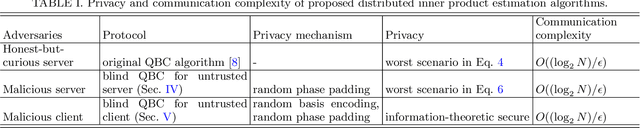
Distributed quantum computing is a promising computational paradigm for performing computations that are beyond the reach of individual quantum devices. Privacy in distributed quantum computing is critical for maintaining confidentiality and protecting the data in the presence of untrusted computing nodes. In this work, we introduce novel blind quantum machine learning protocols based on the quantum bipartite correlator algorithm. Our protocols have reduced communication overhead while preserving the privacy of data from untrusted parties. We introduce robust algorithm-specific privacy-preserving mechanisms with low computational overhead that do not require complex cryptographic techniques. We then validate the effectiveness of the proposed protocols through complexity and privacy analysis. Our findings pave the way for advancements in distributed quantum computing, opening up new possibilities for privacy-aware machine learning applications in the era of quantum technologies.
Quantum Deep Hedging
Mar 29, 2023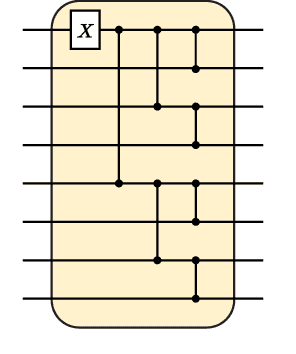
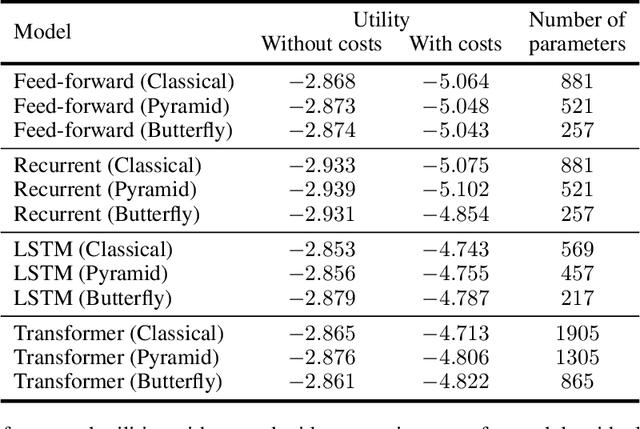
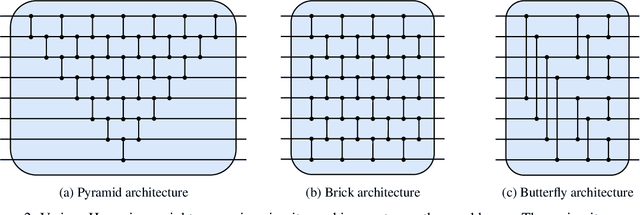
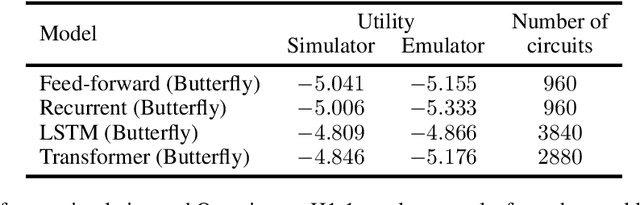
Quantum machine learning has the potential for a transformative impact across industry sectors and in particular in finance. In our work we look at the problem of hedging where deep reinforcement learning offers a powerful framework for real markets. We develop quantum reinforcement learning methods based on policy-search and distributional actor-critic algorithms that use quantum neural network architectures with orthogonal and compound layers for the policy and value functions. We prove that the quantum neural networks we use are trainable, and we perform extensive simulations that show that quantum models can reduce the number of trainable parameters while achieving comparable performance and that the distributional approach obtains better performance than other standard approaches, both classical and quantum. We successfully implement the proposed models on a trapped-ion quantum processor, utilizing circuits with up to $16$ qubits, and observe performance that agrees well with noiseless simulation. Our quantum techniques are general and can be applied to other reinforcement learning problems beyond hedging.
Numerical evidence against advantage with quantum fidelity kernels on classical data
Nov 29, 2022



Quantum machine learning techniques are commonly considered one of the most promising candidates for demonstrating practical quantum advantage. In particular, quantum kernel methods have been demonstrated to be able to learn certain classically intractable functions efficiently if the kernel is well-aligned with the target function. In the more general case, quantum kernels are known to suffer from exponential "flattening" of the spectrum as the number of qubits grows, preventing generalization and necessitating the control of the inductive bias by hyperparameters. We show that the general-purpose hyperparameter tuning techniques proposed to improve the generalization of quantum kernels lead to the kernel becoming well-approximated by a classical kernel, removing the possibility of quantum advantage. We provide extensive numerical evidence for this phenomenon utilizing multiple previously studied quantum feature maps and both synthetic and real data. Our results show that unless novel techniques are developed to control the inductive bias of quantum kernels, they are unlikely to provide a quantum advantage on classical data.
Bandwidth Enables Generalization in Quantum Kernel Models
Jun 15, 2022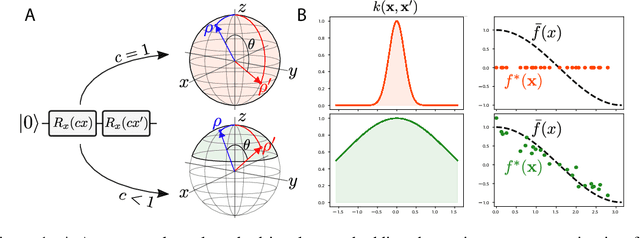

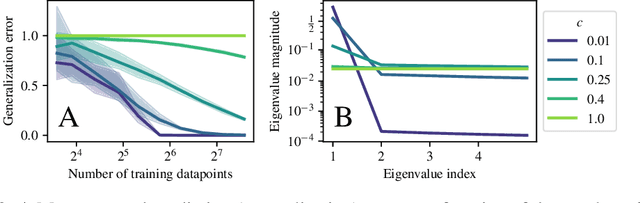
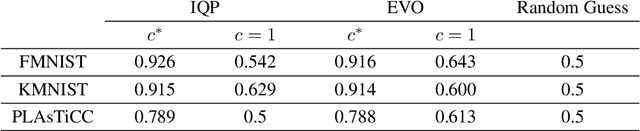
Quantum computers are known to provide speedups over classical state-of-the-art machine learning methods in some specialized settings. For example, quantum kernel methods have been shown to provide an exponential speedup on a learning version of the discrete logarithm problem. Understanding the generalization of quantum models is essential to realizing similar speedups on problems of practical interest. Recent results demonstrate that generalization is hindered by the exponential size of the quantum feature space. Although these results suggest that quantum models cannot generalize when the number of qubits is large, in this paper we show that these results rely on overly restrictive assumptions. We consider a wider class of models by varying a hyperparameter that we call quantum kernel bandwidth. We analyze the large-qubit limit and provide explicit formulas for the generalization of a quantum model that can be solved in closed form. Specifically, we show that changing the value of the bandwidth can take a model from provably not being able to generalize to any target function to good generalization for well-aligned targets. Our analysis shows how the bandwidth controls the spectrum of the kernel integral operator and thereby the inductive bias of the model. We demonstrate empirically that our theory correctly predicts how varying the bandwidth affects generalization of quantum models on challenging datasets, including those far outside our theoretical assumptions. We discuss the implications of our results for quantum advantage in machine learning.
Importance of Kernel Bandwidth in Quantum Machine Learning
Nov 16, 2021
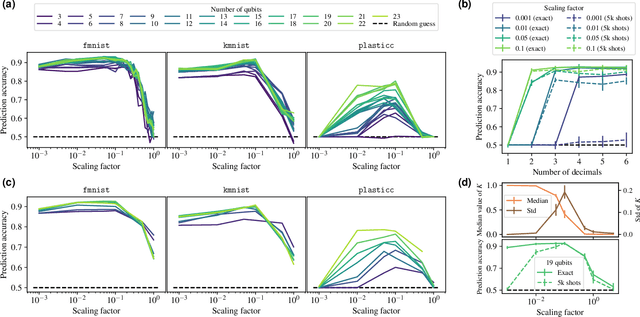
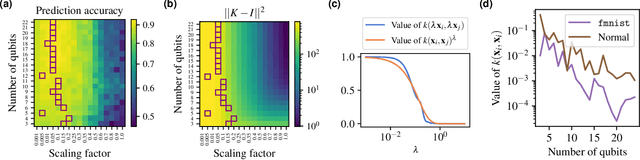
Quantum kernel methods are considered a promising avenue for applying quantum computers to machine learning problems. However, recent results overlook the central role hyperparameters play in determining the performance of machine learning methods. In this work we identify the hyperparameter controlling the bandwidth of a quantum kernel and show that it controls the expressivity of the resulting model. We use extensive numerical experiments with multiple quantum kernels and classical datasets to show consistent change in the model behavior from underfitting (bandwidth too large) to overfitting (bandwidth too small), with optimal generalization in between. We draw a connection between the bandwidth of classical and quantum kernels and show analogous behavior in both cases. Furthermore, we show that optimizing the bandwidth can help mitigate the exponential decay of kernel values with qubit count, which is the cause behind recent observations that the performance of quantum kernel methods decreases with qubit count. We reproduce these negative results and show that if the kernel bandwidth is optimized, the performance instead improves with growing qubit count and becomes competitive with the best classical methods.
Classical symmetries and QAOA
Dec 08, 2020
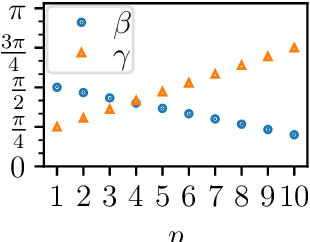
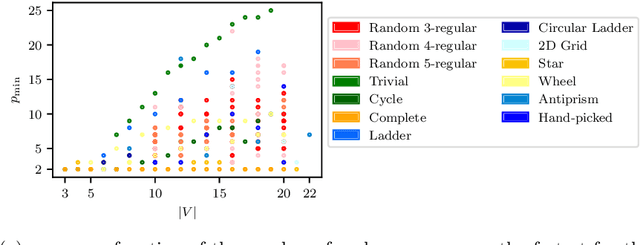
We study the relationship between the Quantum Approximate Optimization Algorithm (QAOA) and the underlying symmetries of the objective function to be optimized. Our approach formalizes the connection between quantum symmetry properties of the QAOA dynamics and the group of classical symmetries of the objective function. The connection is general and includes but is not limited to problems defined on graphs. We show a series of results exploring the connection and highlight examples of hard problem classes where a nontrivial symmetry subgroup can be obtained efficiently. In particular we show how classical objective function symmetries lead to invariant measurement outcome probabilities across states connected by such symmetries, independent of the choice of algorithm parameters or number of layers. To illustrate the power of the developed connection, we apply machine learning techniques towards predicting QAOA performance based on symmetry considerations. We provide numerical evidence that a small set of graph symmetry properties suffices to predict the minimum QAOA depth required to achieve a target approximation ratio on the MaxCut problem, in a practically important setting where QAOA parameter schedules are constrained to be linear and hence easier to optimize.
Learning to Optimize Variational Quantum Circuits to Solve Combinatorial Problems
Nov 25, 2019


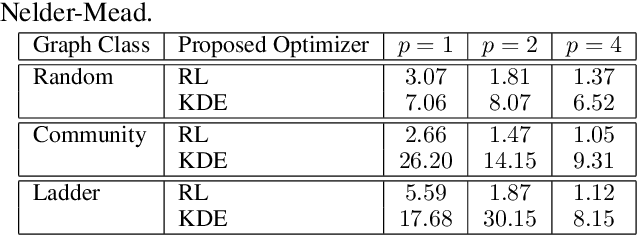
Quantum computing is a computational paradigm with the potential to outperform classical methods for a variety of problems. Proposed recently, the Quantum Approximate Optimization Algorithm (QAOA) is considered as one of the leading candidates for demonstrating quantum advantage in the near term. QAOA is a variational hybrid quantum-classical algorithm for approximately solving combinatorial optimization problems. The quality of the solution obtained by QAOA for a given problem instance depends on the performance of the classical optimizer used to optimize the variational parameters. In this paper, we formulate the problem of finding optimal QAOA parameters as a learning task in which the knowledge gained from solving training instances can be leveraged to find high-quality solutions for unseen test instances. To this end, we develop two machine-learning-based approaches. Our first approach adopts a reinforcement learning (RL) framework to learn a policy network to optimize QAOA circuits. Our second approach adopts a kernel density estimation (KDE) technique to learn a generative model of optimal QAOA parameters. In both approaches, the training procedure is performed on small-sized problem instances that can be simulated on a classical computer; yet the learned RL policy and the generative model can be used to efficiently solve larger problems. Extensive simulations using the IBM Qiskit Aer quantum circuit simulator demonstrate that our proposed RL- and KDE-based approaches reduce the optimality gap by factors up to 30.15 when compared with other commonly used off-the-shelf optimizers.
Reinforcement-Learning-Based Variational Quantum Circuits Optimization for Combinatorial Problems
Nov 11, 2019
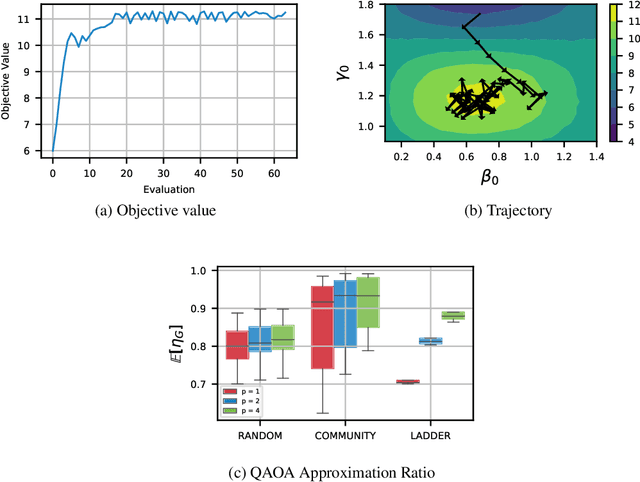
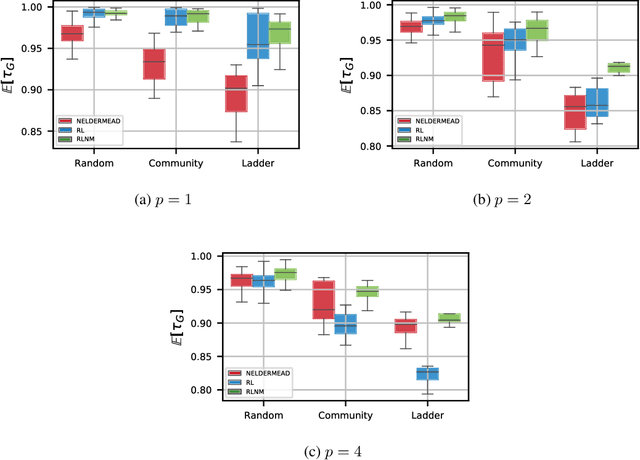
Quantum computing exploits basic quantum phenomena such as state superposition and entanglement to perform computations. The Quantum Approximate Optimization Algorithm (QAOA) is arguably one of the leading quantum algorithms that can outperform classical state-of-the-art methods in the near term. QAOA is a hybrid quantum-classical algorithm that combines a parameterized quantum state evolution with a classical optimization routine to approximately solve combinatorial problems. The quality of the solution obtained by QAOA within a fixed budget of calls to the quantum computer depends on the performance of the classical optimization routine used to optimize the variational parameters. In this work, we propose an approach based on reinforcement learning (RL) to train a policy network that can be used to quickly find high-quality variational parameters for unseen combinatorial problem instances. The RL agent is trained on small problem instances which can be simulated on a classical computer, yet the learned RL policy is generalizable and can be used to efficiently solve larger instances. Extensive simulations using the IBM Qiskit Aer quantum circuit simulator demonstrate that our trained RL policy can reduce the optimality gap by a factor up to 8.61 compared with other off-the-shelf optimizers tested.
Hypergraph Partitioning With Embeddings
Sep 16, 2019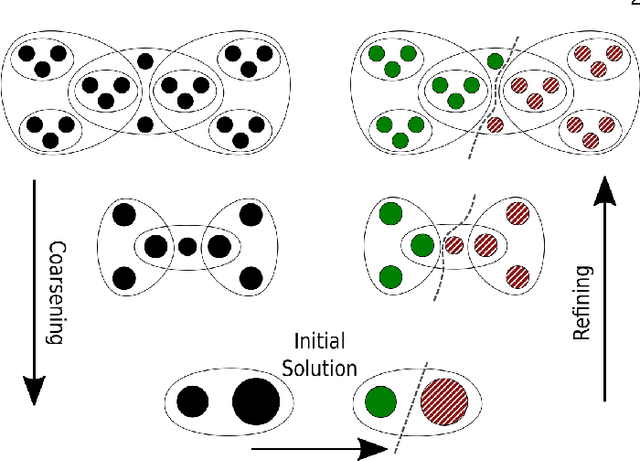

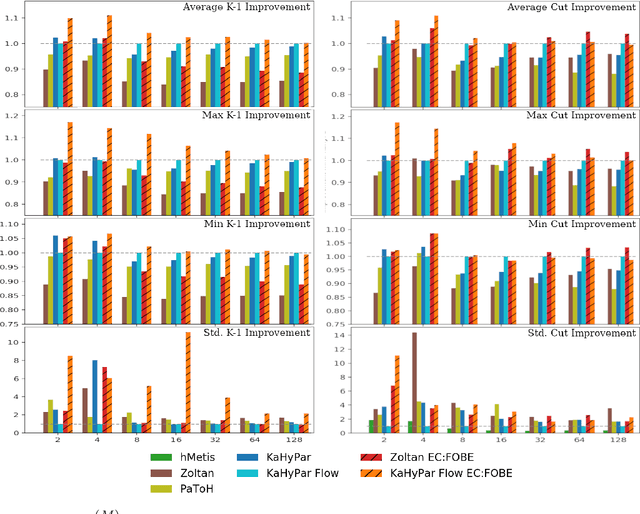
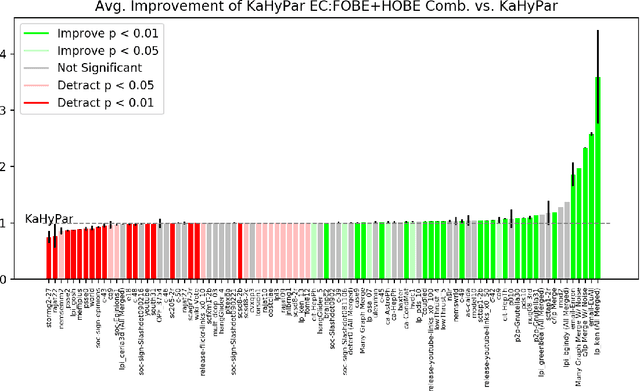
The problem of placing circuits on a chip or distributing sparse matrix operations can be modeled as the hypergraph partitioning problem. A hypergraph is a generalization of the traditional graph wherein each "hyperedge" may connect any number of nodes. Hypergraph partitioning, therefore, is the NP-Hard problem of dividing nodes into $k$ similarly sized disjoint sets while minimizing the number of hyperedges that span multiple partitions. Due to this problem's complexity, many partitioners leverage the multilevel heuristic of iteratively "coarsening" their input to a smaller approximation until an inefficient algorithm becomes feasible. The initial solution is then propagated back to the original hypergraph, which produces a reasonably accurate result provided the coarse representation preserves structural properties of the original. The multilevel hypergraph partitioners are considered today as state-of-the-art solvers that achieve an excellent quality/running time trade-off on practical large-scale instances of different types. In order to improve the quality of multilevel hypergraph partitioners, we propose leveraging graph embeddings to better capture structural properties during the coarsening process. Our approach prioritizes dense subspaces found at the embedding, and contracts nodes according to both traditional and embedding-based similarity measures. Reproducibility: All source code, plots and experimental data are available at https://sybrandt.com/2019/partition.